[论文阅读]CVPR2015_An Improved Deep Learning Architecture for Person Re-Identification
Title: An Improved Deep Learning Architecture for Person Re-Identification
Authors and Affiliations : Ejaz Ahmed from University of Maryland, Michael Jones and Tim K. Marks from Mitsubishi Electric Research Labs
CVPR2015
Contribution
摘要
该方法提出针对行人重识别问题同时学习特征和对应的相似性度量的方法。提出了一种为重识别问题设计的深度学习框架,输入仍然是一对图像,输出是相似性值,表示是否属于同一个人。网络结构的创新点包括可以计算交叉输入邻域差的层(a layer that computes cross-input neighborhood differences,),该层可以根据每张图的mid-level特征捕捉两张输入图像的局部关系。该层输出的high-level summary,由一层patch summary feature计算得到,然后空间上集成到后续层中。该论文的方法在大数据集CUHK03上和中等数据集CUHK01)优于当时最好的方法,并且对过拟合有一定的阻抗。该文同样指出,先在无关的大数据集上训练,随后在小目标数据集上fine-tuning,该网络通过这种策略可以在小数据集上(VIPeR)实现最优表现。
1. introduction
行人重识别定义:Person re-identification is the problem of identifying people across images that have been taken using different cameras, or across time using a single camera.要么是不同摄像头拍摄的图像,要么是同一摄像头不同时刻拍摄的图像。
网络结构中有两种新颖的层:一个是邻域差分层,比较两张图像对应的卷积特征块;另一个是随后的层,该层特征用于总结每个块的邻域差分。
2. Related Work
2.1. Overview of Previous Re-IdentificationWork
之前的工作主要集中在两方面,特征提取和度量学习。找到更好的特征(对光照。姿态和视角变化更具不变性)或者找到更好的度量(度量学习一般是从特征空间映射到新的空间,使得同一个图像对的距离更小,不同图像对的距离更大),或者二者都有。
2.2. Deep Learning for Re-Identification
3. Our Architecture
网络结构依次包括(见Figure 2):
- two layers of tied convolution with max pooling
- cross-input neighborhood differences
- patch summary features
- across-patch features
- higher-order relationships
- finally, a softmax function to yield the final estimate of whether the input images are of the same person or not.
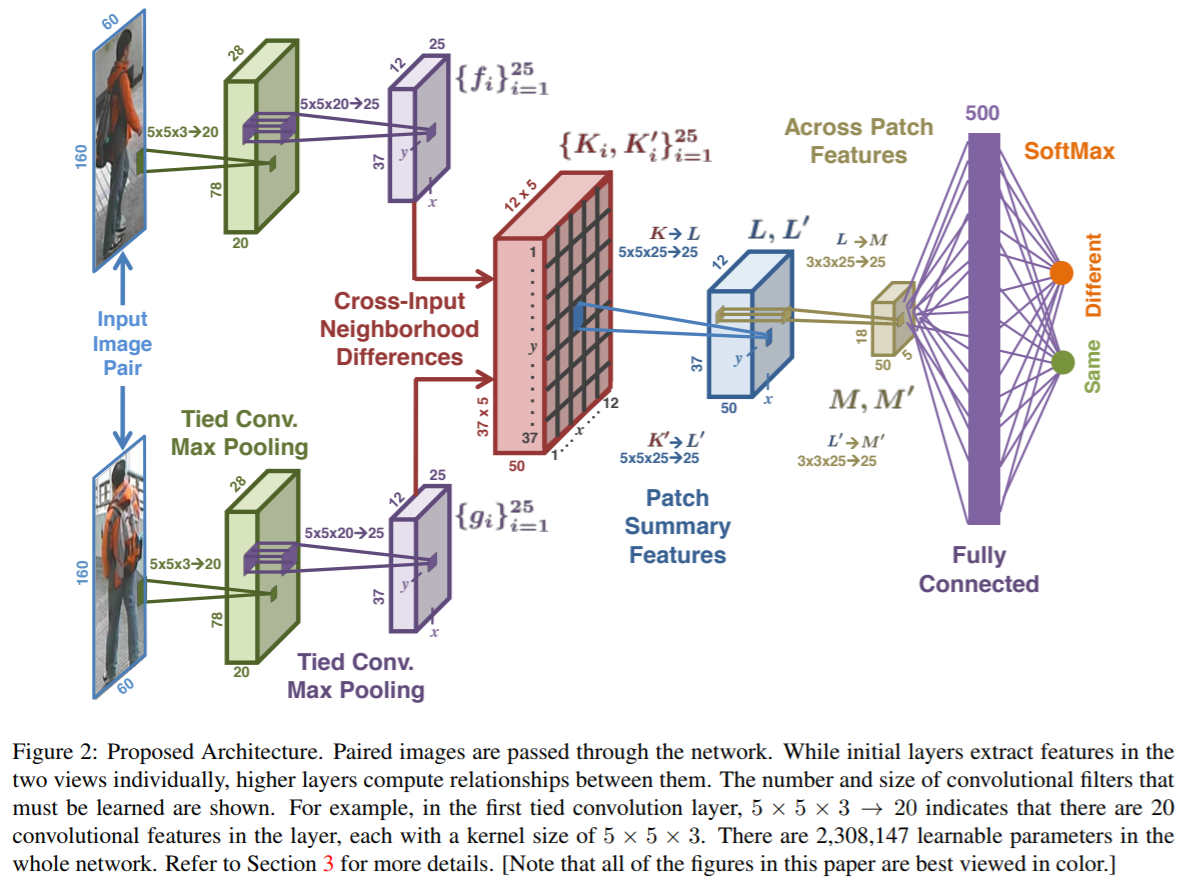
具体参数
从输入到输出依次介绍网络结构:
3.1. Tied Convolution
作者为了使得两张图像特征具有可比性,前两层(两条分支)进行特征提取时权重是共享的。输入图像尺寸是 $ 160 \times 60 \times 30 $,第一个卷积层是$20$个$ 5 \times 5 \times 3 $滤波器(输出大小为$\frac{60-5+1}{1} \times \frac{160-5+1}{1}= 56 \times 156 \times 20$),再经过2X2的maxpooling层,得到28X78X20大小。第二个卷积层(25X5X5X20)和maxpooling层(2X2),输出是12X37X25。
3.2. Cross-Input Neighborhood Differences
上述Tied Convolution输出的是两组12X37X25的feature map,分别记为$f$和$g$。两组对应维度$i$的12X37 map,用下述公式得到$K_{i}$: $$K_{i}(x,y)=f_{i} \mathcal{1}(5,5)-\mathcal{N}[g_{i}(x,y)] $$其中,减号前面是用(x,y)处$f_{i}$像素值复制成5X5的矩阵,后面是以(x,y)为中心坐标的5X5的$g_{i}$邻域值矩阵。
将f和g对调,得到$K’_{i}$,这样就得到$\{K_{i}\}_{i=1}^25$和$\{K'_{i}\}_{i=1}^25$共50维,大小都是12X37。
该50维的邻域差异图(50 neighborhood difference maps)再经过ReLU激活函层。
为什么用5X5而不直接用(x,y)的像素值是因为行人在两幅图像的position variance.
3.3. Patch Summary Features
该层的作用是对上述的邻域差异图5X5的block进行总结。从$$K\in \mathbb{R}^{12\times37\times5\times5\times25} \to L\in \mathbb{R}^{12\times37\times25}$$具体做法是用25个5X5X25的滤波器对K进行卷积操作,步长=5。
理解:实际上是K尺寸 (12X5)X(37X5)X25, K’尺寸 (12X5)X(37X5)X25,即图上的 (12X5)X(37X5)X50。卷积核尺寸是5X5X25,所以K经卷积之后得到L为(12X37X25),K’经卷积之后得到L’为(12X37X25),即图上的 (12X37X50)。注意卷积是分别卷前25维(K)和后25维(K’),不是像一般卷积直接对50维进行操作。
作者认为L在(x,y)处的25维patch summary特征向量提供了(x,y)邻域的cross-input differences的high-level summary。L和L’都经过ReLU。
3.4. Across-Patch Features
学习邻域差异的空间关系。用25个3X3X25的卷积核卷积L(步长=1)。然后再经过2X2的maxpooling。得到25维5X18的特征层M$$M\in \mathbb{R}^{5\times18\times25}$$。同样的方式处理L’得到M’。其中$ L \to M; L' \to M' $的滤波器没有捆绑(tied)。
3.5. Higher-Order Relationships
对M和M’经过全连接层(输出为500x1),然后再经过一个全连接层和softmax,输出2X1(表示两张影像是同一个人和不同人的概率)
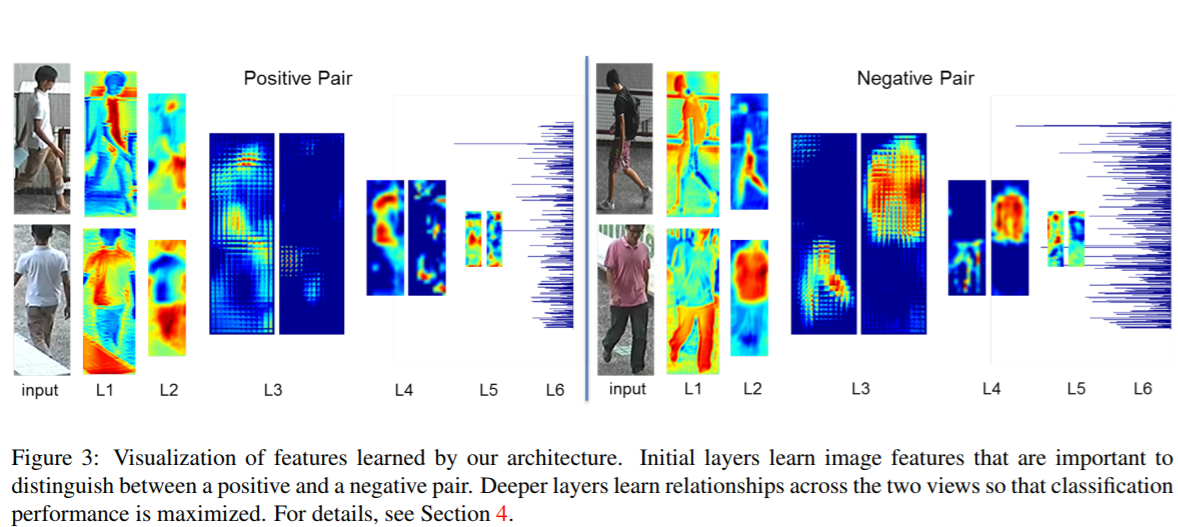
4. Visualization of Features
下图显示了L1-L6的特征层可视化结果,分为正样本(相同)和负样本(不同)。
L1:显示的是第一次经过tied convolution layer后20个维度中的某1维。正样本的特征对明亮的白色区域响应强烈,两幅图都高亮衬衣区域;负样本则对黑色区域响应强烈,view1响应衬衣而view2响应裤子。
L2:显示某一对fi和gi(第二次经过tied convolution layer)。正样本对捕捉的是棕褐色和肤色区域,对人的腿、手和脸响应高。正样本对两幅图的相似区域都有高亮;相反负样本对对不同部位做出了响应:view1中人的腿(粉色短裤和粉红色的皮肤),view2中人的躯干(粉色的上衣和粉红色的手臂)。
L3:邻域差分层并经过激活层后的特征。激活层会将所有负值映射为0。对于正样本对,理想情况下,邻域差分图应该接近于零。非零值在整个图上应该很小且相对均匀,主要是因为比较的两个特征图非常相似。L3左侧对应两幅就是这样,其中左边这幅(Ki)均匀分布,右边这幅(K’i)几乎全部为0;而对于L3右侧的负样本对图,Ki对腿响应强烈但其余部位是0,K’i只对躯干响应。
L4:类似于L3
L5:邻域差分图的高阶关系在L5中得到总结。(没看出来)
L6:第一个FC层。正负样本对的表现有很大区别。
5. Comparison with Other Deep Architectures
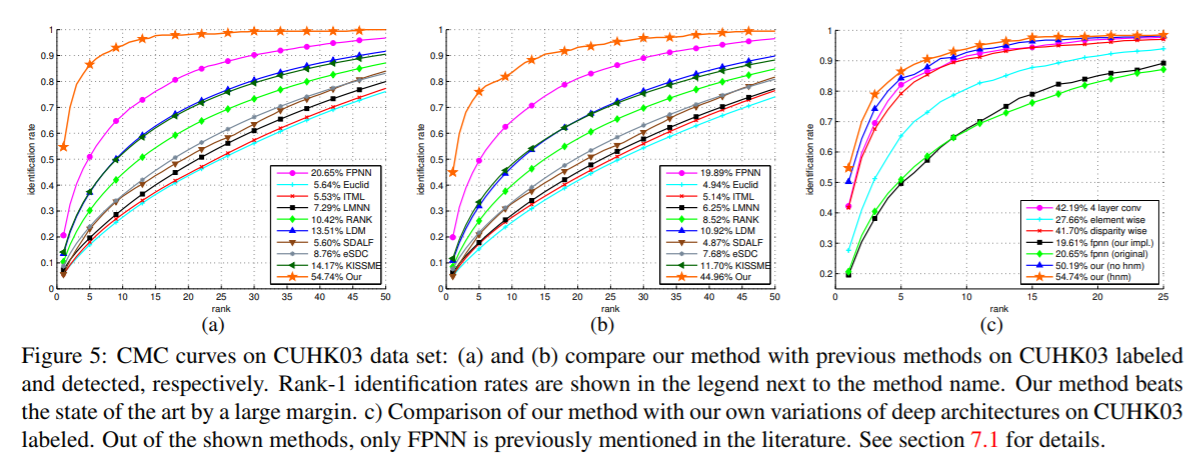
这部分工作是修改网络的部分结构以突显论文提出的网络结构的合理性。也有可能是作者在实验过程中尝试不同的组合,最后由结果推过程进行解释。
Element-wise difference: 将feature map的邻域差分改成对应的位置(单像素)差分。
Disparity-wise convolution: 该结构为了说明patch summary features的优势。将对应的50维的邻域差分图(大小为$\mathbb{R}^{12\times37\times5\times5}$),重排列(rearranged)成50个feature map,分成25组,每个feature map大小为$\mathbb{R}^{12\times37}$。(25组,每组有50张37*12?)卷积直接处理每组。后面再接FC和softmax。
Four-layer convnet: 把卷积层改成4层而非两层。
FPNN:
6. Training the Network
数据增强,Hard Negative Mining,Fine-tuning
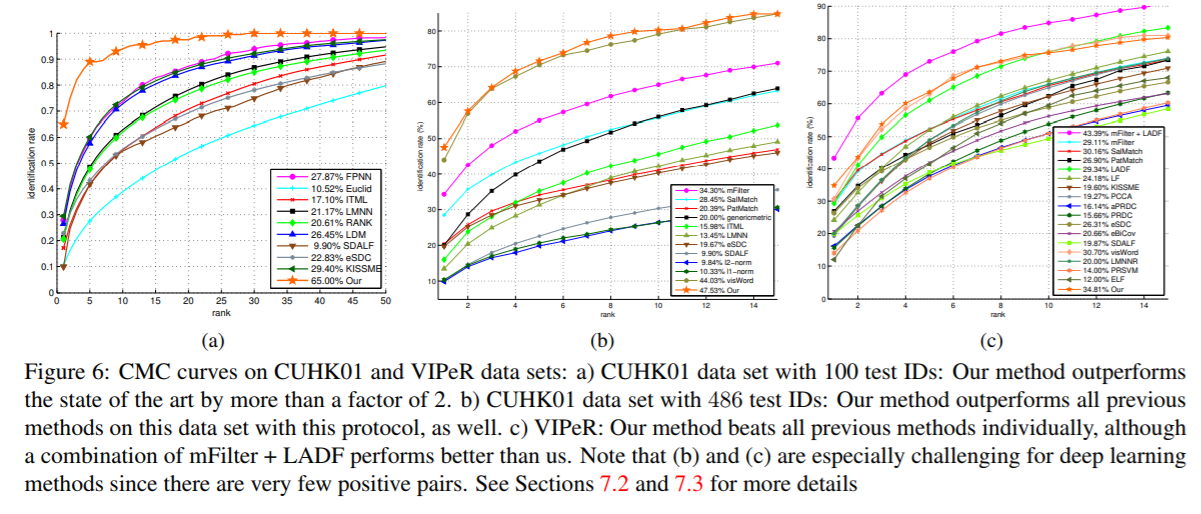
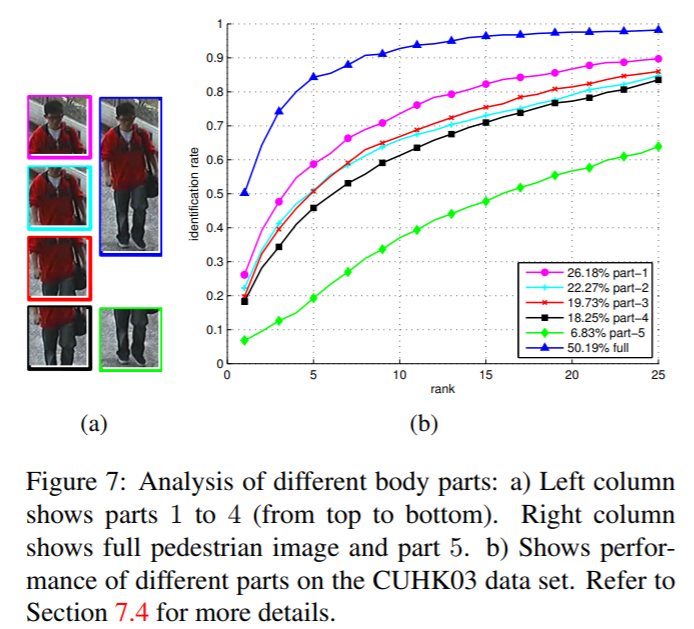
7. Experiments

 浙公网安备 33010602011771号
浙公网安备 33010602011771号