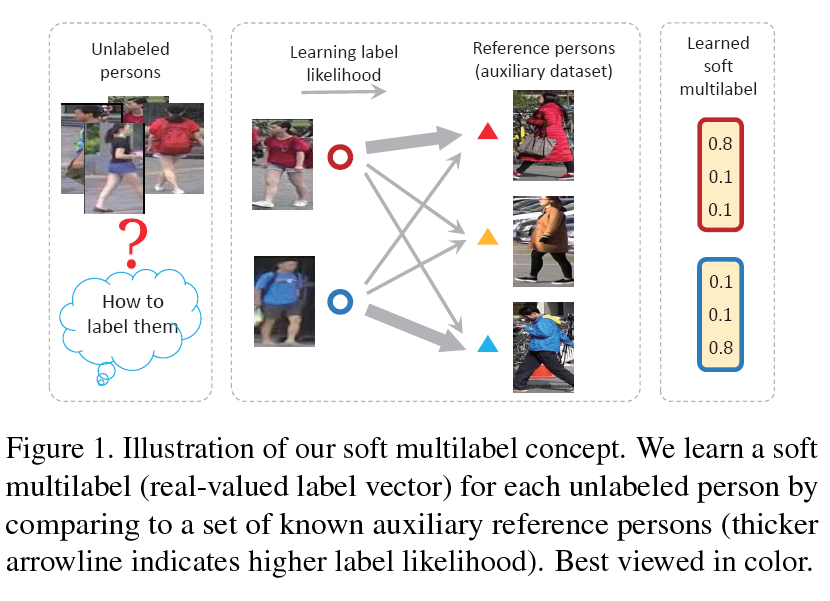
cvpr2019_Unsupervised Person Re-identification by Soft Multilabel Learning
很好的一篇文章,不愧是reid大组中山大学Weishi-Zheng老师的工作
- 文章的基本出发点很有意思:用source domain的feature做作为参考,衡量target domain images是否相似,从而构成正负样本进行contrasive learning和domain adaption。这就为target images建立了一个可以比较的参考系。
- 假定souce domain set(文章里叫agents)有$N_p$个id(实际作者用的MSMT17数据集,则$N_p=1401$),那么作者设置agents为$N_p, 2048$(2048为提取特征的维度),记为$\{a_i\}_{i=1}^{N_p}$,每个$a_i$代表一个reference person的2048维feature。无论是souce domain input image还是target input image,经过网络提取得到的特征和agents里面的特征都是经过l2 normlized,那么input feature点乘agent feature就是余弦相似性,则每个input点乘整个agents就得到一个$N_p$维的相似向量,这个相似向量经过softmax归一化就是Soft Multilabel。(注意区分我写的agent和agents)
- 网络模型如下:
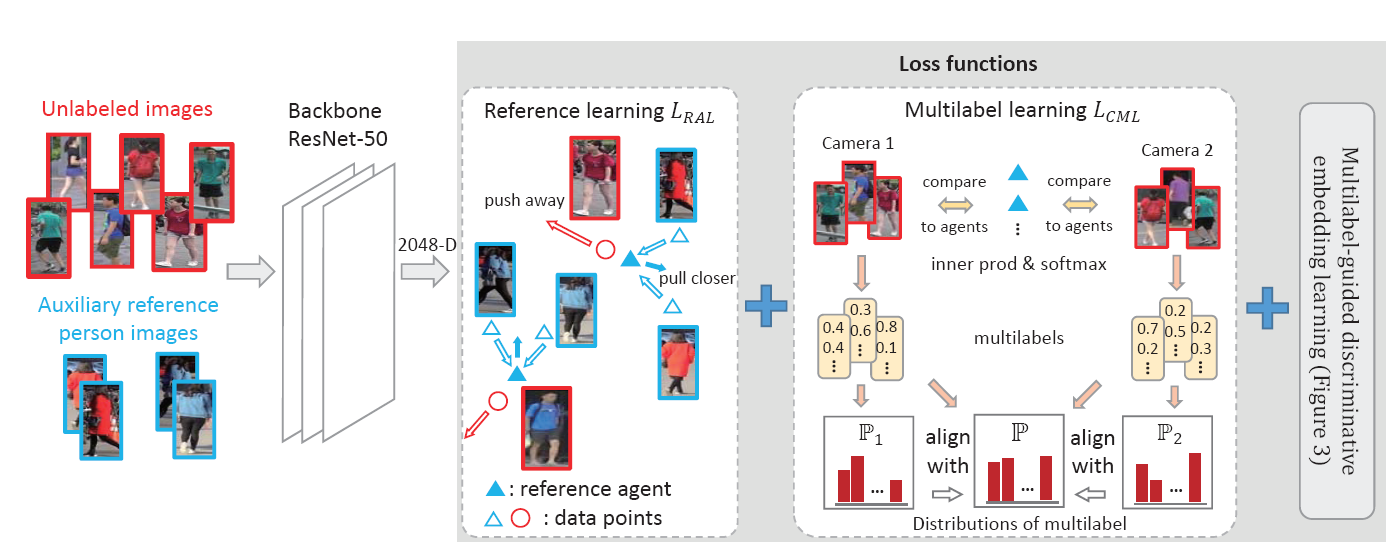
-
- 模型输入:source domain image (auxiliary image)和target domain image
- 模型输出:source feature (2048d), source similarity; target feature, target similarity (注意,此处的similarity就是feature和agents点乘后的相似性,还未经过softmax归一化)
- loss:
- ①$$L_{MDL}=-log\frac{\bar{P}}{\bar{P}+\bar{N}}$$
![]()
![]()
具体含义就是:对于一对target domain输入图像对$x_i,x_j$,提取的特征分别为$f(x_i),f(x_j)$,其本身点乘$f(x_i) \times f(x_j)$可得到相似性,作者把这个两两自身相似性大于阈值$S$的图像对称为similar pair,又因为每个input可以得到一个Soft Multilabel,两个Soft Multilabel之间的相似性(L1 distance)大于阈值$T$的positive pair,否则为hard negative pair。然后对正负样本对求$L_{MDL}$,这实际上是在target domain进行contrast learning。
- ②
![]()
- 这个loss的出现个人认为是因为每个agent代表一个id,但实际上每个id在不同camera下类间差异很大,因此要保证不同camera的相同id图像特征保持一致。
- 这里的均值和方差是Soft Multilabel的整体和各个摄像头的均值方差。由于求了softmax,Soft Multilabel可以堪称是一个分布,保证整体分布和各个摄像头的分布一致,以保证学习的特征是camera-invariant。
- v代表摄像头,实际上是求每个batch中存在的摄像头的均值和方差;整体的均值和方差是每次forward的时候进行加权更新(类似于center loss里的center更新)
- ③
![]()
- 这个loss借鉴了instance level(feature bank)那篇文章,对source domain image进行instance-level分类,只是这里的instance-level就是class-level。输入的图像用softmax crossentropy loss归类到所属的id类别中。为了保证网络学习的特征对每个agent足够区分且正确。
- ④
![]()
-
-
- 这个loss是利用trilpet loss进行domain adaption。$a_i$与target domain feature$f(x_j)$形成 负样本对,与同id的source feature$f(z_k)$形成那个样本对
-
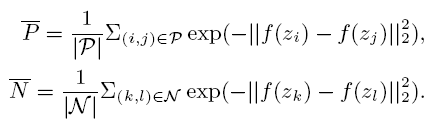
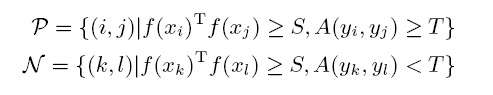

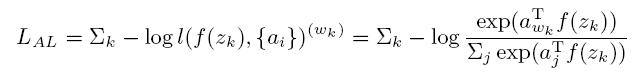
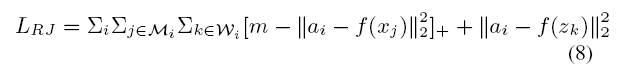
这篇文章出发点很新颖,并且每个loss设计的都有道理,值得学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号