CVPR2016_Learning Deep Feature Representations with Domain Guided Dropout for Person Re-identification
Authors:Tong Xiao, Hongsheng Li, Wanli Ouyang, Xiaogang Wang
一篇很好的文章
我水平有限,首次在person reid中看到domain
前面的文章(见整理)都是采用孪生网络或者triplet网络,计算图像之间的相似性,以此判断是否属于同一个identity。该文从分类的角度出发,每个person有一个identity,这样输入就是单张图像。
局限性在于testing set的identity必须在training set中,不能出现新的person,否则无法识别
介绍
介绍部分很清楚地讲明了“故事”。
首先在计算机视觉中,domain是指服从同一种潜在数据分布的数据集。
在计算机视觉任务中,经常有同一个任务或问题利用不同domain来完成。即标准数据集下存在数据差异大的问题。那么,multi-domain learning就有了很大的价值,原因有三:①fine-tune被很多文献证明有效,适用于不同任务的迁移;②即使如此,许多问题不能很好的用深度学习解决,因为只存在小数据集,没有海量大数据集;③multi-domain learning可以充分利用不同数据集之间的数据差异性,从而丰富训练样本的种类。
作者的基本思路:先混合了已有的数据集,设计一种CNN对混合数据集进行训练作为基本模型;再利用提出的Domain Guided dropout策略对网络进行优化训练。作者解释了Domain Guided dropout灵感来源:一个domain的神经元可能对于其他domain是无用的,比如只有在i-LIDS数据集中有带行李的行人,那么捕捉行李特征的神经元在其他domain中是没用的。Domain Guided dropout包含两个机制:a deterministic scheme, and a stochastic scheme。先训练一个基本模型;再利用deterministic domain guided dropout策略训练几个epochs使之优化(即删选神经元);再利用stochastic domain guided dropout策略继续训练使达到最优。
方法
3.1 Problem formulation
- 假定有$D$个domains,每个包含$M_i$个不同行人的$N_i$张图像。${\{(x_{i}^{(j)}, y_{i}^{(j)})\}}_{j=1}^{D}$表示所有的训练样本,其中$x_i^{(j)}$代表第$i$个domain的第$j$张图像,$y_i^{(j)} \in \{1,2,…,M_i\}$表示相应行人的identity。
- 目标是训练一个通用的特征提取器$g(\dot)$能使得同一个人的输入图像计算出的特征相似而不同人的不相似。
- 测试阶段,给定一张probe image和一组gallary images,用$g(\dot)$提取特征,再计算特征间的欧氏距离进行排序。
- 测试阶段,不同于以往的孪生网络或triplet网络,该文用分类的方法,直接判断每个图像的类别,即每个行人的identity。
3.2. Joint learning objective and the CNN structure
当混合多个数据集时,直观的想法是采用多任务的目标函数,即学习$D$个softmax分类器$f_1,f_2,…,f_D$和一个共享的特征提取器来最小化下式$$\mathop{\arg\min}_{ f_1,f_2,…,f_D} \sum_{i=1}^{D} \sum_{j=1}^{N_i} \mathbb{L} (f_i(g(x_{i}^{(j)}, y_{i}^{(j)})$$其中$\mathbb{L}$是预测概率向量和真值的交叉熵。
由于数据集之间的差异性大,所以可以直接把所有行人赋予不同的identity,即$M=\sum_{i=1}^D \ M_i$个人重新标签化以新的ID$y’ \in \{ 1,2,…,M\}$。那么就可以只用一个softmax分类器和特征提取器$g$。最小化$$\mathop{\arg\min}\_{f,g} \sum_{i=1}^{D} \sum_{j=1}^{N_i} \mathbb{L} ((f \bullet g) (x_{i}^{(j)}, {y’}_{i}^{(j)})$$作者认为这样做有两个好处:一是整个网络可以学习到domain biases,有利于区分不同的domains;第二个是当biases不够时能学习到行人相关的特征判别从而有助于决策。

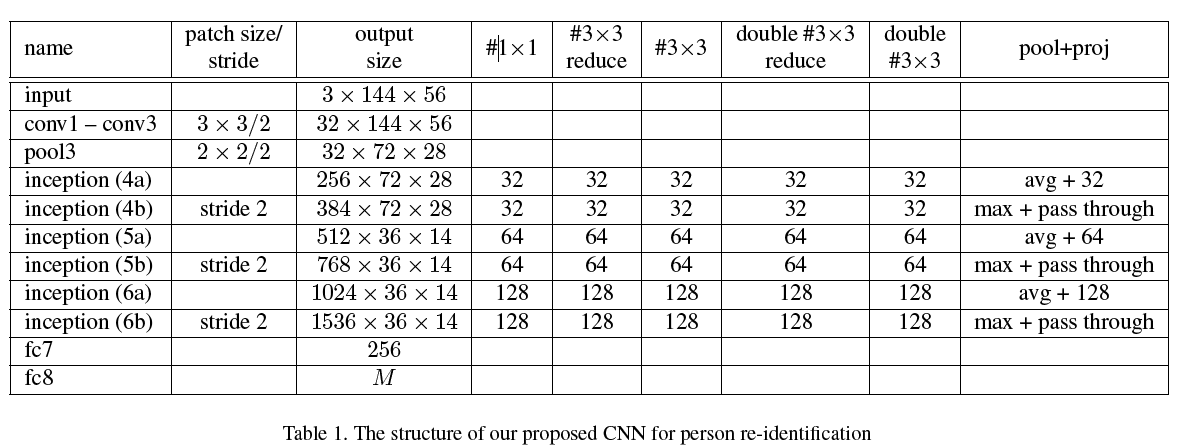
3.3. Domain Guided Dropout
这是该文章的核心点,即如何选择对不同domain有不一样作用的神经元,并在dropout步骤删选无用的神经元。
定义$g(x) \in {\mathbb{R}}^d$表示图像$x$经过CNN的$d$维特征向量。那么第$i$个神经元$(I \in \{1,2,…,d\})$的impact score定义为$$s_i=\mathbb{L}(g(x)_{\backslash i})-\mathbb{L}(g(x))$$,其中,$ g(x)_{\backslash i}$表示将第$i$个神经元设置为0之后的特征向量输出。
在对每个domain$D$,对所有样本(图像)求出$s_i$,再求平均$$ \overline{s}_i=E_{x \in D}[s_i]$$得到每个神经元的$\overline{s}_i$
当d很大时计算资源很高,因为采取二阶泰勒展开式估计$\mathbb{L}(g(x))$,有
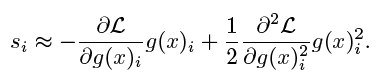
没理解泰勒展开式是怎么实现的?欢迎评论指导
获得所有的$s_i Ave$之后,按照这些impact scores来指导dropout。具体如下:
- 对于同属于某个domain的所有样本,根据impact score $s$产生一个binary mask $m$,逐个神经元乘以$m$。$m$的产生流程包含两个机制:
a) 第一个机制是deterministic,即删除所有非正impact score的神经元

即如果将某神经元的影响是增大loss或者使loss不变,那么删除这个神经元
b) 第二个机制是stochastic,即以保留下来神经元在训练中设置为0的概率,遵从伯努利分布
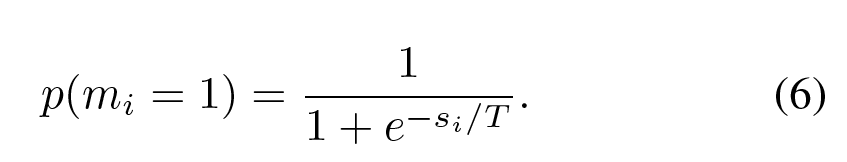
用sigmoid函数映射到(0,1),$T$控制score $s$对概率大小的影响程度。当$T \rightarrow 0$等同于deterministic机制;当$T \rightarrow \infty$时等同于标准dropout。作者实验了不同$T$的效果。
Domain Guided Dropout被应用在fc7层并继续训练超过10个epochs。
测试阶段,deterministic依然执行,stochastic机制有所变化,保留所有神经元响应,直降第$i$个神经元缩放到$1/(1+e^(-s_i/T))$
实验
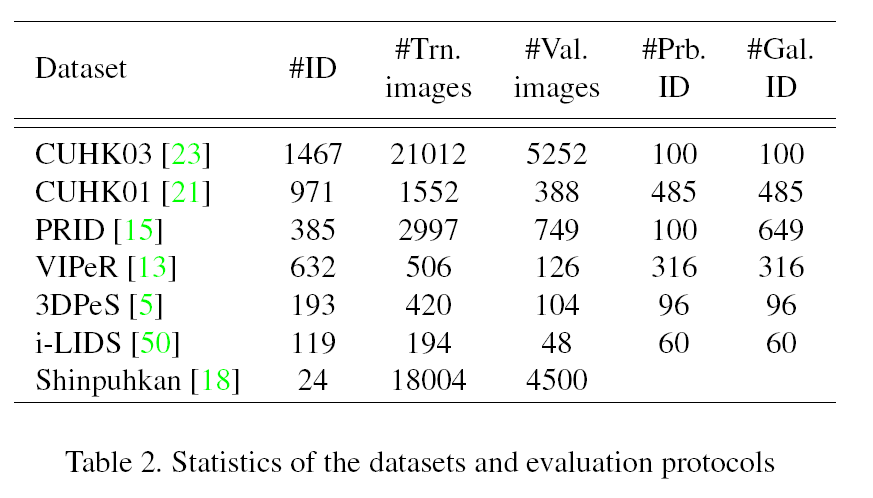
4.1 Datasets and protocols
作者在多个数据集上进行了实验
检测指标是CMC top-1 accuracy
4.2 与state-of-the-art方法比较
- Individual:作者用提出的CNN在每个数据集上分别做了训练,作为baseline
- JSTL:将所有数据集混合并从头训练CNN
- JSTL+DGD:在JSTL基础上利用提出的deterministic Domain Guided Dropout继续训练(同时对所有domain)
- FT-JSTL+DGD:进一步根据stochastic Domain Guided Dropout对网络进行fine-tune
- FT-JSTL:为了做比较,用标准dropout策略在JSTL模型上对每个数据集进行fine-tune
- CNN structure:为了检测CNN的有效性,只在CUHK03上训练。
- Joint learning:大部分数据集都有了明显提升,显然是数据更多使得模型泛化能力更强。只有CUHK03稍微下降,作者认为是将多个数据集混合在一起,大的数据集会将“牺牲”自己来帮助小数据集,使得在自己的测试集上的判别性能上有所下降。(We hypothesize that when combining different datasets together without special treatment, the larger domains would leverage their information to help the learning on the others, which makes the features more robust on different datasets but less discriminative on the larger ones themselves)
- Domain Guided Dropout:JSTL(分类问题)能够提升性能,但是Domain Guided Dropout仍能在此基础上对所有domain再提升0.5%-2.7%
- FT-JSTL+DGD:能有效提升平均3%的表现。
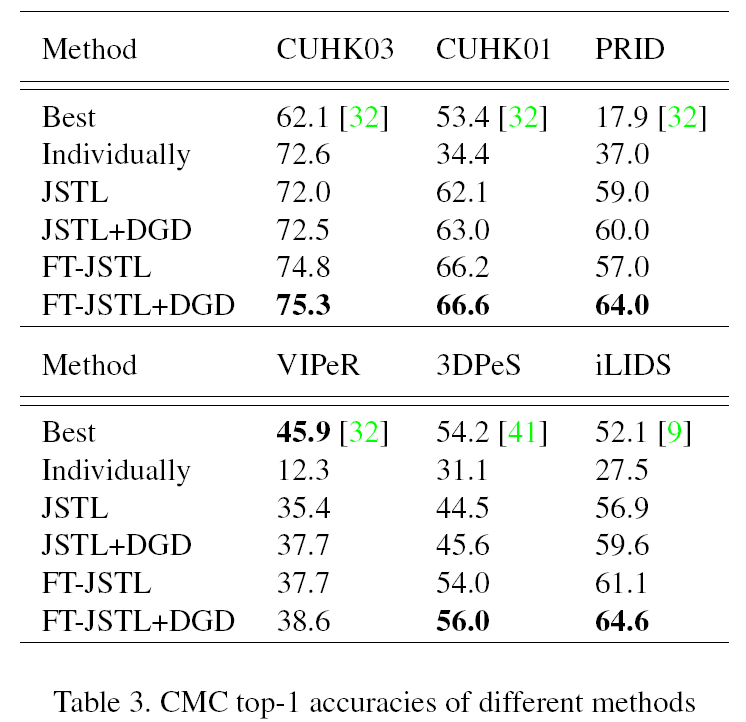
4.3. Effectiveness of Domain Guided Dropout
- Temperature T:分析了公式中的T的作用值表现
- Deterministic vs. stochastic:分析比较提出的dropout思想中两个策略的影响大小,即比较JSTL+DGD和FT-JSTL+DGD在不同数据集下CMC的指标。前者在联合训练所有domain的CNN时更有效,后者在fine-tune每个数据集时更有效。
- Standard Dropout vs. Domain Guided Dropout:比较两种dropout的效果。后者可以在模型收敛后提升performance而前者会抖动或由于过拟合降低performance。
- 比较了负神经元的数量,数据集越小这类神经元越多,所以dropout会更有效。这说明不同数据集的作用是不相等的。
附:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号