python 统计MySQL表信息
一、场景描述
线上有一台MySQL服务器,里面有几十个数据库,每个库有N多表。
现在需要将每个表的信息,统计到excel中,格式如下:
| 库名 | 表名 | 表说明 | 建表语句 |
| db1 | users | 用户表 | CREATE TABLE `users` (...) |
二、需求分析
怎么做呢?
1. 手动录入(太TM苦逼了,那么多表呀...)
2. 使用Python自动录入(Great)
三、获取相关信息
需要利用的技术点,有2个。一个是pymysql(连接mysql),一个是xlwt(写入excel)
安装模块
pip3 install pymysql xlwt
获取所有数据库
请确保有一个账号,能够远程连接MySQL,并且有对应的权限。
我用的是本机的MySQL,目前只有一个数据库db1
新建文件tj.py,内容如下:



import pymysql conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 print(data_all)
执行输出:
(('information_schema',), ('db1',), ('mysql',), ('performance_schema',), ('sys',))
结果是一个元组,里面的每一个元素也是元组。使用for循环
import pymysql conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 # print(data_all) for i in data_all: print(i[0]) # 获取库名
执行输出:
information_schema
db1
mysql
performance_schema
sys
获取所有的表
要获取所有的表,必须要切换到对应的数据库中,使用show tables 才可以获取。
import pymysql conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 # print(data_all) for i in data_all: conn.select_db(i[0]) # 切换到指定的库中 cur.execute('SHOW TABLES') # 查看库中所有的表 ret = cur.fetchall() # 获取执行结果 print(ret)
执行输出:
(('CHARACTER_SETS',), ('COLLATIONS',), ('COLLATION_CHARACTER_SET_APPLICABILITY',), ('COLUMNS',), ('COLUMN_PRIVILEGES',), ('ENGINES',), ('EVENTS',), ('FILES',), ('GLOBAL_STATUS',), ('GLOBAL_VARIABLES',), ('KEY_COLUMN_USAGE',), ('OPTIMIZER_TRACE',), ('PARAMETERS',), ('PARTITIONS',), ('PLUGINS',), ('PROCESSLIST',), ('PROFILING',), ('REFERENTIAL_CONSTRAINTS',), ('ROUTINES',), ('SCHEMATA',), ('SCHEMA_PRIVILEGES',), ('SESSION_STATUS',), ('SESSION_VARIABLES',), ('STATISTICS',), ('TABLES',), ('TABLESPACES',), ('TABLE_CONSTRAINTS',), ('TABLE_PRIVILEGES',), ('TRIGGERS',), ('USER_PRIVILEGES',), ('VIEWS',), ('INNODB_LOCKS',), ('INNODB_TRX',), ('INNODB_SYS_DATAFILES',), ('INNODB_FT_CONFIG',), ('INNODB_SYS_VIRTUAL',), ('INNODB_CMP',), ('INNODB_FT_BEING_DELETED',), ('INNODB_CMP_RESET',), ('INNODB_CMP_PER_INDEX',), ('INNODB_CMPMEM_RESET',), ('INNODB_FT_DELETED',), ('INNODB_BUFFER_PAGE_LRU',), ('INNODB_LOCK_WAITS',), ('INNODB_TEMP_TABLE_INFO',), ('INNODB_SYS_INDEXES',), ('INNODB_SYS_TABLES',), ('INNODB_SYS_FIELDS',), ('INNODB_CMP_PER_INDEX_RESET',), ('INNODB_BUFFER_PAGE',), ('INNODB_FT_DEFAULT_STOPWORD',), ('INNODB_FT_INDEX_TABLE',), ('INNODB_FT_INDEX_CACHE',), ('INNODB_SYS_TABLESPACES',), ('INNODB_METRICS',), ('INNODB_SYS_FOREIGN_COLS',), ('INNODB_CMPMEM',), ('INNODB_BUFFER_POOL_STATS',), ('INNODB_SYS_COLUMNS',), ('INNODB_SYS_FOREIGN',), ('INNODB_SYS_TABLESTATS',)) (('school',), ('users',)) (('columns_priv',), ('db',), ('engine_cost',), ('event',), ('func',), ('general_log',), ('gtid_executed',), ('help_category',), ('help_keyword',), ('help_relation',), ('help_topic',), ('innodb_index_stats',), ('innodb_table_stats',), ('ndb_binlog_index',), ('plugin',), ('proc',), ('procs_priv',), ('proxies_priv',), ('server_cost',), ('servers',), ('slave_master_info',), ('slave_relay_log_info',), ('slave_worker_info',), ('slow_log',), ('tables_priv',), ('time_zone',), ('time_zone_leap_second',), ('time_zone_name',), ('time_zone_transition',), ('time_zone_transition_type',), ('user',)) (('accounts',), ('cond_instances',), ('events_stages_current',), ('events_stages_history',), ('events_stages_history_long',), ('events_stages_summary_by_account_by_event_name',), ('events_stages_summary_by_host_by_event_name',), ('events_stages_summary_by_thread_by_event_name',), ('events_stages_summary_by_user_by_event_name',), ('events_stages_summary_global_by_event_name',), ('events_statements_current',), ('events_statements_history',), ('events_statements_history_long',), ('events_statements_summary_by_account_by_event_name',), ('events_statements_summary_by_digest',), ('events_statements_summary_by_host_by_event_name',), ('events_statements_summary_by_program',), ('events_statements_summary_by_thread_by_event_name',), ('events_statements_summary_by_user_by_event_name',), ('events_statements_summary_global_by_event_name',), ('events_transactions_current',), ('events_transactions_history',), ('events_transactions_history_long',), ('events_transactions_summary_by_account_by_event_name',), ('events_transactions_summary_by_host_by_event_name',), ('events_transactions_summary_by_thread_by_event_name',), ('events_transactions_summary_by_user_by_event_name',), ('events_transactions_summary_global_by_event_name',), ('events_waits_current',), ('events_waits_history',), ('events_waits_history_long',), ('events_waits_summary_by_account_by_event_name',), ('events_waits_summary_by_host_by_event_name',), ('events_waits_summary_by_instance',), ('events_waits_summary_by_thread_by_event_name',), ('events_waits_summary_by_user_by_event_name',), ('events_waits_summary_global_by_event_name',), ('file_instances',), ('file_summary_by_event_name',), ('file_summary_by_instance',), ('global_status',), ('global_variables',), ('host_cache',), ('hosts',), ('memory_summary_by_account_by_event_name',), ('memory_summary_by_host_by_event_name',), ('memory_summary_by_thread_by_event_name',), ('memory_summary_by_user_by_event_name',), ('memory_summary_global_by_event_name',), ('metadata_locks',), ('mutex_instances',), ('objects_summary_global_by_type',), ('performance_timers',), ('prepared_statements_instances',), ('replication_applier_configuration',), ('replication_applier_status',), ('replication_applier_status_by_coordinator',), ('replication_applier_status_by_worker',), ('replication_connection_configuration',), ('replication_connection_status',), ('replication_group_member_stats',), ('replication_group_members',), ('rwlock_instances',), ('session_account_connect_attrs',), ('session_connect_attrs',), ('session_status',), ('session_variables',), ('setup_actors',), ('setup_consumers',), ('setup_instruments',), ('setup_objects',), ('setup_timers',), ('socket_instances',), ('socket_summary_by_event_name',), ('socket_summary_by_instance',), ('status_by_account',), ('status_by_host',), ('status_by_thread',), ('status_by_user',), ('table_handles',), ('table_io_waits_summary_by_index_usage',), ('table_io_waits_summary_by_table',), ('table_lock_waits_summary_by_table',), ('threads',), ('user_variables_by_thread',), ('users',), ('variables_by_thread',)) (('host_summary',), ('host_summary_by_file_io',), ('host_summary_by_file_io_type',), ('host_summary_by_stages',), ('host_summary_by_statement_latency',), ('host_summary_by_statement_type',), ('innodb_buffer_stats_by_schema',), ('innodb_buffer_stats_by_table',), ('innodb_lock_waits',), ('io_by_thread_by_latency',), ('io_global_by_file_by_bytes',), ('io_global_by_file_by_latency',), ('io_global_by_wait_by_bytes',), ('io_global_by_wait_by_latency',), ('latest_file_io',), ('memory_by_host_by_current_bytes',), ('memory_by_thread_by_current_bytes',), ('memory_by_user_by_current_bytes',), ('memory_global_by_current_bytes',), ('memory_global_total',), ('metrics',), ('processlist',), ('ps_check_lost_instrumentation',), ('schema_auto_increment_columns',), ('schema_index_statistics',), ('schema_object_overview',), ('schema_redundant_indexes',), ('schema_table_lock_waits',), ('schema_table_statistics',), ('schema_table_statistics_with_buffer',), ('schema_tables_with_full_table_scans',), ('schema_unused_indexes',), ('session',), ('session_ssl_status',), ('statement_analysis',), ('statements_with_errors_or_warnings',), ('statements_with_full_table_scans',), ('statements_with_runtimes_in_95th_percentile',), ('statements_with_sorting',), ('statements_with_temp_tables',), ('sys_config',), ('user_summary',), ('user_summary_by_file_io',), ('user_summary_by_file_io_type',), ('user_summary_by_stages',), ('user_summary_by_statement_latency',), ('user_summary_by_statement_type',), ('version',), ('wait_classes_global_by_avg_latency',), ('wait_classes_global_by_latency',), ('waits_by_host_by_latency',), ('waits_by_user_by_latency',), ('waits_global_by_latency',), ('x$host_summary',), ('x$host_summary_by_file_io',), ('x$host_summary_by_file_io_type',), ('x$host_summary_by_stages',), ('x$host_summary_by_statement_latency',), ('x$host_summary_by_statement_type',), ('x$innodb_buffer_stats_by_schema',), ('x$innodb_buffer_stats_by_table',), ('x$innodb_lock_waits',), ('x$io_by_thread_by_latency',), ('x$io_global_by_file_by_bytes',), ('x$io_global_by_file_by_latency',), ('x$io_global_by_wait_by_bytes',), ('x$io_global_by_wait_by_latency',), ('x$latest_file_io',), ('x$memory_by_host_by_current_bytes',), ('x$memory_by_thread_by_current_bytes',), ('x$memory_by_user_by_current_bytes',), ('x$memory_global_by_current_bytes',), ('x$memory_global_total',), ('x$processlist',), ('x$ps_digest_95th_percentile_by_avg_us',), ('x$ps_digest_avg_latency_distribution',), ('x$ps_schema_table_statistics_io',), ('x$schema_flattened_keys',), ('x$schema_index_statistics',), ('x$schema_table_lock_waits',), ('x$schema_table_statistics',), ('x$schema_table_statistics_with_buffer',), ('x$schema_tables_with_full_table_scans',), ('x$session',), ('x$statement_analysis',), ('x$statements_with_errors_or_warnings',), ('x$statements_with_full_table_scans',), ('x$statements_with_runtimes_in_95th_percentile',), ('x$statements_with_sorting',), ('x$statements_with_temp_tables',), ('x$user_summary',), ('x$user_summary_by_file_io',), ('x$user_summary_by_file_io_type',), ('x$user_summary_by_stages',), ('x$user_summary_by_statement_latency',), ('x$user_summary_by_statement_type',), ('x$wait_classes_global_by_avg_latency',), ('x$wait_classes_global_by_latency',), ('x$waits_by_host_by_latency',), ('x$waits_by_user_by_latency',), ('x$waits_global_by_latency',))
结果也是一个大的元组,使用for循环,提取表名
import pymysql conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 # print(data_all) for i in data_all: conn.select_db(i[0]) # 切换到指定的库中 cur.execute('SHOW TABLES') # 查看库中所有的表 ret = cur.fetchall() # 获取执行结果 for j in ret: print(j[0]) # 获取每一个表名
执行输出:
CHARACTER_SETS
COLLATIONS
COLLATION_CHARACTER_SET_APPLICABILITY
COLUMNS
...
获取建表语句
使用命令 show create table 表名 获取
import pymysql conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 # print(data_all) for i in data_all: conn.select_db(i[0]) # 切换到指定的库中 cur.execute('SHOW TABLES') # 查看库中所有的表 ret = cur.fetchall() # 获取执行结果 for j in ret: # 获取每一个表的建表语句 cur.execute('show create table `%s`;' % j[0]) ret = cur.fetchall() print(ret)
执行输出:
(('CHARACTER_SETS', "CREATE TEMPORARY TABLE `CHARACTER_SETS` (\n `CHARACTER_SET_NAME` varchar(32) NOT NULL DEFAULT '',\n `DEFAULT_COLLATE_NAME` varchar(32) NOT NULL DEFAULT '',\n `DESCRIPTION` varchar(60) NOT NULL DEFAULT '',\n `MAXLEN` bigint(3) NOT NULL DEFAULT '0'\n) ENGINE=MEMORY DEFAULT CHARSET=utf8"),) ...
从结果中可以看出,建表语句中有大量的 \n 这个是换行符。注意:是\n后面还有2个空格
领导肯定是不想看到有这种符号存在,怎么去除呢?使用eval+replace
import pymysql conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 # print(data_all) for i in data_all: conn.select_db(i[0]) # 切换到指定的库中 cur.execute('SHOW TABLES') # 查看库中所有的表 ret = cur.fetchall() # 获取执行结果 for j in ret: # 获取每一个表的建表语句 cur.execute('show create table `%s`;' % j[0]) ret = cur.fetchall() # print(ret) for k in ret: # 替换反斜杠,使用\\。替换换行符\n,使用下面的 structure = eval(repr(k[1]).replace('\\n ', '')) print(structure)
执行输出:
CREATE TEMPORARY TABLE `CHARACTER_SETS` (`CHARACTER_SET_NAME` varchar(32) NOT NULL DEFAULT '',`DEFAULT_COLLATE_NAME` varchar(32) NOT NULL DEFAULT '',`DESCRIPTION` varchar(60) NOT NULL DEFAULT '',`MAXLEN` bigint(3) NOT NULL DEFAULT '0' ) ENGINE=MEMORY DEFAULT CHARSET=utf8 ...
发现结果正常了!
结果真的很多,但我都需要吗?no no no,其实我只需要db1而已,其他的都是系统自带的表,我并不关心!
排除多余的表
定义一个排序列表,使用if排除,注意:i[0] 是库名
import pymysql conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 # print(data_all) for i in data_all: # 排序列表,排除mysql自带的数据库 exclude_list = ["sys", "information_schema", "mysql", "performance_schema"] if i[0] not in exclude_list: # 判断不在列表中时 conn.select_db(i[0]) # 切换到指定的库中 cur.execute('SHOW TABLES') # 查看库中所有的表 ret = cur.fetchall() # 获取执行结果 for j in ret: # 获取每一个表的建表语句 cur.execute('show create table `%s`;' % j[0]) ret = cur.fetchall() # print(ret) for k in ret: # 替换反斜杠,使用\\。替换换行符\n,使用下面的 structure = eval(repr(k[1]).replace('\\n ', '')) print(structure)
执行输出:
CREATE TABLE `school` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci CREATE TABLE `users` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '姓名',PRIMARY KEY (`id`),KEY `ix_users_name` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'
获取表说明
看下面一条建表语句
CREATE TABLE `users` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '姓名', PRIMARY KEY (`id`), KEY `ix_users_name` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表';
我需要获取 用户表 这3个字,如何操作?
1. 使用正则匹配?Oh, I'm sorry ,本人正则水平太烂了...
2. 使用COMMENT切割?那可不行,name字段也有COMMENT。
仔细发现,可以看出这2个COMMENT还是有区别的。最后一个COMMENT,后面有一个等号。
OK,那么就可以通过COMMENT=来切割了。
import pymysql conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 # print(data_all) for i in data_all: # 排序列表,排除mysql自带的数据库 exclude_list = ["sys", "information_schema", "mysql", "performance_schema"] if i[0] not in exclude_list: # 判断不在列表中时 conn.select_db(i[0]) # 切换到指定的库中 cur.execute('SHOW TABLES') # 查看库中所有的表 ret = cur.fetchall() # 获取执行结果 for j in ret: # 获取每一个表的建表语句 cur.execute('show create table `%s`;' % j[0]) ret = cur.fetchall() # print(ret) for k in ret: # 替换反斜杠,使用\\。替换换行符\n,使用下面的 structure = eval(repr(k[1]).replace('\\n ', '')) # 使用COMMENT= 切割 res = structure.split("COMMENT=") print(res)
执行输出:
['CREATE TABLE `school` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,PRIMARY KEY (`id`)\n) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci'] ["CREATE TABLE `users` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '姓名',PRIMARY KEY (`id`),KEY `ix_users_name` (`name`)\n) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci ", "'用户表'"]
注意: 有些表,是没有写表注释的,所以获取表说明时,要加一个判断
import pymysql conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 # print(data_all) for i in data_all: # 排序列表,排除mysql自带的数据库 exclude_list = ["sys", "information_schema", "mysql", "performance_schema"] if i[0] not in exclude_list: # 判断不在列表中时 conn.select_db(i[0]) # 切换到指定的库中 cur.execute('SHOW TABLES') # 查看库中所有的表 ret = cur.fetchall() # 获取执行结果 for j in ret: # 获取每一个表的建表语句 cur.execute('show create table `%s`;' % j[0]) ret = cur.fetchall() # print(ret) for k in ret: # 替换反斜杠,使用\\。替换换行符\n,使用下面的 structure = eval(repr(k[1]).replace('\\n ', '')) # 使用COMMENT= 切割,获取表说明 res = structure.split("COMMENT=") if len(res) > 1: # 判断有表说明的情况下 explain = res[1] # 表说明 print(explain)
执行输出:
'用户表'
输出结果是带有引号的,要去除引号,怎么操作?
使用strip就可以了
import pymysql conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 # print(data_all) for i in data_all: # 排序列表,排除mysql自带的数据库 exclude_list = ["sys", "information_schema", "mysql", "performance_schema"] if i[0] not in exclude_list: # 判断不在列表中时 conn.select_db(i[0]) # 切换到指定的库中 cur.execute('SHOW TABLES') # 查看库中所有的表 ret = cur.fetchall() # 获取执行结果 for j in ret: # 获取每一个表的建表语句 cur.execute('show create table `%s`;' % j[0]) ret = cur.fetchall() # print(ret) for k in ret: # 替换反斜杠,使用\\。替换换行符\n,使用下面的 structure = eval(repr(k[1]).replace('\\n ', '')) # 使用COMMENT= 切割 res = structure.split("COMMENT=") if len(res) > 1: explain = res[1] # 表说明 # print(explain) explain_new = explain.strip("'") # 去掉引号 print(explain_new)
执行输出:
用户表
接下来就需要将数据写入到excel中,但是,我们需要知道。写入excel,要不断的调整方位。
由于线上表众多,获取一次数据,需要几分钟时间,时间上耗费不起!
所以为了避免这种问题,需要将获取到的数据,写入json文件中。
构造json数据
既然要构造json数据,那么数据格式,要规划好才行!我构造的数据格式如下:
dic = { "库名":{ 'name': "库名", 'table_list': [ {'tname':"表名",'structure':"建表语句",'explain':"表说明"} ] } }
从上面可以看出,这是一个三层的数据嵌套
定义一个大字典,写入数据
import pymysql conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 # print(data_all) dic = {} # 大字典,第一层 for i in data_all: if i[0] not in dic: # 判断库名不在dic中时 # 排序列表,排除mysql自带的数据库 exclude_list = ["sys", "information_schema", "mysql", "performance_schema"] if i[0] not in exclude_list: # 判断不在列表中时 # 写入第二层数据 dic[i[0]] = {'name': i[0], 'table_list': []} conn.select_db(i[0]) # 切换到指定的库中 cur.execute('SHOW TABLES') # 查看库中所有的表 ret = cur.fetchall() # 获取执行结果 for j in ret: # 获取每一个表的建表语句 cur.execute('show create table `%s`;' % j[0]) ret = cur.fetchall() # print(ret) for k in ret: # 替换反斜杠,使用\\。替换换行符\n,使用下面的 structure = eval(repr(k[1]).replace('\\n ', '')) # 使用COMMENT= 切割 res = structure.split("COMMENT=") if len(res) > 1: explain = res[1] # 表说明 # print(explain) explain_new = explain.strip("'") # 去掉引号 # 写入第三层数据,分别是表名,建表语句,表说明 dic[i[0]]['table_list'].append({'tname': k[0], 'structure': structure,'explain':explain_new}) print(dic)
执行输出:
{'db1': {'name': 'db1', 'table_list': [{'tname': 'users', 'structure': "CREATE TABLE `users` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '姓名',PRIMARY KEY (`id`),KEY `ix_users_name` (`name`)\n) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'", 'explain': '用户表'}]}}
写入json文件
import pymysql import json conn = pymysql.connect( host="127.0.0.1", # mysql ip地址 user="root", passwd="", port=3306 # mysql 端口号,注意:必须是int类型 ) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库 cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果 # print(data_all) dic = {} # 大字典,第一层 for i in data_all: if i[0] not in dic: # 判断库名不在dic中时 # 排序列表,排除mysql自带的数据库 exclude_list = ["sys", "information_schema", "mysql", "performance_schema"] if i[0] not in exclude_list: # 判断不在列表中时 # 写入第二层数据 dic[i[0]] = {'name': i[0], 'table_list': []} conn.select_db(i[0]) # 切换到指定的库中 cur.execute('SHOW TABLES') # 查看库中所有的表 ret = cur.fetchall() # 获取执行结果 for j in ret: # 获取每一个表的建表语句 cur.execute('show create table `%s`;' % j[0]) ret = cur.fetchall() # print(ret) for k in ret: # 替换反斜杠,使用\\。替换换行符\n,使用下面的 structure = eval(repr(k[1]).replace('\\n ', '')) # 使用COMMENT= 切割 res = structure.split("COMMENT=") if len(res) >= 1: if len(res) == 1: explain = "" else: explain = res[1] # 表说明 # print(explain) explain_new = explain.strip("'") # 去掉引号 # 写入第三层数据,分别是表名,建表语句,表说明 dic[i[0]]['table_list'].append({'tname': k[0], 'structure': structure,'explain':explain_new}) # print(dic) with open('tj.json','w',encoding='utf-8') as f: f.write(json.dumps(dic))
执行程序,查看tj.json文件内容
{"db1": {"name": "db1", "table_list": [{"tname": "users", "structure": "CREATE TABLE `users` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '\u59d3\u540d',PRIMARY KEY (`id`),KEY `ix_users_name` (`name`)\n) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='\u7528\u6237\u8868'", "explain": "\u7528\u6237\u8868"}]}}
四、写入excel中
坐标体系
a1单元格的坐标为0,0。在xlrd模块里面,坐标都是数字,所以不能用a1表示。
坐标如下:

先来写入一段示例数据
新建文件excel.py,代码如下:
import xlwt f = xlwt.Workbook() sheet1 = f.add_sheet('学生',cell_overwrite_ok=True) row0 = ["姓名","年龄","出生日期","爱好"] colum0 = ["张三","李四","王五"] #写第一行 for i in range(0,len(row0)): sheet1.write(0,i,row0[i]) #写第一列 for i in range(0,len(colum0)): sheet1.write(i+1,0,colum0[i]) # 写入一行数据 sheet1.write(1,1,"23") sheet1.write(1,2,"1990") sheet1.write(1,3,"女") f.save('test.xls')
执行程序,查看excel文件内容

正式写入excel中
写入库名
熟悉语法之后,就可以写入到excel中了
编辑 excel.py,代码如下:
import xlwt import json f = xlwt.Workbook() sheet1 = f.add_sheet('统计', cell_overwrite_ok=True) row0 = ["库名", "表名", "表说明", "建表语句"] # 写第一行 for i in range(0, len(row0)): sheet1.write(0, i, row0[i]) # 加载json文件 with open("tj.json", 'r') as load_f: load_dict = json.load(load_f) # 反序列化文件 num = 0 # 计数器 for i in load_dict: # 写入库名 sheet1.write(num + 1, 0, i) f.save('test1.xls')
执行程序,查看excel文件

写入表名
import xlwt import json f = xlwt.Workbook() sheet1 = f.add_sheet('统计', cell_overwrite_ok=True) row0 = ["库名", "表名", "表说明", "建表语句"] # 写第一行 for i in range(0, len(row0)): sheet1.write(0, i, row0[i]) # 加载json文件 with open("tj.json", 'r') as load_f: load_dict = json.load(load_f) # 反序列化文件 num = 0 # 计数器 for i in load_dict: # 写入库名 sheet1.write(num + 1, 0, i) # 遍历所有表 for j in load_dict[i]["table_list"]: # 写入表名 sheet1.write(num + 1, 1, j['tname']) f.save('test1.xls')
执行程序,查看excel文件
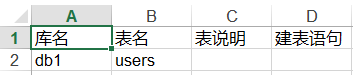
写入表说明和建表语句
import xlwt import json f = xlwt.Workbook() sheet1 = f.add_sheet('统计', cell_overwrite_ok=True) row0 = ["库名", "表名", "表说明", "建表语句"] # 写第一行 for i in range(0, len(row0)): sheet1.write(0, i, row0[i]) # 加载json文件 with open("tj.json", 'r') as load_f: load_dict = json.load(load_f) # 反序列化文件 num = 0 # 计数器 for i in load_dict: # 写入库名 sheet1.write(num + 1, 0, i) # 遍历所有表 for j in load_dict[i]["table_list"]: # 写入表名 sheet1.write(num + 1, 1, j['tname']) # 写入表说明 sheet1.write(num + 1, 2, j['explain']) # 写入建表语句 sheet1.write(num + 1, 3, j['structure']) num += 1 # 自增1 f.save('test1.xls')
注意:默认的num必须要自增,否则多个数据库写入会有问题
执行程序,查看excel文件

总结:
案例只是写入一个数据库,那么多个数据库,也是同样的代码。
有序字典
假设说,excel的内容是这样的
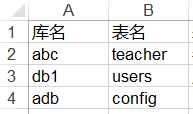
我需要对库名做一个排序,将abc和adb放在前2行,第三行是db1。该如何操作呢?
对于python 3.6之前,默认的字典都是无序的。如果需要将普通字典转换为有序字典,需要使用OrderedDict
举例:
from collections import OrderedDict dic = {"k":1,"a":2,"d":4} order_dic = OrderedDict() # 实例化一个有序字典 for i in sorted(dic): # 必须先对普通字典key做排序 order_dic[i] = dic[i] # 写入有序字典中 print(order_dic)
执行输出:
OrderedDict([('a', 2), ('d', 4), ('k', 1)])
注意:将普通字典转换为有序字典时,必须要先对普通字典,做一次排序。那么之后写入到有序字典之后,顺序就是有序了!
不论执行多少次print,结果都是一样的!
改造excel写入
编辑 excel.py,代码如下:
import xlwt import json from collections import OrderedDict f = xlwt.Workbook() sheet1 = f.add_sheet('统计', cell_overwrite_ok=True) row0 = ["库名", "表名", "表说明", "建表语句"] # 写第一行 for i in range(0, len(row0)): sheet1.write(0, i, row0[i]) # 加载json文件 with open("tj.json", 'r') as load_f: load_dict = json.load(load_f) # 反序列化文件 order_dic = OrderedDict() # 有序字典 for key in sorted(load_dict): # 先对普通字典key做排序 order_dic[key] = load_dict[key] # 再写入key num = 0 # 计数器 for i in order_dic: # 写入库名 sheet1.write(num + 1, 0, i) # 遍历所有表 for j in order_dic[i]["table_list"]: # 写入表名 sheet1.write(num + 1, 1, j['tname']) # 写入表说明 sheet1.write(num + 1, 2, j['explain']) # 写入建表语句 sheet1.write(num + 1, 3, j['structure']) num += 1 # 自增1 f.save('test1.xls')
执行程序,效果同上(因为数据太少了)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix