

我叫Mongo,干了「索引探索篇」提升我的效率,值得您拥有
这是mongo第四篇“索引探索”,后续会连续更新4篇

mongodb的文章总结上会有一系列的文章,顺序是先学会怎么用,在学会怎么用好,戒急戒躁,循序渐进,跟着我一起来探索交流。通过上三篇的介绍,我相信大家对我在使用上已经很溜啦,但是在实际使用中还需要注重效率提升,本文章探索索引,就是为提升效率为出发点,本文的介绍顺序是:索引简介->索引原理->索引类型->索引与查询结合使用->小结,让我们一起来一步一步的探索吧。
01
索引简介
Mongodb的索引和其它关系型数据库索引很类似,索引是一个存储结构,其存储的内容是数据文档持久化的位置信息。一个数据集合和一本书来对比,那么索引就是书对应的目录,其作用就是加快查询效率。索引在加快查询效率的同时,在更新、删除、新增数据时也会影响数据变更效率,因为每一次数据变更都会更新一次索引。所以在索引使用时也需要慎重。
Mongodb索引的基本命令包括:
新增索引:createIndex({字段:排序方式},{可选参数})
删除索引:dropIndex({字段:排序方式})
查看索引:getIndexes()
先不管索引为什么能够提高查询效率,降低数据变更效率,先来一个实例。为了体现效果,这次我整的有点狠,直接初始化了300多万条数据,演示步骤如下:
数据初始化:
1 2 3 4 5 6 7 8 9 | for(var i=0;i<3000000 ;i++){ db.user.insert({ name:"我叫"+i, age:i%10, from:i%10000 })} |
// 上面的数据有一个特点age的值就10个,from的值有10000个。下面分别对两个字段加上索引,并通过实际的执行语句来看效果。
给user表的age添加一个索引(age升序) db.user.createIndex({age:1}) 给user表的from添加一个索引(from升序) db.user.createIndex({from:1})
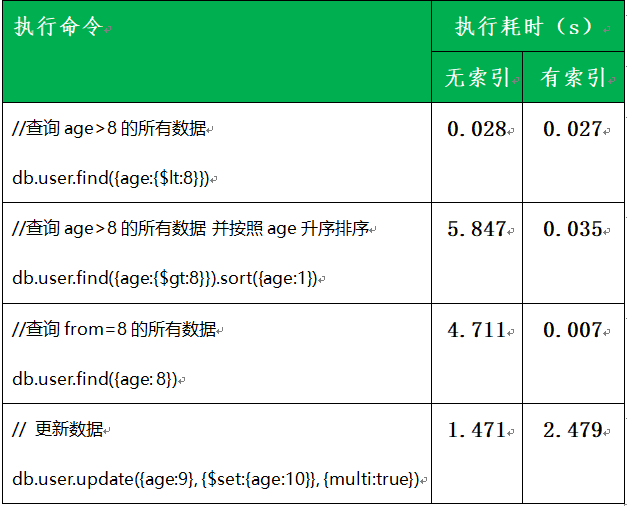
其实我们都知道索引能够提高查询效率,估计很少亲自测试一把,通过测试是不是有一种爽歪歪的感觉。根据实际操作结果我们先得出几点小小的结论:
- 当字段的值是有限的一些值时,其实有无索引对效率无影响;
- 当字段的值重复数据少时,索引的查询效率明显提高几百倍;
- 当查询结果需要排序时,有索引比没索引的效率高50倍左右;
- 当更新时,有索引的效率低于无索引;
- 所以在添加索引时针对字段值是有限的值时,就没必要添加索引,当经常需要用于排序的字段可以考虑添加索引。
以上的几个结论,也是我通过实际数据操作得出的,如果有不准确的地方,希望指点改正,谢谢!
先把结论得到这儿,下面我们在一步一步的剖析索引。
02
索引原理
Mongdb数据通过存储引擎持久化以后,其实在磁盘中就是一个一个的文件,每一个文件都对应一个位置信息。索引就是这一些文件位置信息与索引字段值的对应关系的有序数据集合,索引采用btree的结构持久化存储。在创建索引后,数据在查询的时,直接索引数据集合查询,然后在根据对于的位置信息操作对应的数据详情,避免了全表扫描,同时查询出的数据本来就是有序的数据,也避免了因为排序导致的性能损失。
这样我们就不难理解上面得出的几点结论了:因为索引查询避免了全表数据扫描,所有查询效率高;因为索引本身就已经是有序的数据,所以根据索引字段排序效率明显提高;因为索引会单击存储,一旦数据有变更,都需要同时更新索引数据,所有数据更新时有索引的效率低,同时索引也会增加额外的存储开销。
03
索引类型
MongoDB支持多种类型的索引,包括单字段索引、复合索引、多key索引、文本索引等,每种类型的索引有不同的使用场合。
单字段索引:
单字段索引其实很好理解,文章开始我们创建的实例就是单字段索引,简单的所说就是针对某一个字段创建一个索引,达到提高索引字段的查询效率。Mongdb默认_id字段创建单字段唯一索引。
1 2 3 4 5 | 格式:db.collectionName.createIndex({索引字段:1升序-1降序} ) 实例:对集合user的字段age添加升序索引 db.user.createIndex({age:1}) |
复合索引:
复合索引是针对单字段索引的升级版,复合索引就是联合多个字段创建索引,也是我们常说的联合索引。复合索引在数据存储上,首先根据第一字段排序、然后当第一字段值相同时在以第二字段排序、依次类推第N字段。复合索引能够满足以下两个场景的查询需要:根据复合索引多个字段组合查询;根据所有前缀字段查询,也就是所有字段的顺序的第一个至第N个的前缀字段查询。
1 2 3 4 5 6 7 8 9 10 11 12 13 | 格式:db.collectionName.createIndex({索引字段1:排序, 索引字段2:排序} )实例:对集合user添加字段from降序、age升序索引db.user.createIndex({from:-1,age:1 })以下情况可以使用到索引:db.user.find({from:20,age:8})、db.user.find({from:20})以下情况不能使用索引:db.user.find({age:8,from:20})、db.user.find({age:8}) |
根据复合索引的使用情况得出以下几点小结论:
- 索引使用顺序一定要和索引创建顺序保持一致;
- 当索引字段不完全组合查询时,需要前序字段连续;
- 创建索引时最好取值丰富的字段在前。
多key索引:
多key索引是指创建的索引字段为数组,多key索引会为数组的每个元素建立一条索引,使用场景就是针对字段值是数组的查询。有了前面的基础,这一个就很好理解,就不在详细描述了。
文本索引:
文本索引,简单的说就是针对文本数据创建索引,比如,文章信息表,如果需要根据文章关键词检索,那么就可以对文章字段创建文本索引。格式为:db.collectionName.createIndex({索引字段1: "text" } )
04
索引额外属性说明
createIndex创建索引时,该方法有两个参数,第一个参数就是索引字段,上面已经说了,第二个参数就是索引的额外属性,下面我们就说说索引额外属性信息。索引额外属性包括:唯一索引、TTL索引、稀疏索引。
TTL索引:
TTL索引属性是修饰当文档存储自定时间,当超出指定时间后,数据被被自动删除,使用场景为数据只存储指定时间,如:日志数据,关键词为expireAfterSecs,格式为:db.collectionName.createIndex({索引字段1: "text" }, {"expireAfterSecs": 失效时间单位为秒})。
TTL索引几点注意事项:
- TTL只使用于时间字段
- TTL不使用于联合索引
- TTL如果对于索引值是数组,那么只要其中一个值满足要求就自动删除
唯一索引 (unique index):
保证索引对应的字段不会出现相同的值,比如_id索引就是唯一索引。格式为:db.collectionName.createIndex({索引字段1: "text" }, {"unique": true})。
部分索引 (partial index):
只针对符合某个特定条件的文档建立索引,3.2版本才支持该特性。关键词为partialFilterExpression,
1 2 3 4 5 6 7 | 格式为:db.collectionName.createIndex({索引字段1: "text" }, {"partialFilterExpression": {数据满足条件表达式}})。 比如:对表user只有age=9的数据创建索引 db.user.createIndex({age:1}, {"partialFilterExpression":{age:9}}) |
稀疏索引(sparse index):
只针对存在索引字段的文档建立索引,可看做是部分索引的一种特殊情况。关键词为:sparse,格式为:db.collectionName.createIndex({索引字段1: "text" }, {"sparse": true})。
06
索引优化(profiling)
其实我们在建集合的时候,很多时候最开始是不知道那一些字段需要添加索引,是需要根据后续的实际使用场景来动态创建,那么这就会有一个问题,如果监控哪一些字段需要添加或是删除索引,可通过检测每一次操作结果的响应时间长短来动态创建索引,mongdb提供了一个profiling来动态检测执行响应情况。
MongoDB支持对DB的请求进行profiling,目前支持3种级别的profiling。
- 0: 不开启profiling
- 1: 将处理时间超过某个阈值(默认100ms)的请求都记录到DB下的system.profile集合 (类似于mysql、redis的slowlog)
- 2: 将所有的请求都记录到DB下的system.profile集合(生产环境慎用)
通常,生产环境建议使用1级别的profiling,并根据自身需求配置合理的阈值,用于监测慢请求的情况,并及时的做索引优化。
1 2 | 开启profiling命令:db.setProfilingLevel(1,120 );查询profil记录信息:db.system.profile.find() |
最终通过查询出来的记录信息,对索引进行优化。
07
小结
Mongdb在提升查询效率上是很有帮助,但是在实际使用中也不要滥用,否则会适得其反,下面总结几点,供参考:
- 索引创建时最好作用于取值丰富的字段,有限值的字段就没必要添加索引;
- 经常排序的字段,可以考虑添加索引;
- 一个集合中索引的个数不是越多越好,需要根据实际情况来定;
- 执行接口慢,有可能是缺少索引(查询慢),也有可能是索引使用不当(编辑慢);
- 复合索引在使用时,一定要结合索引字段的顺序使用。
-
END
原创不易,感谢扫描支持,获取更多精彩,谢谢:




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构