
Redis 使用Zset实现商品热度排行榜
一:前言
首先我们来了解一下这个基本的结构:为什么要用Zset来实现排行榜等一些排序的业务
它是由跳表和字典(哈希表)组成的,其实这样就明白了,这两个数据结构对于数据处理方面是非常快速的
简单说明:
跳表是什么:跳跃列表的平均时间复杂度为 O(log N) 对于查找、插入和删除操作
哈希表:这个的话,知道map的基本大多数对于这个也不陌生,查询速度非常快,他的key是无序的,时间复杂度如果说数据不大的情况下,没有哈希冲突那么时间复杂度基本就是O(1)了
二:初始化一遍数据,查询出来由高到低的数据(如果想指定查多少条也很简单)如查前3
reverseRangeWithScores("PRODUCT:ZINDEX", 0L, 2L);就ok
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@BeforeEach
public void setUp() {
redisTemplate.delete("PRODUCT:ZINDEX");
// 向 Redis 中添加数据
redisTemplate.opsForZSet().add("PRODUCT:ZINDEX", "ProductA", 190.0);
redisTemplate.opsForZSet().add("PRODUCT:ZINDEX", "ProductB", 280.0);
redisTemplate.opsForZSet().add("PRODUCT:ZINDEX", "ProductC", 470.0);
redisTemplate.opsForZSet().add("PRODUCT:ZINDEX", "ProductD", 170.0);
redisTemplate.opsForZSet().add("PRODUCT:ZINDEX", "ProductE", 270.0);
redisTemplate.opsForZSet().add("PRODUCT:ZINDEX", "ProductF", 370.0);
}
@Test
void contextLoads() {
// 查询排行榜全部数据按照热度从大到小排序
Set<ZSetOperations.TypedTuple<Object>> set1 = redisTemplate.opsForZSet().reverseRangeWithScores("PRODUCT:ZINDEX", 0L, -1L);
log.info("set1: {}", set1);
assert set1 != null;// 测试断言,生产环境不要用
set1.forEach(System.out::println);
}
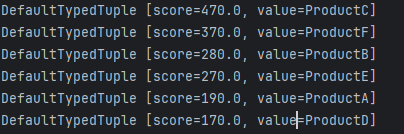
以上就是查询出来的效果,下面这张图的话,就是热度实时更新
@Test
void contextLoads() {
//这边就不将数据添加到Redis了,因为刚刚添加过了,直接进行查询出来展示
// 查询排行榜全部数据按照热度从大到小排序
increaseProductPopularity("ProductA");//假装热度冲上去了A
Set<ZSetOperations.TypedTuple<Object>> set1 = redisTemplate.opsForZSet().reverseRangeWithScores(key, 0L, -1L);
log.info("set1: {}", set1);
assert set1 != null;// 测试断言,生产环境不要用
set1.forEach(System.out::println);
}
public void increaseProductPopularity(String productId) {
//这里有个逻辑就是 我是测试初始化出来的商品key 实际中:商品id是不存在redis的 自己可以自己写一个方法,获取到商品id,然后进行操作 生成key
double scoreIncrement = 500.0; // 每次访问增加的热度值
ZSetOperations.TypedTuple<String> tuple = new DefaultTypedTuple<>(productId, redisTemplate.opsForZSet().score(key, productId));
// 如果商品已在热度排行中,增加热度
redisTemplate.opsForZSet().incrementScore(key, productId, scoreIncrement);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号