python 全栈开发,Day38(在python程序中的进程操作,multiprocess.Process模块)
昨日内容回顾
操作系统
纸带打孔计算机
批处理 —— 磁带
联机
脱机
多道操作系统 —— 极大的提高了CPU的利用率
在计算机中 可以有超过一个进程
进程遇到IO的时候 切换给另外的进程使用CPU
数据隔离 进程与进程之间的数据是隔离的
时空复用 在同一时刻 多个程序宏观上的并行
分时系统 —— 反而降低了CPU的效率 提高了用户体验
将时间分片 每一个进程都能够使用CPU一个时间片的时间
时间片轮转 一个进程在使用cpu的时候时间片到了,
就会切换到另一个进程
实时系统 —— 实时的响应任务
有一个进程时时刻刻能使用CPU
个人计算机 : 多道操作系统 分时系统 实时系统
4核 —— 4个任务
4核8线程 —— 8个任务
进程
进程的三个状态 就绪 阻塞 运行
进程的创建和结束
同步 异步 阻塞 非阻塞
两个任务依次执行 —— 同步
两个任务一起执行 —— 异步
同步 + 阻塞
inp = input()
print(inp)
异步 + 非阻塞
a.py input() 异步阻塞
b.py print() 异步非阻塞
在python代码中,是从上向下执行的。它是属于同步的
同步往往是 同步+阻塞
同步总是伴随着阻塞
比如上面的例子,input都得等着用户输入
异步往往和非阻塞在一起
比如a.py和b.py,2个py在不同的文件中,执行互相不影响
当a.py和b.py同时执行时,就是异步非阻塞
单纯的一个py文件,没有异步非阻塞。异步非阻塞存在多个文件执行时才存在。
比如上面的例子
在python程序中的进程操作
之前我们已经了解了很多进程相关的理论知识,了解进程是什么应该不再困难了,刚刚我们已经了解了,运行中的程序就是一个进程。所有的进程都是通过它的父进程来创建的。因此,运行起来的python程序也是一个进程,那么我们也可以在程序中再创建进程。多个进程可以实现并发效果,也就是说,当我们的程序中存在多个进程的时候,在某些时候,就会让程序的执行速度变快。以我们之前所学的知识,并不能实现创建进程这个功能,所以我们就需要借助python中强大的模块。
multiprocess模块
仔细说来,multiprocess不是一个模块而是python中一个操作、管理进程的包。 之所以叫multi是取自multiple的多功能的意思,在这个包中几乎包含了和进程有关的所有子模块。由于提供的子模块非常多,为了方便大家归类记忆,我将这部分大致分为四个部分:创建进程部分,进程同步部分,进程池部分,进程之间数据共享。
multiprocess.process模块
process模块介绍
process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建。
1 2 3 4 5 6 7 8 9 10 11 12 | Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)强调:1. 需要使用关键字的方式来指定参数2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号参数介绍:1 group参数未使用,值始终为None2 target表示调用对象,即子进程要执行的任务3 args表示调用对象的位置参数元组,args=(1,2,'egon',)4 kwargs表示调用对象的字典,kwargs={'name':'egon','age':18}5 name为子进程的名称 |



p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
p.name:进程的名称
p.pid:进程的pid
p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断保护起来,import 的时候 ,就不会递归运行了。
每一个进程,都有一个进程id号
查看进程号
1 2 3 4 | import osimport timeprint(os.getppid())time.sleep(1000) # 方便查看进程 |
执行输出:12492
打开windows的任务管理器,找到pid为12492进程,它是一个Pycharm进程

系统中的进程id号,是不会冲突的。
每一个进程,对应一个唯一的进程id号
假设这台电脑是4核,它可以开4个进程,每一个进程对应一个核。
但是上面的代码,在同一时间,只能用一个核。如果想充分利用CPU,需要开4个线程才行。
多进程的作用,就是为了提高效率
使用process模块创建进程
1 2 3 4 5 6 7 8 9 | import osimport timefrom multiprocessing import Processdef process1(): print('process1:',os.getppid()) time.sleep(1)print(os.getppid()) # 获取当前进程idprocess1() # 执行函数 |
执行输出:
12492
process1: 12492
进程id全都是一样的。程序一旦执行,进程id不会变。
使用target调用对象,即子进程要执行的任务
1 2 3 4 5 6 7 8 9 10 | import osimport timefrom multiprocessing import Processdef process1(): print('process1:',os.getppid()) time.sleep(1)print(os.getppid()) # 获取当前进程idp = Process(target=process1) # 调用函数p.start() # 启动进程 |
执行报错:

在mac和linux执行不会报错
而windows会报错,why ?
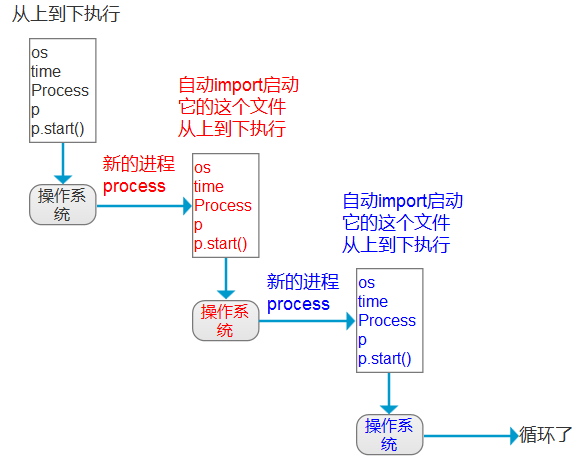
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这
个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。
所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断保护起来,import 的时候 ,就不会递归运行了
linux 执行函数,会把代码copy一份,到一个空间里面
那么下一次执行时,直接调用,就可以了。
解决方案:
1 2 3 4 5 6 7 8 9 10 11 | import osimport timefrom multiprocessing import Processdef process1(): print('process1:',os.getppid()) time.sleep(1)print(os.getppid()) # 获取当前进程idif __name__ == '__main__': p = Process(target=process1) # 调用函数 p.start() # 启动进程 |
执行输出:
12492
16876
process1: 16876
16876为父进程
1 2 3 4 5 6 7 8 9 10 11 12 | import osimport timefrom multiprocessing import Processdef process1(): print('process1:',os.getppid()) time.sleep(1)if __name__ == '__main__': print(os.getppid()) # 获取当前进程id p = Process(target=process1) # 调用函数 p.start() # 启动进程 |
执行输出:
12492
process1: 15624
执行结果,表示在当前进程中,开启了一个新的进程
使用args关键字给函数传参
1 2 3 4 5 6 7 8 9 10 11 12 13 | import osimport timefrom multiprocessing import Processdef process1(n,name): print('process1:',os.getppid()) print('n:',n,name) time.sleep(1)if __name__ == '__main__': print(os.getppid()) # 获取当前进程id p = Process(target=process1,args=[1,'alex']) # 调用函数并传参 p.start() # 启动进程 |
执行输出:
12492
process1: 16676
n: 1 alex
那么函数如果加return,可以获取结果吗?等学到后面,就可以获取进程的返回值了。稍安勿躁!
进程与子进程
1 2 3 | import osprint(os.getpid()) # 当前进程print(os.getppid()) # 父进程 |
执行输出:
14920
12492
12492就是Pycharm进程,看下图
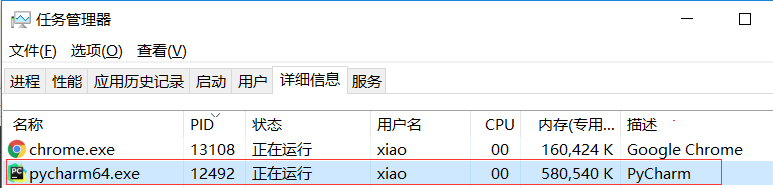
多执行几次,当前进程会一直变,但是父进程却不会变。除非你把Pycharm关了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import osimport timefrom multiprocessing import Processprint('1',os.getpid()) # 当前进程time.sleep(1)print('2',os.getppid()) # 父进程time.sleep(1)def func(): print('3',os.getpid(),os.getppid()) time.sleep(1)if __name__ == '__main__': #p = Process(target=func) #p.start() # 上面2句等于下面这句 Process(target=func).start() |
执行输出:
1 14512
2 12492
1 17048
2 14512
3 17048 14512
为啥会输出5个结果呢?应该是3个才对呀?
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。
所以输出5个结果
整个py文件运行之后,就是主进程
总结:
主进程默认会等待子进程执行完毕之后才结束
看下面的代码,print会立刻执行吗?
1 2 3 4 5 6 7 8 9 10 11 12 | import osimport timefrom multiprocessing import Processdef func(): print('func',os.getpid(),os.getppid()) time.sleep(1)if __name__ == '__main__': print(os.getpid(), os.getppid()) Process(target=func).start() print('*'*20) |
执行输出:
8652 12492
********************
func 16928 8652
立马就打印了****,这是为什么呢?
它是一个异步程序,主程序执行时,它不会等待1秒(子进程)
但是执行结束的动作时,它会等待子进程结束,除非异常退出。
否则子进程会变成一个僵尸进程。自己创建的,需要自己销毁。
总结:
主进程默认会等待子进程执行完毕之后才结束
主进程和子进程之间的代码是异步的
为什么主进程要等待子进程结束 回收一些子进程的资源
开启一个进程是有时间开销的 :操作系统响应开启进程指令,给这个进程分配必要的资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import osimport timefrom multiprocessing import Processdef func(): print('func',os.getpid(),os.getppid()) time.sleep(1)if __name__ == '__main__': print(os.getpid(), os.getppid()) Process(target=func).start() print('*'*20) print('*' * 30) time.sleep(0.5) print('*' * 40) |
执行输出:
10424 12492
********************
******************************
func 4564 10424
****************************************
同步控制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import osimport timefrom multiprocessing import Processdef func(): print('func',os.getpid(),os.getppid()) time.sleep(1)if __name__ == '__main__': print(os.getpid(), os.getppid()) p = Process(target=func) p.start() p.join() #主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态) print('*'*20) # 等待1秒后执行 |
执行输出:
18328 12492
func 18376 18328
********************
上面的代码没啥意义,它和面向过程执行一个函数,没啥区别。
举一个实际的例子
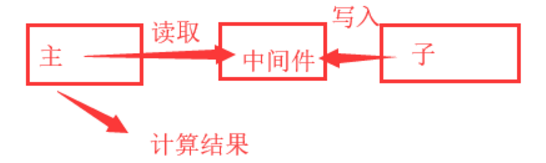
让子进程计算一个值,主进程必须等到子进程计算完之后,根据计算的值,来进行下一步计算
以文件为消息中间件,来完成主进程获取子进程的值,从而计算最终结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import osimport timefrom multiprocessing import Processdef func(exp): print('func',os.getpid(),os.getppid()) result = eval(exp) with open('file','w') as f: f.write(str(result)) # 写入的内容必须是一个字符串if __name__ == '__main__': print(os.getpid(), os.getppid()) p = Process(target=func,args=['3*5']) p.start() ret = 5/6 p.join() #主线程等待子进程计算完 with open('file') as f: result = f.read() # 读取结果 ret = ret + int(result) # 最终计算结果 print(ret) |
执行输出:
16784 12492
func 17304 16784
15.833333333333334
一般情况下,是主进程,开启子进程
子进程开启子进程的情况很少。
开启多个子进程
1 2 3 4 5 6 7 8 9 10 11 | import osimport timefrom multiprocessing import Processdef func(n): print(n,os.getpid(),os.getppid()) #print(n)if __name__ == '__main__': Process(target=func,args=[1]).start() Process(target=func, args=[2]).start() |
执行输出:
1 14648 9832
2 17024 9832
使用for循环开启10个进程
1 2 3 4 5 6 7 8 9 10 11 | import osimport timefrom multiprocessing import Processdef func(n): print(n,os.getpid(),os.getppid()) #rint(n)if __name__ == '__main__': for i in range(10): Process(target=func,args=[i]).start() |
执行输出:
1 14048 16976
2 16876 16976
0 10944 16976
3 18276 16976
6 9484 16976
4 17092 16976
5 8652 16976
8 15624 16976
7 17832 16976
9 7012 16976
这是为什么是随机的?而不是顺序的?
多个进程同时运行(注意,子进程的执行顺序不是根据启动顺序决定的)
是操作系统来决定的。它不一定是按照你的顺序来开启进程的。
它有自己的算法,比如开启一个进程,时间片轮转了。那么就不是顺序的。
再来一个高大上的例子
假如有10个表达式
1 2 3 4 5 6 7 8 9 10 11 12 13 | import osimport timefrom multiprocessing import Processdef func(n): print(n,os.getpid(),os.getppid()) #rint(n)if __name__ == '__main__': for i in range(10): p = Process(target=func,args=[i]) p.start() print('求和') |
但是这样,是没有意义的。和面向过程没啥区别了
高级的办法,使用append
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import osimport timefrom multiprocessing import Processdef process(n): print(os.getpid(),os.getppid()) time.sleep(1) print(n)if __name__ == '__main__': p_lst = [] # 定义一个列表 for i in range(10): p = Process(target=process,args=[i,]) p.start() p_lst.append(p) # 将所有进程写入列表中 for p in p_lst:p.join() # 检测p是否结束,如果没有结束就阻塞直到结束,如果已经结束了就不阻塞 print('求和') |
它是将所有进程放入一个列表里面,那么当列表里面的每一个进程都执行完成之后,
执行最后一个求和结果
这里用到了 异步+同步。每一个子进程执行,属于异步。最终计算结果时,属于同步,因为它要等待所有子进程结束。
执行输出:
17180 16032
10080 16032
17992 16032
18112 16032
18064 16032
17872 16032
13440 16032
8704 16032
15536 16032
14032 16032
0
2
3
4
6
1
7
5
8
9
求和
多执行几次,求和是最后一个输出的。
开启进程的第二种方式
上面讲的子进程开启方式是:
1 2 | p = Process(target=process,args=[1]) p.start() |
第二种方式,是通过继承来实现的
必须要重写run方法,名字必须是run
看源码
1 | from multiprocessing import Process |
女主播的例子:
1 2 3 4 5 6 7 8 9 10 11 | import osfrom multiprocessing import Processclass Myprocess(Process): def run(self): print(os.getpid()) print('和女主播聊天')if __name__ == '__main__': print(os.getpid()) p = Myprocess() p.start() # 在执行start的时候,会自动帮我们主动执行run方法 |
执行输出:
11604
13764
和女主播聊天
接收一个参数
那谁和女主播聊天呢?这个时候,需要参数。怎么传呢?使用__init__方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import osfrom multiprocessing import Processclass Myprocess(Process): def __init__(self,name): super().__init__() self.name = name def run(self): print(os.getpid()) print('%s和女主播聊天'%self.name)if __name__ == '__main__': print(os.getpid()) p = Myprocess('alex') p.start() # 在执行start的时候,会自动帮我们主动执行run方法 |
执行输出:
10464
17860
alex和女主播聊天
接收多个参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import osfrom multiprocessing import Processclass Myprocess(Process): def __init__(self,*args): super().__init__() self.args = args def run(self): print(os.getpid()) for i in self.args: print('%s和女主播聊天'%i)if __name__ == '__main__': print(os.getpid()) p = Myprocess('alex','taibai') p.start() # 在执行start的时候,会自动帮我们主动执行run方法 |
执行输出:
17996
17532
alex和女主播聊天
taibai和女主播聊天
self.args 是一个元组类型,因为传了多个参数
打印进程名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import osfrom multiprocessing import Processclass Myprocess(Process): def __init__(self,*args): super().__init__() self.args = args def run(self): print(os.getpid(), self.name, self.pid) # 打印进程id,进程名,也是进程id for i in self.args: print('%s和女主播聊天'%i)if __name__ == '__main__': print(os.getpid()) p = Myprocess('alex','taibai') p.start() # 在执行start的时候,会自动帮我们主动执行run方法 |
执行输出:
15776
2628 Myprocess-1 2628
alex和女主播聊天
taibai和女主播聊天
注意:开启多个进程时,必须要写
1 | if __name__ == '__main__': |
这2种启动方式,喜欢哪种方式,就可以使用哪种方式
至少会一个就可以了。
进程中的数据隔离
如何证明是隔离的呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 | from multiprocessing import Processn = 100 # 全局变量def func(): global n n += 1 # 修改全局变量 print('son : ',n)if __name__ == '__main__': p = Process(target=func) p.start() p.join() # 等待子进程结束 print(n) # 打印全局变量 |
执行输出:
son : 101
100
子进程的变量不会影响主进程的变量
守护进程
守护进程会随着主进程的结束而结束。
主进程创建守护进程
其一:守护进程会在主进程代码执行结束后就终止
其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
注意:进程之间是互相独立的,主进程代码运行结束,守护进程随即终止
1 2 3 4 5 6 7 8 9 10 11 12 | import timefrom multiprocessing import Processdef func(): print('son start') time.sleep(1) print('son end')if __name__ == '__main__': p = Process(target=func) p.start()<br> print(p.name) # 打印进程名 print('在主进程中') # 主进程会等待子进程结束而结束 |
执行输出:
Process-1
在主进程中
son start
son end
注意:
一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行
现在设置一个守护进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import timefrom multiprocessing import Processdef func(): print('son start') time.sleep(1) print('son end')if __name__ == '__main__': p = Process(target=func) #在一个进程开启之前可以设置它为一个守护进程 p.daemon = True p.start() print('main------') |
执行输出: 在主进程中
为什么只输出了一句话,子进程的输出呢?
打印该行则主进程代码结束,则守护进程Process-1应该被终止.
可能会有Process-1任务执行的打印信息son start,
因为主进程打印main----时,Process-1也执行了,但是随即被终止.
总结:
守护进程的意义:
子进程会随着主进程代码的执行结束而结束
注意:守护进程不会关系主进程什么时候结束,我只关心主进程中的代码什么时候结束
守护进程的作用:
守护主进程,程序报活
主进程开启的时候 建立一个守护进程
守护进程只负责每隔1分钟 就给检测程序发一条消息
如果没有守护,使用代码实现:
1 2 3 4 | import timewhile True: time.sleep(60) sk.send('我还活着') |
但是这样,就无法做其他事情了
看下面的代码,它的执行效果是什么?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | import timefrom multiprocessing import Processdef func(): print('son start') while True: time.sleep(1) print('son end')def fun2(): print('start :in fun2') time.sleep(5) print('end : in fun2')if __name__ == '__main__': p = Process(target=func) #在一个进程开启之前可以设置它为一个守护进程 p.daemon = True p.start() # 异步执行 print(p.name) p2 = Process(target=fun2) p2.start() # 异步执行 print(p2.name) time.sleep(2) print('在主进程中') |
执行输出:
Process-1
Process-2
son start
start :in fun2
son end
在主进程中
end : in fun2
分析:
主进程的代码 大概在2s多的时候就结束了
p2子进程实在5s多的时候结束
主进程结束
p是在什么时候结束的?
p是在主进程的代码执行完毕之后就结束了
总结:
主进程会等待子进程的结束而结束
守护进程的意义:
子进程会随着主进程代码的执行结束而结束
注意:守护进程不会关系主进程什么时候结束,我只关心主进程中的代码什么时候结束
守护进程的作用:
守护主进程,程序报活
主进程开启的时候 建立一个守护进程
守护进程只负责每隔1分钟 就给检测程序发一条消息
进程中的其他方法:
显示进程名和id
1 2 3 4 5 6 7 8 9 10 | from multiprocessing import Processdef func(): print('wahaha')if __name__ == '__main__': p = Process(target=func) p.start() print(p.pid) # 进程id print(p.name) # 进程名 |
执行输出:
18256
Process-1
wahaha
检测当前进程是否活着
1 2 3 4 5 6 7 8 9 10 11 12 13 | import timefrom multiprocessing import Processdef func(): print('wahaha') time.sleep(3) print('wahaha end')if __name__ == '__main__': p = Process(target=func) p.start() print(p.is_alive()) # 是否活着,返回bool值 time.sleep(3) |
执行输出:
True
wahaha
wahaha end
在主进程中结束一个子进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import timefrom multiprocessing import Processdef func(): print('wahaha') time.sleep(5) print('wahaha end')if __name__ == '__main__': p = Process(target=func) p.start() print(p.is_alive()) # 是否活着,返回bool值 time.sleep(3) p.terminate() # 在主进程中结束一个子进程 |
执行输出:
True
wahaha
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import timefrom multiprocessing import Processdef func(): print('wahaha') time.sleep(5) print('wahaha end')if __name__ == '__main__': p = Process(target=func) p.start() print(p.is_alive()) # 是否活着,返回bool值 time.sleep(1) p.terminate() # 在主进程中结束一个子进程 print(p.is_alive()) |
执行输出:
True
wahaha
True
为啥最后会输出True呢?因为terminate是告知操作系统,要关闭这个进程。但是操作系统不会立即执行,它还有别的任务执行。那么执行is_alive时,结果仍然为True
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import timefrom multiprocessing import Processdef func(): print('wahaha') time.sleep(5) print('wahaha end')if __name__ == '__main__': p = Process(target=func) p.start() print(p.is_alive()) # 是否活着,返回bool值 time.sleep(1) p.terminate() # 在主进程中结束一个子进程 time.sleep(0.5) #等待0.5秒 print(p.is_alive()) |
执行输出:
True
wahaha
False
由于停顿了0.5秒,操作系统有反应的时间,所以能结束掉子进程。
今日作业:
socket聊天并发实例,使用原生socket的TCP协议,实现一个聊天的并发实例
server.py
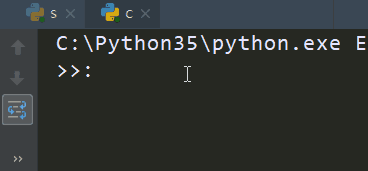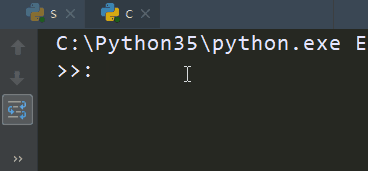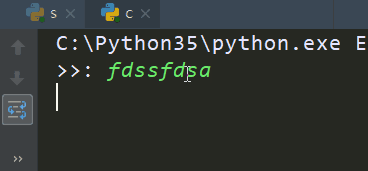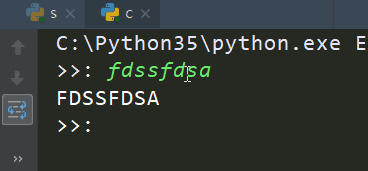
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | import socketfrom multiprocessing import Processserver=socket.socket()server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) # 允许端口复用server.bind(('127.0.0.1',9000))server.listen(5) #开始监听TCP传入连接,表示允许最大5个连接数def talk(conn,client_addr): # 说话 while True: try: msg=conn.recv(1024) # 接收客户端信息 if not msg:break conn.send(msg.upper()) # 发送信息,将内容转换为大写 except Exception: breakif __name__ == '__main__': #windows下start进程一定要写到这下面 while True: conn,client_addr=server.accept() # 等待接受客户端连接 p=Process(target=talk,args=(conn,client_addr)) # 调用函数 p.start() # 启动进程 |
client.py
1 2 3 4 5 6 7 8 9 10 11 12 | import socketclient=socket.socket()client.connect(('127.0.0.1',9000))while True: msg=input('>>: ').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8')) |
先执行server.py,再执行client.py
client输出:
明日默写:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import osfrom multiprocessing import Processdef func(exp): print(os.getpid(),os.getppid()) result = eval(exp) with open('file','w') as f: f.write(str(result))if __name__ == '__main__': print(os.getpid(),os.getppid()) # process id,parent process id # 3*5+5/6 p = Process(target=func,args=['3*5']) # func p.start() ret = 5/6 p.join() # join方法能够检测到p进程是否已经执行完了,阻塞知道p执行结束 with open('file') as f: result = f.read() ret = ret + int(result) print(ret) |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix