Splash抓取jd
一、概述
在上一篇文章中,链接如下:https://www.cnblogs.com/xiao987334176/p/13656055.html
已经介绍了如何使用Splash抓取javaScript动态渲染页面
这里做一下项目实战,以爬取京东商城商品冰淇淋为例吧
环境说明
操作系统:centos 7.6
docker版本:19.03.12
ip地址:192.168.0.10
说明:使用docker安装Splash服务
操作系统:windows 10
python版本:3.7.9
ip地址:192.168.0.9
说明:使用Pycharm开发工具,用于本地开发。
关于Splash的使用,参考上一篇文章,这里就不做说明了。
二、分析页面
打开京东商城,输入关键字:冰淇淋,滑动滚动条,我们发现随着滚动条向下滑动,越来越多的商品信息被刷新了,这说明该页面部分是ajax加载
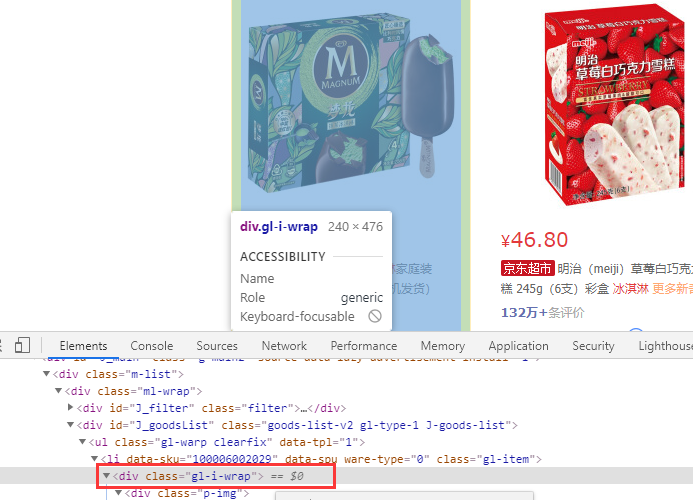
注意:每一条商品信息,都是在<div class="gl-i-wrap"></div>里面的。
我们打开scrapy shell 爬取该页面,如下图:
scrapy shell "https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8"
输出:
... [s] view(response) View response in a browser >>>
注意:url不要用单引号,否则会报错。
接下来,输入以下命令,使用css选择器
>>> response.css('div.gl-i-wrap') [<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' ' ), ' gl-i-wrap ')]" ...
返回了很多Selector 对象。
统计商品信息个数
>>> len(response.css('div.gl-i-wrap'))
30
得到返回结果发现只有30个冰淇凌的信息,而我们再页面中明明看见了60个冰淇凌信息,这是为什么呢?
答:这也说明了刚开始页面只用30个冰淇淋信息,而我们滑动滑块时,执行了js代码,并向后台发送了ajax请求,浏览器拿到数据后再进一步渲染出另外了30个信息
我们可以点击network选项卡再次确认:
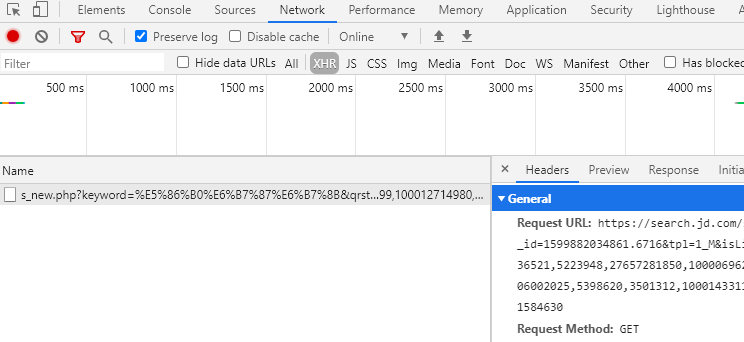
鉴于此,我们就想出了一种解决方案:即用js代码模拟用户滑动滑块到底的行为再结合execute端点提供的js代码执行服务即可(小伙伴们让我们开始实践吧)

注意:<div id="footer-2017"></div>就是页面底部了,因此,只需要滑动到底部即可。
首先:模拟用户行为
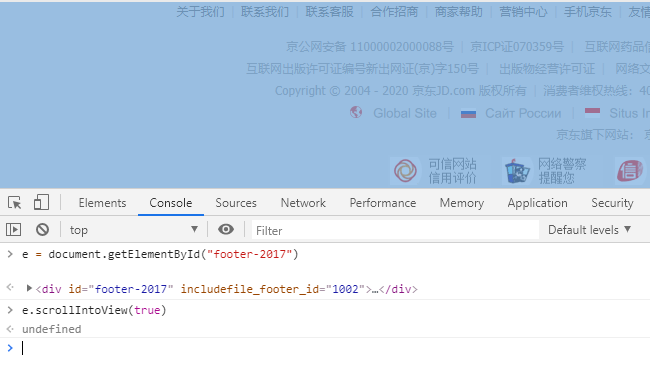
在console,输入以下命令:
e = document.getElementById("footer-2017") e.scrollIntoView(true)
效果如下,就直接滑动到底部了。
参数解释:
scrollIntoView是一个与页面(容器)滚动相关的API(官方解释),该API只有boolean类型的参数能得到良好的支持(firefox 36+都支持)
参数为true时调用该函数,页面(或容器)发生滚动,使element的顶部与视图(容器)顶部对齐;
使用scrapy.Request
上面我们使用Request发送请求,观察结果只有30条。为什么呢?因为页面时动态加载的所有我们只收到了30个冰淇淋的信息。
所以这里,使用scrapy.Request发送请求,并使用execute 端点解决这个问题。
打开上一篇文章中的爬虫项目dynamic_page,使用Pycharm打开,并点开Terminal
输入dir,确保当前目录是dynamic_page

(crawler) E:\python_script\爬虫\dynamic_page>dir 驱动器 E 中的卷是 file 卷的序列号是 1607-A400 E:\python_script\爬虫\dynamic_page 的目录 2020/09/12 10:37 <DIR> . 2020/09/12 10:37 <DIR> .. 2020/09/12 10:20 211 bin.py 2020/09/12 14:30 0 dynamicpage_pipline.json 2020/09/12 10:36 <DIR> dynamic_page 2020/09/12 10:33 0 result.csv 2020/09/12 10:18 267 scrapy.cfg 4 个文件 478 字节 3 个目录 260,445,159,424 可用字节
接下来打开scrapy shell,输入命令:
scrapy shell
输出:
... [s] view(response) View response in a browser >>>
最后粘贴以下代码:
from scrapy_splash import SplashRequest #使用scrapy.splash.Request发送请求 url = "https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8" lua = ''' function main(splash) splash:go(splash.args.url) splash:wait(3) splash:runjs("document.getElementById('footer-2017').scrollIntoView(true)") splash:wait(3) return splash:html() end ''' fetch(SplashRequest(url,endpoint = 'execute',args= {'lua_source':lua})) #再次请求,我们可以看到现在已通过splash服务的8050端点渲染了js代码,并成果返回结果 len(response.css('div.gl-i-wrap'))
效果如下:
[s] view(response) View response in a browser >>> from scrapy_splash import SplashRequest #使用scrapy.splash.Request发送请求 >>> url = 'https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8' >>> lua = ''' ... function main(splash) ... splash:go(splash.args.url) ... splash:wait(3) ... splash:runjs("document.getElementById('footer-2017').scrollIntoView(true)") ... splash:wait(3) ... return splash:html() ... end ... ''' >>> fetch(SplashRequest(url,endpoint = 'execute',args= {'lua_source':lua})) #再次请求,我们可以看到现 在已通过splash服务的8050端点渲染了js代码,并成果返回结果 2020-09-12 14:30:54 [scrapy.core.engine] INFO: Spider opened 2020-09-12 14:30:54 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://w ww.jd.com/error.aspx> from <GET https://search.jd.com/robots.txt> 2020-09-12 14:30:55 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.jd.com/error.aspx> (ref erer: None) 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 27 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 83 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 92 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 202 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 351 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 375 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 376 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 385 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 386 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 387 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 388 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 389 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 397 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 400 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 403 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 404 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 405 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 406 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 407 without any user agent to enforce it on. 2020-09-12 14:30:55 [protego] DEBUG: Rule at line 408 without any user agent to enforce it on. 2020-09-12 14:30:55 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://192.168.0.10:8050/robots.txt > (referer: None) 2020-09-12 14:31:10 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://search.jd.com/Search?keywor d=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8 via http://192.168.0.10:8050/execute> (referer: None) >>> len(response.css('div.gl-i-wrap')) 60
注意:由于fetch不能直接在python代码中执行,所以只能在scrapy shell 模式中执行。
最后的任务就回归到了提取内容了阶段了,小伙伴让我们完成整个代码吧!---这里结合scrapy shell 进行测试
三、代码实现
新建项目
这里对目录就没有什么要求了,找个空目录就行。
打开Pycharm,并打开Terminal,执行以下命令
scrapy startproject ice_cream
cd ice_cream
scrapy genspider jd search.jd.com
在scrapy.cfg同级目录,创建bin.py,用于启动Scrapy项目,内容如下:
#在项目根目录下新建:bin.py from scrapy.cmdline import execute # 第三个参数是:爬虫程序名 execute(['scrapy', 'crawl', 'jd',"--nolog"])
创建好的项目树形目录如下:
./ ├── bin.py ├── ice_cream │ ├── __init__.py │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── settings.py │ └── spiders │ ├── __init__.py │ └── jd.py └── scrapy.cfg
修改settIngs.py
改写settIngs.py文件这里小伙伴们可参考github(https://github.com/scrapy-plugins/scrapy-splash)---上面有详细的说明
在最后添加如下内容:
# Splash服务器地址 SPLASH_URL = 'http://192.168.0.10:8050' # 开启两个下载中间件,并调整HttpCompressionMiddlewares的次序 DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, } # 设置去重过滤器 DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' # 用来支持cache_args(可选) SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100, } DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage' ITEM_PIPELINES = { 'ice_cream.pipelines.IceCreamPipeline': 100, }
注意:请根据实际情况,修改Splash服务器地址,其他的不需要改动。
修改文件jd.py


# -*- coding: utf-8 -*- import scrapy from scrapy_splash import SplashRequest from ice_cream.items import IceCreamItem #自定义lua脚本 lua = ''' function main(splash) splash:go(splash.args.url) splash:wait(3) splash:runjs("document.getElementById('footer-2017').scrollIntoView(true)") splash:wait(3) return splash:html() end ''' class JdSpider(scrapy.Spider): name = 'jd' allowed_domains = ['search.jd.com'] start_urls = ['https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8'] base_url = 'https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8' # 自定义配置,注意:变量名必须是custom_settings custom_settings = { 'REQUEST_HEADERS': { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36', } } def parse(self, response): # 这里能获取100页 page_num = int(response.css('span.fp-text i::text').extract_first()) # 但是100页太多了,这里固定为2页 page_num = 2 # print("page_num", page_num) for i in range(page_num): url = '%s?page=%s' % (self.base_url, 2 * i + 1) # 通过观察我们发现url页面间有规律 # print("url", url) yield SplashRequest(url, headers=self.settings.get('REQUEST_HEADERS'), endpoint='execute', args={'lua_source': lua}, callback=self.parse_item) def parse_item(self, response): # 页面解析函数 # 创建item字段对象,用来存储信息 item = IceCreamItem() for sel in response.css('div.gl-i-wrap'): name = sel.css('div.p-name em').extract_first() price = sel.css('div.p-price i::text').extract_first() # print("name", name) # print("price", price) item['name'] = name item['price'] = price yield item # yield { # 'name': name, # 'price': price, # }
修改items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class IceCreamItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 与itcast.py定义的一一对应 name = scrapy.Field() price = scrapy.Field()
修改pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import json class IceCreamPipeline(object): def __init__(self): #python3保存文件 必须需要'wb' 保存为json格式 self.f = open("ice_cream_pipline.json",'wb') def process_item(self, item, spider): # 读取item中的数据 并换行处理 content = json.dumps(dict(item), ensure_ascii=False) + ',\n' self.f.write(content.encode('utf=8')) return item def close_spider(self,spider): #关闭文件 self.f.close()
执行bin.py,等待1分钟,就会生成文件ice_cream_pipline.json
打开json文件,内容如下:
{"name": "<em><span class=\"p-tag\" style=\"background-color:#c81623\">京东超市</span>\t\n明治(meiji)草莓白巧克力雪糕 245g(6支)彩盒 <font class=\"skcolor_ljg\">冰淇淋</font></em>", "price": "46.80"},
{"name": "<em><span class=\"p-tag\" style=\"background-color:#c81623\">京东超市</span>\t\n伊利 巧乐兹香草巧克力口味脆皮甜筒雪糕<font class=\"skcolor_ljg\">冰淇淋</font>冰激凌冷饮 73g*6/盒</em>", "price": "32.80"},
...
本文参考链接:
https://www.cnblogs.com/518894-lu/p/9067208.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2019-09-08 python代码执行SQL文件(逐句执行)