python 全栈开发,Day24(复习,__str__和__repr__,__format__,__call__,__eq__,__del__,__new__,item系列)
反射:
使用字符串数据类型的变量名来使用变量
wwwh即what,where,why,how 这4点是一种学习方法
反射 :使用字符串数据类型的变量名来使用变量
1.文件中存储的都是字符串
2.网络上能传递的也最接近字符串
3.用户输入的也是字符串
上面的3种情况都是字符串,如果有这种情况的,需要操作类或者模块时,就需要用到反射
有4种应用
类调用静态属性
对象调用属性 和 方法
模块调用模块中的名字
调用自己模块中的名字
1 2 3 4 5 6 7 8 9 | a = 1import sysb = getattr(sys.modules['__main__'],'a')print(b) # 输出变量a的值,即1def func():print('11')c = getattr(sys.modules['__main__'],'func')print(c) # 输出func的内存地址getattr(sys.modules['__main__'],'func')() # 执行方法,输出11 |
执行输出:
1
<function func at 0x000002189E107F28>
11
Teacher类 wahaha方法的连续反射
1 2 3 4 5 6 | import sysclass Teacher(): def wahaha(self):print('wa')alex = getattr(sys.modules['__main__'],'Teacher')() # 获取当前模块的Teacher,并执行print(alex) # Teacher类的内存地址getattr(alex,'wahaha')() # 执行方法wahaha |
执行输出:
<__main__.Teacher object at 0x00000203554EBF28>
wa
反射静态方法
1 2 3 4 5 6 7 | import sysclass Teacher(object): @staticmethod def wahaha():print('wa')Teacher = getattr(sys.modules['__main__'],'Teacher') # # 获取当前模块的Teacher类getattr(Teacher,'wahaha')() # 执行类方法,注意加括号 |
执行输出:
wa
找对象
1 2 3 4 5 6 7 8 9 | import sysclass Teacher(object): def wahaha(self):print('wa') @staticmethod def qqxing():print('qq')alex = Teacher()b = getattr(sys.modules['__main__'],'alex')print(b) |
输出:
<__main__.Teacher object at 0x0000015469531048>
内置方法
__len__ len(obj)
obj对应的类中含有__len__方法,len(obj)才能正常执行
__hash__ hash(obj) 是object类自带的
只有实现了__hash__方法,hash(ojb)才能正常执行
hash是加加速寻址
1 | print(hash('str')) |
执行输出: 8500378945365862541
hash之后的数字,就是内存地址
hash之后,将value存储在对应的内存地址中
字典占用的内存相对的比,较用空间换时间
list占用的内存比较少,但是没有字典快
过一分钟,再次查看,发现数据都变了
-8079646337729346465
二、__str__,__repr__
repr() 函数将对象转化为供解释器读取的形式
1 2 | print(repr('1'))print(repr(1)) |
执行输出:
'1'
1
看起来,没啥作用
1 2 | print(str('1'))print(str(1)) |
执行输出:
1
1
1 2 | li = [1,2,3,4]print(li) |
执行输出:
[1, 2, 3, 4]
1 2 3 4 5 | class A: def __init__(self,*args): self.args = list(args)li = A(1,2,3,4,5)print(li) |
执行输出:
<__main__.A object at 0x000001AAB3CDB9E8>
在类中,所有对象,默认打印的是内存地址
改变对象的字符串显示__str__,__repr__
1 2 3 4 5 6 7 | class A: def __init__(self,*args): self.args = list(args) def __str__(self): return '[%s]' % (','.join([str(i) for i in self.args]))li = A(1,2,3,4,5)print(li) # 输出的结果是obj.__str__()的结果<br>print(str(li)) # 结果同上<br>print('%s'%li) # 结果同上 |
执行输出:
[1,2,3,4,5]
[1,2,3,4,5]
每一个对象,都有__str__方法
print执行时,实际是调用了__str__方法
1 2 3 4 5 6 7 8 9 10 11 | class Teacher: def __init__(self,name,age): self.name = name self.age = age def __str__(self): return "Teacher's object %s" % self.namea = Teacher('alex',80)b = Teacher('egon',80)print(a) # 实际调用了__str__print(b)<br>print(repr(a)) # 打印对象的内存地址 |
执行输出:
Teacher's object alex
Teacher's object egon
<__main__.Teacher object at 0x0000012346B9BF28>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | class Teacher: def __init__(self,name,age): self.name = name self.age = age def __str__(self): # 重新定义内置方法 return "Teacher's object %s" % self.name def __repr__(self): # 重新定义内置方法,为了做个性化输出 return 'repr function %s'%self.namea = Teacher('alex',80)b = Teacher('egon',80)print(repr(a)) # 打印repr函数的返回值print(a.__repr__()) #调用__repr__方法print('%r'%a)print(str(a)) # 打印str函数的返回值 |
执行输出:
repr function alex
repr function alex
repr function alex
Teacher's object alex
repr(obj)的结果和obj.__repr__()是一样的
'%r'%(obj)的结果和obj.__repr__()是一样的
所有的输出,本质就是向文件中写
print执行时,是去内部中寻找__str__方法
所以print没有输出不了的数据,因为每一个对象都有__str__方法
print一个对象是,打印的是内存地址
1 2 3 | def repr(obj): # 归一化设计 return obj.__repr__()print(repr('1')) |
执行输出:'1'
repr执行时,其实是调用__repr__方法
repr(obj)的结果和obj.__repr__()是一样的
那么问题来了
1 2 | repr(1)repr('1') |
的结果为什么不一样?
看下面的例子:
1 2 3 4 5 6 7 8 9 10 11 | class int: def __repr__(self): return str(1)a = int()print(repr(a))class str2: def __repr__(self): return "'%s'" % str(1)b = str2()print(repr(b)) |
执行输出:
1
'1'
repr的功能,之所以能还原数据原来的样子
是因为每一种数据对象的__reprt__都不一样
那么repr是做了归一化设计,接收一个对象。python一切皆对象
每个对象都有__repr__方法。执行rept,就执行了__repr__方法。
为什么做归一化设计呢?因为要更接近于面向函数编程
如果每一个对象,都要对象名.__str__这样执行,太麻烦了
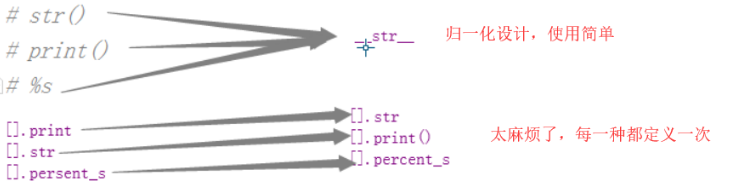
使用函数的方法,要比类名.方法名 使用简单
当需要使用__str__的场景时找不到 __str__就找__repr__
当需要使用__repr__的场景时找不到__repr__的时候就找父类的repr
双下repr是双下str的备胎
总结:
len() obj.__len__() 返回值是一致的
len() 的结果是依赖 obj.__len__()
hash() 的结果是依赖 obj.__hash__()
str() 的结果是依赖 obj.__str__()
print(obj) 的结果是依赖 obj.__str__()
%s 的结果是依赖 obj.__str__() 语法糖
#
repr() 的结果是依赖 obj.__repr__()
%r 的结果是依赖 obj.__repr__()
repr是str的备胎
如果__str__和__repr__同时存在, 一定是选择repr
推荐几本书
《核心编程 第2版》 有很多基础知识
《核心编程 第3版》
《流畅的python》 有点难度,这本书比较火
《数据结构与算法》 机械工业出版社
对底层结构比较感兴趣的话,可以看《数据结构与算法》这本书
机械工业出版社,是比较权威的,
出的书是比较有代表性的
这本书,用例主要是用Python实现的
为什么int类型,可以使用%s,是因为int有___repr__方法
1 2 3 4 | object.__repr__()'%r' # __repr__()int.__repr__()str.__repr__() |
%r 也是语法糖,不只是只有@
凡是不是调用函数,而是使用用一些符号之类的,都是语法糖
== 也是语法糖,它在内部执行时,是调用了内置方法,python解释器帮我们做了。
表面能使用的符号,内部其实是调用了方法,执行了计算过程。
三、__format__
format执行,就是调用了__format__方法
1 2 3 4 5 6 7 8 | class A: def __init__(self,name,school,addr): self.name = name self.school = school self.addr = addra = A('大表哥','oldboy','沙河')print(format(a)) |
执行输出:
<__main__.A object at 0x000001AD3B07BF28>
对象之所以能用format,是因为object有这个__format__方法
查看object源码
1 2 3 | def __format__(self, *args, **kwargs): # real signature unknown """ default object formatter """ pass |
format执行时,必须要有参数format_spec才行
查看源码
1 2 3 4 5 6 7 | def format(*args, **kwargs): # real signature unknown """ Return value.__format__(format_spec) format_spec defaults to the empty string """ pass |
自定义一个__format__方法
1 2 3 4 5 6 7 8 9 10 11 12 13 | class A: def __init__(self,name,school,addr): self.name = name self.school = school self.addr = addr def __format__(self, format_spec): #format_spec = '{obj.name}-{obj.addr}-{obj.school}' return format_spec.format(obj=self) #此行的format_spec等同于上面一行a = A('大表哥','oldboy','沙河')format_spec = '{obj.name}-{obj.addr}-{obj.school}'print(format(a,format_spec)) |
执行输出:
大表哥-沙河-oldboy
这样就可以在外部规定format的输出格式
{obj.name}-{obj.addr}-{obj.school}是用花括号{}的
比如正常情况下,也是用{}表示一个占位符,它是不能边的
如果输出的字符串,需要加中括号[ ],可以这么写
1 2 3 4 5 6 7 8 9 10 11 | class A: def __init__(self,name,school,addr): self.name = name self.school = school self.addr = addr def __format__(self, format_spec): return format_spec.format(obj=self) a = A('大表哥','oldboy','沙河')format_spec = '[{obj.name}]-[{obj.addr}]-[{obj.school}]'print(format(a,format_spec)) |
执行输出:
[大表哥]-[沙河]-[oldboy]
下面一个列子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | format_dict={ 'nat':'{obj.name}-{obj.addr}-{obj.type}',#学校名-学校地址-学校类型 'tna':'{obj.type}:{obj.name}:{obj.addr}',#学校类型:学校名:学校地址 'tan':'{obj.type}/{obj.addr}/{obj.name}',#学校类型/学校地址/学校名}class School: def __init__(self,name,addr,type): self.name=name self.addr=addr self.type=type def __format__(self, format_spec): #format_spec = 'nat' if not format_spec or format_spec not in format_dict: #判断参数是否为空或者是否在format_dict字典里 format_spec='nat' # 默认值为nat fmt=format_dict[format_spec] #'{obj.name}-{obj.addr}-{obj.type}' return fmt.format(obj=self) #'{obj.name}-{obj.addr}-{obj.type}'.format(obj=self)s1=School('oldboy1','北京','私立')print(format(s1,'nat')) #s1.__format__('nat')print(format(s1,'tna'))print(format(s1,'tan'))print(format(s1,'asfdasdffd')) # 字典不存在,走默认值。s1.__format__('nat') |
执行输出:
oldboy1-北京-私立
私立:oldboy1:北京
私立/北京/oldboy1
oldboy1-北京-私立
重新回忆一下if判断的知识
if True:print('执行if中的代码')
if False:print('不执行if中的代码')
if True or False:print('or两端的条件有一个为True就执行这个if中的代码')
if not True or False:pass 结果为False,不执行if代码
if not False or False:pass 结果为True,执行if代码
if not format_spec or format_spec not in format_dict 有一个条件为True,执行if代码
当数据为以下值时,分别是数字0,空列表,空字符串,空字典,空元组,None
1 | 0 [] '' {} () None |
表示False,否则为True
四、__call__
对象后面加括号,触发执行。
注:构造方法的执行是由创建对象触发的,即:对象 = 类名() ;而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()()
1 2 3 4 5 6 | class Teacher(): def __call__(self): print(123)t = Teacher()t() # 对象名() 相当于调用类内置的__call__Teacher()() #效果同上 |
执行输出:
123
123
有些源码会出现类名()()这种的,它其实是调用了__call__方法。所以一定要注意!!!
把__call__注释掉,再次执行
1 2 3 4 5 6 | class Teacher(): pass # def __call__(self): # print(123)t = Teacher()t() |
执行报错:
TypeError: 'Teacher' object is not callable
object默认没有__call__方法
使用callable方法,判断对象是否可调用
1 2 3 4 5 6 7 | class Teacher(): pass # def __call__(self): # print(123)t = Teacher()print(callable(Teacher))print(callable(t)) |
执行输出:
True
False
一个对象是否可调用 完全取决于这个对象对应的类是否实现了__call__
看Teacher类是否有__call__方法
1 | print('__call__' in Teacher.__dir__(Teacher)) |
执行输出: True
查看callabble方法的解释,有一句话
1 2 | Note that classes are callable (callinga class returns a new instance); instances are callable if their class has a __call__() method. |
翻译解释:
注意类是可调用的(调用)
一类返回一个新实例);实例调用如果类有一个__call __()方法。
print(callable(Teacher))的返回值是True
__call __()方法是针对对象的,而不是类。
python一切皆对象
1 2 3 4 5 6 7 8 | class Teacher(object): def __call__(self): print(123) def call(self): print(456)t = Teacher()t.call() # 手动执行call方法 |
执行输出: 456
五、__eq__
__eq__ 定义了类的等号(==)行为
1 2 3 4 5 | class A:passa = A()b = A()print(a)print(b) |
执行输出:
<__main__.A object at 0x000001D32763BF28>
<__main__.A object at 0x000001D327641320>
从结果上来看,内存地址是不一样的
判断是否相等
1 2 3 4 | class A:passa = A()b = A()print(a == b) |
执行输出:False
==实际是调用了 __eq__方法,它是判断内存地址,是否一致
自定义__eq__方法
1 2 3 4 5 6 7 8 | class A: def __eq__(self, other): return Truea = A()b = A()a.name = 'alex' # 增加一个属性b.name = 'egon'print(a == b) |
执行输出:True
== 是由__eq__的返回值来决定的
虽然明知道,a和b是不可能相等的。但是类方法__eq__强制改变了结果,不管是什么,结果总是为True
为了让__eq__方法更有意义,再改动一下。
1 2 3 4 5 6 7 8 9 10 11 12 | class A: def __eq__(self, other): if self.__dict__ == other.__dict__: return True else: return False a = A()b = A()a.name = 'alex' # 增加一个属性b.name = 'egon'print(a == b) |
执行输出:False
六、__del__
析构方法,当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
1 2 3 4 5 6 7 8 | class A: def __init__(self): pass def __del__(self): print('执行我啦')a = A()print('aaa') |
执行输出:
aaa
执行我啦
当类执行完毕时,自动执行析构方法
删除一个对象
1 2 3 4 5 6 7 8 9 | class A: def __init__(self): pass def __del__(self): print('执行我啦')a = A()del a # 主动删除对象print('aaa') |
执行输出:
执行我啦
aaa
当对象在内存中被释放时,自动触发执行
看下面的例子
1 2 3 4 5 6 7 8 9 | class A: def __init__(self): self.f = open('文件','w') # 打开文件句柄 # def __del__(self): # print('执行我啦')a = A()del aprint('aaa') |
执行输出:aaa
这段代码,有一个问题,文件打开了,但是文件句柄没有释放。那么就浪费内存了。
这个时候,需要在析构方法中,关闭文件句柄
1 2 3 4 5 6 7 8 9 | class A: def __init__(self): self.f = open('文件','w') def __del__(self): self.f.close() # 关闭文件句柄 print('文件关闭了')a = A()del a |
七、__new__
__new__方法是创建类实例的方法,它的调用是发生在__init__之前的
object默认就有了
看__new__的源码
1 2 3 4 | @staticmethod # known case of __new__ def __new__(cls, *more): # known special case of object.__new__ """ Create and return a new object. See help(type) for accurate signature. """ pass |
它是一个静态方法,没有self,因为此刻还没有self
__new__()面试必考
先有对象,才能初始化
__new__方法不需要写,object自带
先来讲一个设计模式-->单例模式
如果面试中,只要 是问单例模式,就是问__new__
单例模式 就是一个类只能有一个实例
应用场景
1.当一个类,多次实例化时,每个实例都会占用资源,而且实例初始化会影响性能,这个时候就可以考虑使用单例模式,它给我们带来的好处是只有一个实例占用资源,并且只需初始化一次
2.当有同步需要的时候,可以通过一个实例来进行同步控制,比如对某个共享文件(如日志文件)的控制,对计数器的同步控制等,这种情况下由于只有一个实例,所以不用担心同步问题
看下面的代码:
1 2 3 4 5 | class A:passa = A()b = A()print(a)print(b) |
执行输出:
<__main__.A object at 0x00000299A8D9BF28>
<__main__.A object at 0x00000299A8DA1320>
这不是单例模式,因为内存地址不一样
不是__init__的锅,是__new__的锅
__new__每次实例化,会创建一个新的内存地址
下面看一个真正的单例模式,使用__new__方法
1 2 3 4 5 6 7 8 9 10 11 12 | class B: __instance = None def __new__(cls, *args, **kwargs): # cls表示类 if cls.__instance is None: # 判断类变量__instance是否为None obj = object.__new__(cls) # 创建一个实例对象 cls.__instance = obj # 赋值 return cls.__instance # 返回私有静态属性a = B()b = B()print(a)print(b) |
执行输出:
<__main__.B object at 0x00000267F570BB00>
<__main__.B object at 0x00000267F570BB00>
上面的结果,内存地址是一样的。
注意:__new__每次实例化,都会执行!!!
实例化时,先执行__new__,再执行__init__
第一次执行时,cls.__instance 是None,创建一个对象
第二次执行时,cls.__instance 不是None,返回私有静态属性
再添加几个属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | class B: __instance = None def __new__(cls, *args, **kwargs): if cls.__instance is None: obj = object.__new__(cls) cls.__instance = obj return cls.__instance def __init__(self,name,age): self.name = name self.age = age<br> def func(self): print(self.name) a = B('alex',80) #实例化,传值b = B('egon',20) #实例化,覆盖值print(a)print(b)print(a.name)print(b.name) |
执行输出:
<__main__.B object at 0x000002483F7DFF28>
<__main__.B object at 0x000002483F7DFF28>
egon
egon
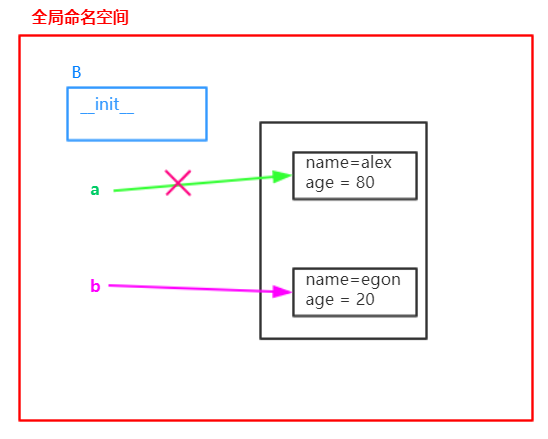
b实例化时,a对象的值指向就中断了。由于a和b共用一个内存空间,所以最终结果为egon
八、item系列
对象使用中括号的形式去操作
__getitem__ 当访问不存在的属性时会调用该方法
__setitem__属性被赋值的时候都会调用该方法
__delitem__删除属性时调用该方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | class Foo: def __init__(self,name): self.name=name def __getitem__(self,item): return self.__dict__[item] def __setitem__(self, key, value): self.__dict__[key]=value def __delitem__(self, key): print('del obj[key]时,我执行') self.__dict__.pop(key)f = Foo('alex')# f.name = ...print(f['name']) # f.__getitem__('name')f['age'] = 18 # 赋值print(f.age) # 自带的语法print(f['age']) # 修改f['age'] = 80print(f['age']) # 通过实现__getitem__得到的del f['age'] # 删除#print(f.age) # 删除 |
执行输出:
alex
18
18
80
del obj[key]时,我执行
想要用对象名.[名字]
必须实现__getitem__方法
__getitem __只能有一个参数
__setitem__能接收2个参数,一个是等号左边,一个是等号右边的
__delitem__很少用
__delattr不用实现,因为object自带就有
1 2 3 4 5 6 7 8 9 | class Foo: def __init__(self,name): self.name=name def __delattr__(self, item): print('del obj.key时,我执行') self.__dict__.pop(item)f = Foo('alex')del f.name #相当于执行了__delattr__# delattr(f,'name') |
执行输出:
del obj.key时,我执行
面试题:
1 2 3 4 | 有一个类Person,它有3个属性,分别是name,sex,age。实例化100次,每个对象的内存地址是不一样的。其中有2个对象,name和sex是一样的,age不同那么如何,去掉这2个重复的对象? |
答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | class Person: def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex def __hash__(self): # 实例化时,执行此方法 return hash(self.name + self.sex) # 对name和sex做hash,因为有2个对象name和sex一样,age不同 def __eq__(self, other): # 实例化时,执行此方法 if self.name == other.name and self.sex == other.sex: # 判断每一个对象的name和sex是否相同 return Truep_lst1 = [] #定义一个列表#生成98个实例对象for i in range(98): p_lst1.append(Person('egon' + str(i),i,'male'))#手动增加2个重复的,name和sex值是一样的,age不同p_lst1.append(Person('egon50',200,'male'))p_lst1.append(Person('egon50',300,'male'))#查看p_lst1的长度print(len(p_lst1))#使用集合去重,查看p_lst1的长度print(len(set(p_lst1))) |
执行输出:
100
98
注意:__hash__和__eq__方法,必须自己定义,否则无法去重
明日默写:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | class B: __instance = None def __new__(cls, *args, **kwargs): if cls.__instance is None: obj = object.__new__(cls) cls.__instance = obj return cls.__instance def __init__(self,name,age): self.name = name self.age = age def func(self): print(self.name)a = B('alex',80)b = B('egon',20)print(a)print(b)print(a.name)print(b.name) |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix