ECCV2018_Generalizing A Person Retrieval Model Hetero- and Homogeneously
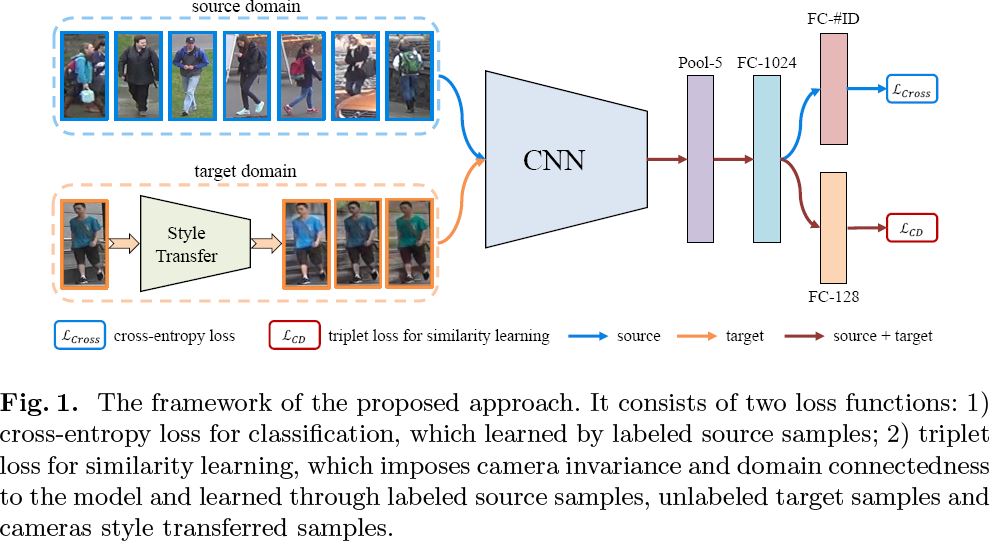
- Unsupervised Person Reid (UDA)的预设条件:
- Source domain的图像带标签(人的id)
- Target domain图像不带id标签,但是带camera的信息
- 基本思路:利用source domain和target domain进行混合训练,以进行domain adaption
a) 基本模型是supervise的经典baseline,resnet50+sofmax crossentropy loss+triplet loss,其中,sofmax crossentropy只在 source domain上做分类;triplet loss构建正负样本对体现了论文所说的Hetero- and Homogeneously:
-
-
- 首先,Target domain利用camStyle进行各个摄像头的数据增强:假定target domain有$C$个摄像头,取一张图像$x_t^i$($i$表示第i个摄像头,t代表target),再从C个摄像头的图像中各取一张进行CamStyle,进行style transfer生成fake image,记为$x_t^i(1),...x_t^i(C)$,正负样本对的构建包括:
- Camera Invariance Learning:$x_t^i$和$x_t^i(i)$形成正样本对,和其余的fake images $x_t^i(j)j \ne i$形成负样本对
- Domain Connectedness Learning:source image和另外一张source image形成正样本对,和target image形成负样本对
- 首先,Target domain利用camStyle进行各个摄像头的数据增强:假定target domain有$C$个摄像头,取一张图像$x_t^i$($i$表示第i个摄像头,t代表target),再从C个摄像头的图像中各取一张进行CamStyle,进行style transfer生成fake image,记为$x_t^i(1),...x_t^i(C)$,正负样本对的构建包括:
-
- Discussion作者的讨论很有意思
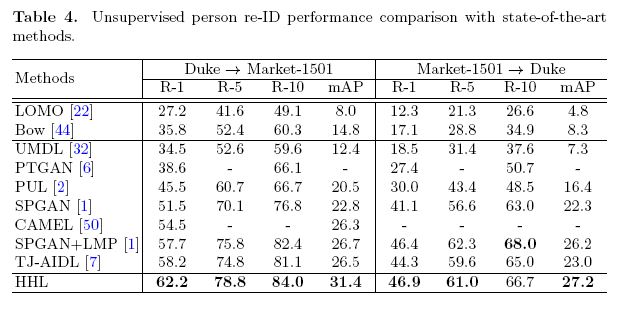
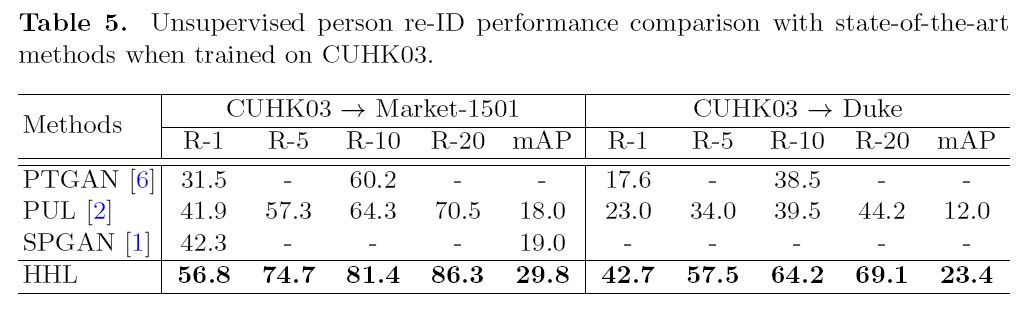
- Change of image style caused by different cameras on target set is a key infuencing factor that should be explicitly considered in person re-ID UDA.
- 为了使每个mini-batch里面样本的id都不相同,作者比较了三种采样:一是随机采样;而是先对数据做k均值分类,然后每类选一张;第三是用target的标签进行监督式的。最后发现随机采样和监督的效果近似。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号