
数据库事务,事务并发问题,锁的隔离级别,锁的粒度(一)
对数据库的操作,我们经常会用到事务,但是对事务了解有多少呢,网上学习了自考本科的课程,数据库系统原理,学习了事务,然后又浏览了一些资料,对事务,事务的特性,事务并发出现的问题,以及锁,锁的级别和粒度都有了认识,根据自己个人的理解做一些总结,
事务:用户自己定义的对数据库数据的一些操作序列(多个操作组合在一起),它们要么全部执行,要么全部不执行,是不可分割的工作单位,事务中的操作一般都是对数据的更新操作,包括 增加,删除,修改。
事务的四个性质(ACID)
原子性(Atomicity):事务是不可分割的最小工作单位。
一致性(Consistency):事务的执行使得数据库从一种正确状态转换成另外一种正确状态,怎么理解这句话呢,例如一条正确状态的数据 身高170cm,体重60kg,事务T的操作就是身高增加10cm,体重增加20kg,在经过事务T执行操作之后还是一种正确的状态(能得到预期的结果,没有发生错误)既是身高180cm,体重80kg。而不是其它错误数据,因为在事务并发的时候,如果没有锁,就有可能会出现错误(下面事务并发的问题会写到)。
隔离性(Isolation):事务与事务之间是相互独立的,互不影响。如果多个事务同时访问一个数据,要做到互不影响,就要 ‘封锁’ 数据。这就涉及到了锁的级别和锁的粒度。
持续性(Durability):也称为‘永久性’,持久性,这个就比较好理解,事务正确提交之后,其结果将永远保存在数据库之中,即使在事务提交之后有了其他故障,事务的处理结果也会得到保存。
再来总结一下这四个性质(ACID),原子性最基础,是一个最基本的要求;一致性是要达到的效果,事务的操作一定要保证数据的正确。就是 数据本来是正确的,经过事务的操作,得到了错误的数据,这是绝对不允许的;隔离性是实现一致性的重要方法和手段,在事务并发的情况下,只要恰到好处的实现了隔离,才能不会出现错误,保证数据的一致性;持续性,我理解就是 事务顺利提交之后,对数据的操作就体现到了硬盘上被固化保存,这也是理所应当的事,对数据库的更新,只有真正的改变了硬盘上的数据,才是正确的修改呀。
接下来讨论一些事务并发的一些问题。
个人理解:如果在单位时间内永远只有一个事务在运行处理(假如数据库管理系统DBMS是这样控制的),那它一定就是 隔离性的,一致性的,因为一个事务运行完之后再运行下一个事务那肯定就是 相互独立,互不影响的。但是现实不可能是这样的,这效率也太低啦,肯定是不满足要求的。所以要单位时间内可以有多个事务运行,如果我们不加任何的 锁,多个事务同时操作了同一个数据,就会出现问题, 这也就有了事务并发的问题。
丢失更新
说明一下:自考的教材只统计了第二类丢失更新,但是查阅网上资料,有人统计了两类;所有都列了出来。
第一类丢失更新,
A事务撤销时,把已经提交的B事务的更新数据覆盖了。这种错误可能造成很严重的问题,通过下面的账户取款转账就可以看出来:
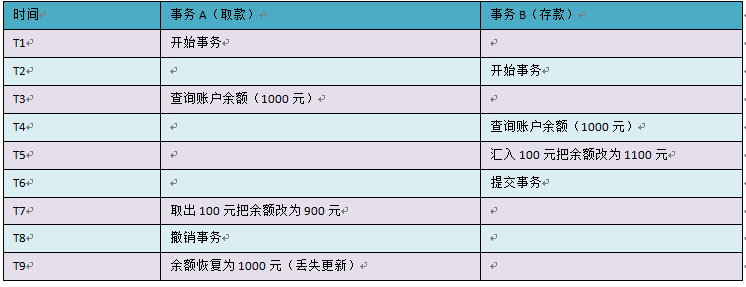
但是,在当前的四种任意隔离级别中,都不会发生该情况,不然绝对乱套,我都没提交事务只是撤销,就把别人的给覆盖了,这也太恐怖了。
第二类丢失更新,
事务T1,T2同时读入同一数据并加以修改,T2的提交结果会破坏T1提交的结果(自考教材定义)
B事务覆盖A事务已经提交的数据,造成A事务所做操作丢失(网上资料定义)。这两个定义都是一个意思
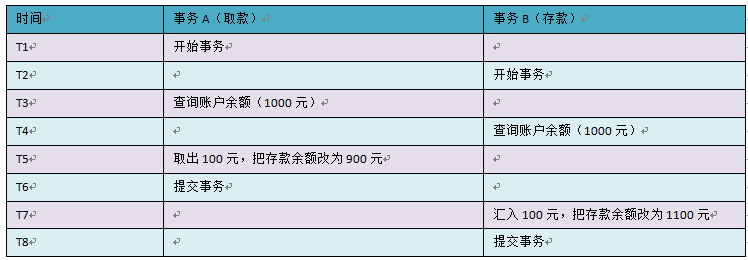
总结:这两种情况其实都是一个事务T1把另一个已经提交的事务T2的结果给修改。造成了事务T2的 丢失更新。区别就是事务T1一种是撤销,一种是正常提交。
不可重复读
事务T1读取数据后,事务T2执行更新操作,使T1无法再现前一次读取结果(自考教材定义)
事务A第一次读取数据为1000,然后事务B对数据进行了修改,事务A第二次去读取数据为0。两次数据不一样,这就是不个重复读。但是事务A每次读的数据都是正确的。如图

事务 A 其实除了查询了两次以外,其他什么事情都没有做,结果钱就从 1000 变成 0 了,这就是重复读了。可想而知,这是别人干的,不是我干的。其实这样也是合理的,毕竟事务 B 提交了事务,数据库将结果进行了持久化,所以事务 A 再次读取自然就发生了变化。这种现象基本上是可以理解的,但在有些变态的场景下却是不允许的。毕竟这种现象也是事务之间没有隔离所造成的,但我们对于这种问题,似乎可以忽略。
读“脏”数据
事务T1修改数据后撤销,使得T2读取的数据与数据库中不一致(自考教材定义)
也就是 脏读, 所谓 ‘脏’ ,也是就垃圾数据,错误数据,没用的数据。如图
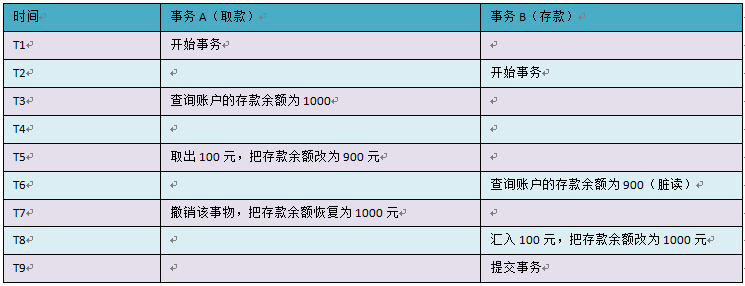
余额应该为 1100 元才对!请看 T6 时间点,事务 A 此时查询余额为 900 元,这个数据就是脏数据,它是事务 A 造成的,明显事务没有进行隔离,渗过来了,乱套了。
所以脏读这件事情是非常要不得的,一定要解决掉!让事务之间隔离起来才是硬道理。
在自考的教材上面只列出了三种情况:丢失更新,不可重复读,读“脏”数据。但是网络也列出另外一种来 ‘幻读’
幻读
我去!Phantom 这个单词不就是“幽灵、鬼魂”吗?刚看到这个单词时,真的把我的小伙伴们都给惊呆了。怪不得这里要翻译成“幻读”了,总不能翻译成“幽灵读”、“鬼魂读”吧。其实意义就是鬼在读,不是人在读,或者说搞不清楚为什么,它就变了,很晕,真的很晕。还是用一个示例来说话吧:


银行工作人员,每次统计总存款,都看到不一样的结果。不过这也确实也挺正常的,总存款增多了,肯定是这个时候有人在存钱。但是如果银行系统真的这样设计,那算是玩完了。这同样也是事务没有隔离所造成的,但对于大多数应用系统而言,这似乎也是正常的,可以理解,也是允许的。银行里那些恶心的那些系统,要求非常严密,统计的时候,甚至会将所有的其他操作给隔离开,这种隔离级别就算非常高了(估计要到 SERIALIZABLE 级别了)。
归纳一下,以上提到了事务并发所引起的跟读取数据有关的问题,各用一句话来描述一下:
1.脏读:事务 A 读取了事务 B 未提交的数据,并在这个基础上又做了其他操作。
2.不可重复读:事务 A 读取了事务 B 已提交的更改数据。
3.幻读:事务 A 读取了事务 B 已提交的新增数据。
第一条是坚决抵制的,后两条在大多数情况下可不作考虑。
上面是网上资料关于对幻读的描述,个人感觉 幻读和不可重复读 基本上是一样的,区别就是一个读取了更新数据,一个是新增数据。而且隔离级别也稍微不同。
封锁的级别
封锁的级别又称为一致性级别或隔离度,也就是我们经常说的 事务的隔离级别。
自考教材材料:
0级封锁:不重写其他非0级封锁事务的未提交的更新数据。(实用价值低),咋一听,会不理解,有点绕,可以从两个层面理解
1:可以重写其他非0级封锁事务的已提交的更新数据。这个是肯定的呀,事务已经提交了,其它事务当然可以重写。
2:可以重写其他0级封锁事务的未提交的更新数据。这种情况完全是没有任何封锁的嘛!
这两点是我个人的理解,不过老师也讲,0级封锁相对于没有封锁,没有什么使用价值。
1级封锁:不允许重写未提交的更新数据。防止了丢失更新的发生
2级封锁:既不重写也不读未提交的更新数据(防止了读脏数据)
3级封锁:不读未提交的更新数据,不写任何(包括读操作)未提交数据。
网上搜索资料:
1.READ_UNCOMMITTED
2.READ_COMMITTED
3.REPEATABLE_READ
4.SERIALIZABLE
不要去翻译,那只是一个代号而已。从上往下,级别越来越高,并发性越来越差,安全性越来越高,反之则反。

个人谈一下对隔离级别的理解:隔离级别只是一种规范,协议。在出现事务并发问题后,数据库专家就一起商量讨论,然后定义了一套规范。你达到了禁止那些问题发生,就达到了某个隔离级别。
按照我个人理解:自考教材上的 3级封锁对应 SERIALIZABLE,2级封锁对应REPEATABLE_READ,其它的我认为没有一一对应上,我认为还是以教材为准去理解。
事务的隔离级别只是专家做了一套规范,具体要靠 数据库管理系统(DBMS)来实现。
要下班了, 第一篇内容先介绍 事务和事务并发的问题。
posted on 2021-05-21 18:50 IT_xiaozhang 阅读(556) 评论(0) 编辑 收藏 举报

