
语义变化检测(SCD-Semantic Change Detection)笔记02
I. 语义变化检测
语义变化检测是几年来兴起的研究方向。要求在变化检测的任务中,不仅需要知道哪里发生了变化,也需要知道发生了什么类型的变化。
从字面的意思上,比较难将语义变化和变化检测二者联系起来。但实际上,不过是将两个过程组合在一起:得到二值变化检测的change map,再得到语义分割的地表覆被图,二者进行叠加分析,就可以获得所谓的语义变化检测。
当然,如果只是这样想的话,难免将语义分割和变化检测这两个任务分离了开来。实际上,想获得更佳的结果,多时相间的信息交互是一个难点。
但毫无疑问的是,SCD是起源于CD的。多了解CD的方法,有助于SCD的进一步实现。
此外,本文采用了近几年来最为新的transformer,是一个很好的研究方向。
本文的主要安排如下。首先介绍了对语义变化检测的理解,以及其于传统二值变化检测和语义分割之间的联系,第二部分给出相关的网址,包括公开的代码、论文及其他内容,最后对提出的网络结构进行一些解释。由于只是笔记,本文只对网络部分进行一些记录,不会特别详细的查看论文。
II. 原始网址
Thanks for the data and methodology that are made public.
a. 代码地址
b. 论文地址
IGARSS 2022,是一篇会议期刊,所以版面只有四页。
c. 网络主干
截取自代码地址的README.md。
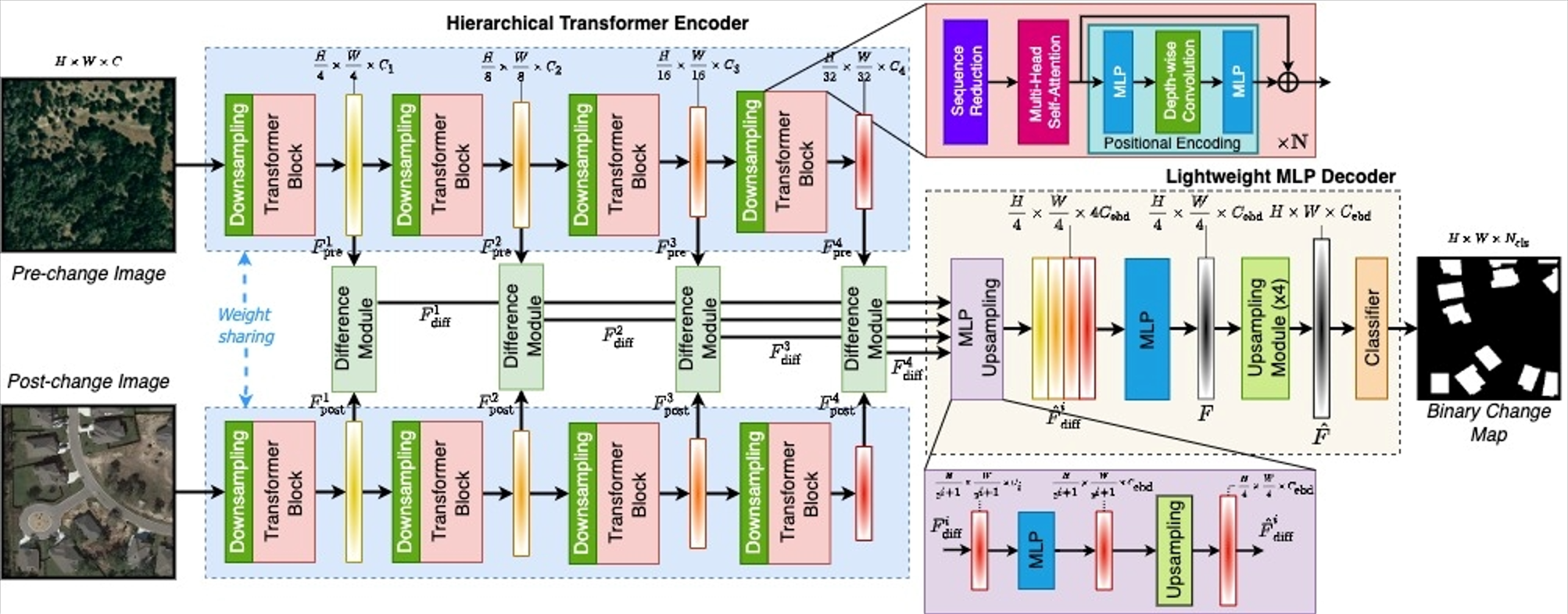
网络主干解释
本小节中首行缩进的部分,是针对原文的总结概述。一些本文的理解,都被放在类似本行的这种淡色行中(且左侧有|标志)。
_. 数据集介绍
本文采用了两个可获得的数据集。一个是建筑物变化检测的LEVIR-CD数据集(只是建筑物变化的二值map),第二个是通用变化检测的DSIFN(不同种类变化的二值map)。LEVIR-CD数据集中影像的分辨率是10241024,由于这样尺寸的图片对于显卡来说还是太大了,所以无重叠的将它们裁剪成256256大小,按照比例分成训练/验证/测试(train/val/test)三种,数量分别是7120/1024/2048。DSIFN数据集的原始大小是512*512,但比较好的是原作者创作这样的数据集的时候,已经将它们分割成了train/val/test,我们只需要按照原来的默认设定即可,只需要额外裁剪一下。他们的数量分别是14400/1360/192。
论文对数据集的介绍在很后面,但我还是想放到前面来,因为这一段很简单。
a. 文章单词缩写的了解
-
CD: 变化(C)检测(D)
Change Detection -
SOTA: 最先进的
state-of-the-art -
NLP: 自然(N)语言(L)处理(P)
Natural Language Processing -
ViT: 视觉(Vi)变压器(T)
Vision Transformer -
CE: 交叉(C)熵(E)
Cross-Entropy -
Iou: 联合交叉点
Intersection over Union
b. 文章内容简括
1) 摘要
本文提出了一种基于Transformer的孪生网络结构(transformer-based Siamese network architecture),简称为ChangeFormer,其目的是检测一对影像上的变化。不同于目前的基于全卷积神经网络的变化检测方法,论文中提出的方法是这样子的:在双支孪生神经网络中应用分层结构的transformer编码器和多层感知器的解码器,来充分解译变化检测任务中需要的多尺度、长距离的细节信息。在两个数据集上进行了实验,展示了论文提出的可训练的端到端(end-to-end)ChangeFormer架构在变化检测上表现更佳。
这一段是对摘要部分的简述。其实我对transform还没有特别深的理解……还不知道具体有什么样子的差别(与FCN相比)。我曾在BiliBili看过李沐的一个相关的视频,不过那时候我对深度学习也不是很理解,只是了解一下先进的技术,随附其视频链接:Transformer论文逐段精读
2) 引言
对变化检测的定义通常取决于应用的需要。人为造成的变化(建筑物的建、毁)、植被变化和环境发生的变化通常被视作是相关联的(即相关变化检测)。一个好的变化检测模型能很好的识别这些,而避免误识别由季节变化、建筑阴影、大气条件和成像照明影响等的非关联变化。
这是论文引言的第一段。讲解了一下变化检测的定义,并描述其并不是简单的变化了就是变化了,而是发生了性质上的改变,才叫做变化。比如由于大雪的覆盖,一块空地,在春天是棕色的裸土,可是在冬天是雪白的,这种不能叫做变化;比如在建的建筑,建到一半了和完全建成了,其实在性质上是没有发生变化的。
由于深层卷积神经网络强大的提取差异信息的能力,现有的SOTA的变化检测方法都是基于它们的。因为时间和空间上的长距离上下文关系对于多时相的相关变化检测是至关重要的,所以最新的变化检测模型的重点都是在增大感受野上。因为这个原因,堆叠卷积层、空洞卷积和注意力机制(通道注意力和空间注意力)等的网络在不断的被提出。尽管基于注意力的方法能很好的捕获全局的信息,但也很难在时空中关联长期细节,因为他们使用注意力来重新的给通过卷积神经网络在通道和空间两个维度上获得的双时相的特征分配权重。
论文中一旦出现特别长的话,我一般倾向于是国人写的……搁这考雅思呐写这么长,根本无法理解唉。本段主要就是说卷积神经网络好,但需要全局信息,所以堆叠其他结构如attention;注意力机制等好,但不能关联时空信息。所以啊,这些都太传统了,接下来我要介绍好的了。
在自然语言处理上的一系列Transformer的应用(比如non-local self-attention),推动研究者将之应用在计算机视觉领域的图像分类和图像分割等任务上,现已经有ViT、SERT、Swin和SegFormer等。这些Transformer网络和卷积神经网络相比,能获得更大的有效域,提供更加强大的上下文建模能力在任意两个像素之间。
每次读论文读到related work的时候我就很头痛,因为真的很多东西看不懂。唉,头大的,我的编码能力也只是在逐渐的学习中,真的很让人难受。
到目前为止,又说了一些大众方法的局限,也描述了一些新的方法,接下来肯定要用了。
尽管Transformer有着扩大感受野等优势,但目前还没有很多相关工作在变化检测任务上。比如有一个工作,将transformer架构用来连接卷积的编码器,保留了所有的基于卷积神经网络的特征提取部分。在本论文中,将展示:不需要卷积神经网络提取特征,一个分层transform编码器和轻量MLP解码器也能很好的工作在变化检测的任务中。
In this paper, we show that this dependency on ConvNets is not necessary, and a hierarchical transformer encoder with a lightweight MLP decoder can work very well for CD tasks.没有用翻译软件,这句话没看太懂……主要是这个编码器解码器的描述我不太能理解……但是,只要知道有这么个东西的话,其实也够了。
3) 本文方法介绍
本文提出的方法主要分成三个部分。其一:分层变压器编码器(hierarchical transformer encoder)来提取双时相图像的各种特征;其二:特征差异模块(feature difference module),计算了四个不同尺度的特征;其三:轻量多层感知机解码器(lightweight MLP decoder)来融合多尺度的特征差异和预测变化检测的掩膜。
一般论文中都会这样组织:先说一下文章提出了什么模块(其实一般都没有新的架构,都是基于Unet或者孪生神经网络这样的架构),简单介绍一下他们的功能,随后会详细的对他们进行介绍。
将这些自己设计的模块插入进去,然后得出比什么都没加的网络要好的结果就算成功,然后就能发表论文了。不过本文单纯的只使用transformer的话,也算是一个创新吧,反正我以后估计就是乱插模块了,唉。实在没什么创新能力。
分层变压器编码器。将双时相的影像作为输入,传入到分层变压器编码器中,会得到卷积神经网络那种类似的输出:变化检测需要的多尺度的高分辨率的粗糙特征和低分辨率的精细特征。在这里以一个3通道高H宽W的图片作为实例,变压器编码器的特征输出图的分辨率是这样子的:

C是Channel的缩写,会发现,分母将i=1,2,3,4代入后可以发现H和W会逐渐缩小为原来的1/4、1/8、1/16、1/32,而在高宽两个尺寸逐渐缩小的同时,维度却在逐渐的变大(这是Unet型网络的特点),维度变大后需要经过特征差异模块获得特征差异图,最后会经由多层感知器解码器来获得最后的变化检测结果。但在分层变压器解码器部分,真正需要重视的却不是这些维度的变化,而是构建这整个部分的单个块:变压器块(Transformer Block)。主要是由自注意力模块(self-attention)搭建,但是由于其方程式计算的复杂性,很难将之应用在高分辨率的影像上。然后采取了一个举措来降低它的复杂性,使之能应用。
是我自己一个人的错觉吗?我每次看这种公式形的描述我就头大……这一段转换我一时间不太能看懂,大家自己去看原论文吧……
……各种模块的讲解,这种我都不太看的明白,呜哇,哭了,大家看原论文吧……
- Downsampling Block
- Difference Module
- MLP Decoder
- MLP & Upsampling
- Upsampling & Classification
实验的细节(Implementation details)。本文在训练模型的时候,随机的初始化权重。使用的数据增强技术包括:随机翻转、随机旋转、随机的在0.8-1.2之间重采样数据、高斯模糊、随机裁剪和随机颜色抖动。实验中采用Crossentropy Loss和AdamW优化器,设置权重衰减为0.01。学习速率初始化为0.0001,在到第200个epoch的过程中线性的衰减为0。批量的大小为16。
随机的初始化权重这种操作越来越不被最新的研究采用,大家通常采用各种骨干网络针对IMAGENET等数据集的预训练参数,这样可以加速实验的进行。
数据增强的方法倒是比较全面和普通。损失函数和优化器也比较普通,毕竟只是二值变化检测,不像SCD那样,样本间不均衡非常严重,需要优化损失函数。
采用F1、IoU和OA来评估我们的模型。
这三种都是比较常用的精读评价指标。但是我还不知道他们到底是怎么应用在神经网络中的……唉,我的coding能力实在是太差了啊啊……
与8种SOTA的方法在定量(各种评价指标)和定性(可视化图像)上比较了一下本文提出的方法,展示了本文方法的优越性。然后就要分别的介绍一下每一种方法。再之后会列一个表格来表明所有的方法再各种指标下的表现,定量、定性的展示如下:
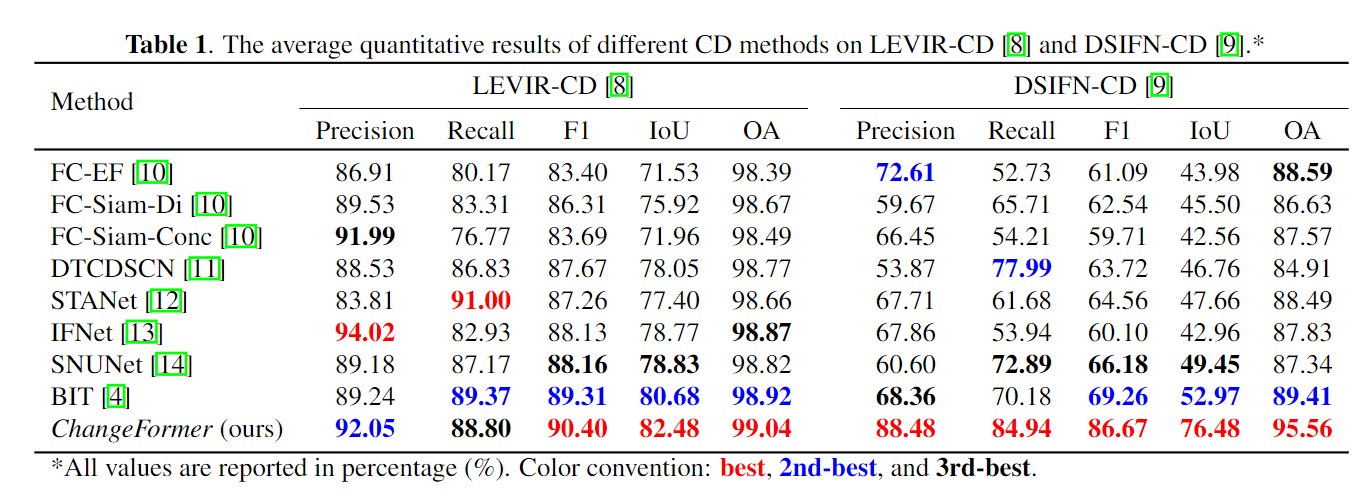

说实话我觉得8种方法的对比实在太难为人了。不过表格强调突出前三名这种措施是很好的思路。因为这可以确保一件事:本文的结果都被加粗着色的强调显示了,一种巧妙的视觉欺骗策略。
结论就是稍作总结一下而已,说本文提升的transform架构在变化检测上是很有效果的。
本文作者:小澳子
本文链接:https://www.cnblogs.com/xiaoaozi/p/16212166.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步