Scrapy+Selenium爬取动态渲染网站
一、概述
使用情景
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值
使用流程
1. 重写爬虫文件的__init__()构造方法,在该方法中使用selenium实例化一个浏览器对象
2. 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象,该方法是在爬虫结束时被调用.
3. 在settings配置文件中开启下载中间件
二、案例演示
这里以房天下为例,爬取楼盘信息,链接如下:
https://sh.newhouse.fang.com/house/s/a75-b91/?ctm=1.sh.xf_search.page.1
页面分析
获取信息列表
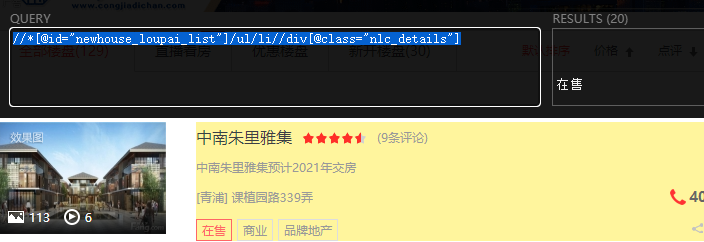
//*[@id="newhouse_loupai_list"]/ul/li//div[@class="nlc_details"]
它会获取20条信息
获取名称
//*[@id="newhouse_loupai_list"]/ul/li//div[@class="nlc_details"]//div[@class="nlcd_name"]/a/text()
结果如下:

获取价格
//*[@id="newhouse_loupai_list"]/ul/li//div[@class="nlc_details"]//div[@class="nhouse_price"]/span/text()
结果如下:

注意:别看它只有18条,因为还有2条,价格没有公布,所以获取不到。因此,后续我会它一个默认值:价格待定
获取区域
//*[@id="newhouse_loupai_list"]/ul/li//div[@class="relative_message clearfix"]//a/span/text()
结果如下:

注意:别看它只有17条,因为还有3条,不在国内。比如泰国,老挝等。因此,后续我会它一个默认值:国外
获取地址
//*[@id="newhouse_loupai_list"]/ul/li//div[@class="relative_message clearfix"]/div/a/text()
结果如下:

注意:多了17条,为什么呢?因此地址有些含有大段的空行,有些地址还包含了区域信息。因此,后续我会做一下处理,去除多余的换行符,通过正则匹配出地址信息。
获取状态
//*[@id="newhouse_loupai_list"]/ul/li//div[@class="nlc_details"]//span[@class="inSale"]/text()
结果如下:

注意:少了4条,那是因为它的状态是待售。因此,后续我会做一下处理,没有匹配的,给定默认值。
项目代码
通过以上页面分析出我们要的结果只会,就可以正式编写代码了。
创建项目
打开Pycharm,并打开Terminal,执行以下命令
scrapy startproject fang
cd fang
scrapy genspider newhouse sh.newhouse.fang.com
在scrapy.cfg同级目录,创建bin.py,用于启动Scrapy项目,内容如下:
# !/usr/bin/python3 # -*- coding: utf-8 -*- #在项目根目录下新建:bin.py from scrapy.cmdline import execute # 第三个参数是:爬虫程序名 execute(['scrapy', 'crawl', 'newhouse',"--nolog"])
创建好的项目树形目录如下:

./ ├── bin.py ├── fang │ ├── __init__.py │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── settings.py │ └── spiders │ ├── __init__.py │ └── newhouse.py └── scrapy.cfg
修改newhouse.py


# -*- coding: utf-8 -*- import scrapy from scrapy import Request # 导入模块 import math import re from fang.items import FangItem from selenium.webdriver import ChromeOptions from selenium.webdriver import Chrome class NewhouseSpider(scrapy.Spider): name = 'newhouse' allowed_domains = ['sh.newhouse.fang.com'] base_url = "https://sh.newhouse.fang.com/house/s/a75-b91/?ctm=1.sh.xf_search.page." # start_urls = [base_url+str(1)] # 实例化一个浏览器对象 def __init__(self): # 防止网站识别Selenium代码 options = ChromeOptions() options.add_argument("--headless") # => 为Chrome配置无头模式 options.add_experimental_option('excludeSwitches', ['enable-automation']) options.add_experimental_option('useAutomationExtension', False) self.browser = Chrome(options=options) self.browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { "source": """ Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) """ }) super().__init__() def start_requests(self): print("开始爬虫") self.base_url = "https://sh.newhouse.fang.com/house/s/a75-b91/?ctm=1.sh.xf_search.page." url = self.base_url + str(1) print("url",url) # url = "https://news.163.com/" response = scrapy.Request(url, callback=self.parse_index) yield response # 整个爬虫结束后关闭浏览器 def close(self, spider): print("关闭爬虫") self.browser.quit() # 访问主页的url, 拿到对应板块的response def parse_index(self, response): print("访问主页") # 获取分页 # 查询条数 ret_num = response.xpath('//*[@id="sjina_C01_47"]/ul/li[1]/b/text()').extract_first() # print("ret_num", ret_num, type(ret_num)) # 计算分页,每一页20条 jsfy = int(ret_num) / 20 # 向上取整 page_num = math.ceil(jsfy) # print("page_num",page_num) for n in range(1, page_num): n += 1 # 下一页url url = self.base_url + str(n) print("url", url) # 访问下一页,有返回时,调用self.parse_details方法 yield scrapy.Request(url=url, callback=self.parse_details) def parse_details(self, response): # 获取页面中要抓取的信息在网页中位置节点 node_list = response.xpath('//*[@id="newhouse_loupai_list"]/ul/li//div[@class="nlc_details"]') count = 0 # 遍历节点,进入详情页,获取其他信息 for node in node_list: count += 1 try: # # 名称 nlcd_name = node.xpath('.//div[@class="nlcd_name"]/a/text()').extract() if nlcd_name: nlcd_name = nlcd_name[0].strip() print("nlcd_name", nlcd_name) # # # 价格 price = node.xpath('.//div[@class="nhouse_price"]/span/text()').extract() # print("原price",price,type(price)) if price: price = price[0].strip() if not price: price = "价格待定" print("price", price) # 区域 region_ret = node.xpath('.//div[@class="relative_message clearfix"]//a/span/text()').extract() region = "" if region_ret: # if len(region) >=2: region_ret = region_ret[0].strip() # 正则匹配中括号的内容 p1 = re.compile(r'[\[](.*?)[\]]', re.S) region = re.findall(p1, region_ret) if region: region = region[0] # print("region",region) # # # # 地址 address_str = node.xpath('.//div[@class="relative_message clearfix"]/div/a/text()').extract() address = "" # 判断匹配结果,截取地址信息 if address_str: if len(address_str) >= 2: address_str = address_str[1].strip() else: address_str = address_str[0].strip() # print("address_str", address_str) # 判断地址中,是否含有区域信息,比如[松江] p1 = re.compile(r'[\[](.*?)[\]]', re.S) # 最小匹配 address_ret = re.findall(p1, address_str) if address_ret: # 截图地区 region = address_ret[0] # 地址拆分 add_cut_str = address_str.split() # 截取地址 if add_cut_str: address = add_cut_str[1] else: address = address_str # 为空时,表示在国外 if not region_ret: region = "国外" print("region", region) print("address", address) # # # 状态 status = node.xpath('.//span[@class="inSale"]/text()').extract_first() # status = node.xpath('.//div[@class="fangyuan pr"]/span/text()').extract_first() if not status: status = "待售" print("status", status) # item item = FangItem() item['nlcd_name'] = nlcd_name item['price'] = price item['region'] = region item['address'] = address item['status'] = status yield item except Exception as e: print(e) print("本次爬取数据: %s条" % count)
修改items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class FangItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() nlcd_name = scrapy.Field() price = scrapy.Field() region = scrapy.Field() address = scrapy.Field() status = scrapy.Field()
修改pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import json class FangPipeline(object): def __init__(self): # python3保存文件 必须需要'wb' 保存为json格式 self.f = open("fang_pipline.json", 'wb') def process_item(self, item, spider): # 读取item中的数据 并换行处理 content = json.dumps(dict(item), ensure_ascii=False) + ',\n' self.f.write(content.encode('utf=8')) return item def close_spider(self, spider): # 关闭文件 self.f.close()
注意:这里为了方便,保存在一个json文件中。当然,也可以设置保存到数据库中。
修改settings.py,应用pipelines
ITEM_PIPELINES = { 'fang.pipelines.FangPipeline': 300, }
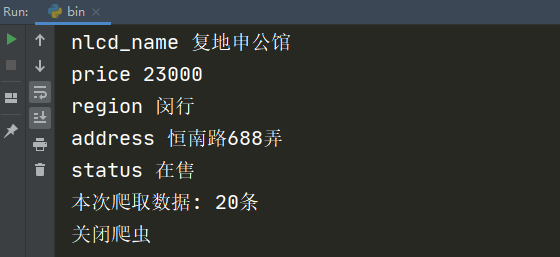
执行bin.py,启动爬虫项目,效果如下:
查看文件fang_pipline.json,内容如下:
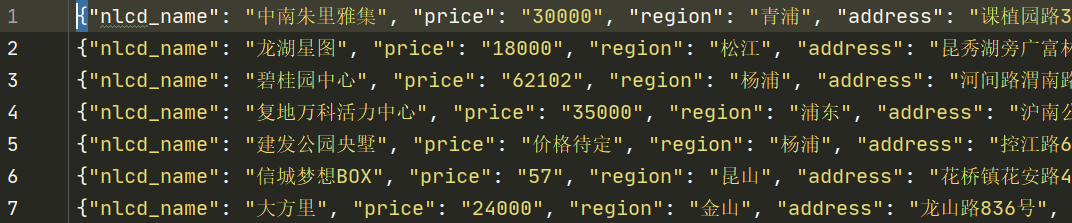
注意:本次访问的页面,只有6页,每页20条结果。因此可以获取到120条信息。
本文参考链接:
https://www.cnblogs.com/bk9527/p/10504883.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2018-09-17 python 全栈开发,Day127(app端内容播放,web端的玩具,app通过websocket远程遥控玩具播放内容,玩具管理页面)