python爬取有道词典
一、网页分析
打开Google浏览器,找的有道词典的翻译网页(http://fanyi.youdao.com/)
打开后摁F12打开开发者模式,找Network选项卡,点击Network选项卡,然后刷新一下网页
然后翻译一段文字,随便啥都行(我用的程序员的传统:hello world),然后点击翻译
在选项卡中找到以translate开头的post文件
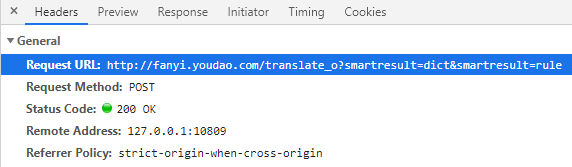
上面标注的,写代码时要用
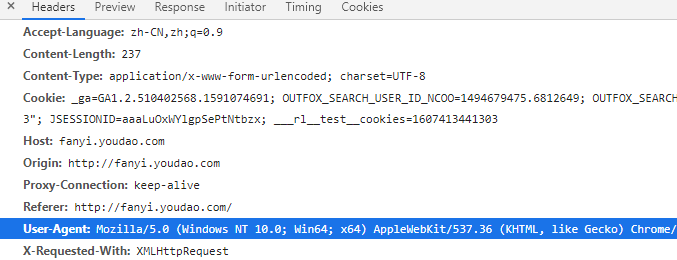
记住 User-Agent,用来伪装浏览器请求

这些是需要提交的参数。
好,准备工作做完了,接下来开始干正事了
二、代码演示



# !/usr/bin/python3 # -*- coding: utf-8 -*- import json import requests while True: #无限循环 content = input("请输入您要翻译的内容(输入 !!! 退出程序): ") #设置退出条件 if content == '!!!': break url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' #选择要爬取的网页,上面找过了 # 手动替换一下 header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'} #伪装计算机提交翻译申请(下面的内容也在在上面有过,最好根据自己的进行修改) data = {} data['type'] = 'AUTO' data['i'] = content data['doctype'] = 'json' data['version'] = '2.1' data['keyfrom:'] = 'fanyi.web' data['ue'] = 'UTF-8' data['typoResult'] = 'true' # post请求 response = requests.post(url,headers=header,data=data) # 解码 html = response.content.decode('utf-8') # 转换为字典 paper = json.loads(html) #打印翻译结果 print("翻译结果: %s" % (paper['translateResult'][0][0]['tgt']))
执行代码,效果如下:

本文参考链接:
https://blog.csdn.net/Spiderman_Feng/article/details/110675766
分类:
python 运维开发
标签:
爬虫


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2019-12-03 python3 根据时间获取本月一号和月末日期
2018-12-03 Kubernetes之YAML文件