Splash抓取javaScript动态渲染页面
一、概述
Splash是一个javascript渲染服务。它是一个带有HTTP API的轻量级Web浏览器,使用Twisted和QT5在Python 3中实现。QT反应器用于使服务完全异步,允许通过QT主循环利用webkit并发。
一些Splash功能:
- 并行处理多个网页
- 获取HTML源代码或截取屏幕截图
- 关闭图像或使用Adblock Plus规则使渲染更快
- 在页面上下文中执行自定义JavaScript
- 可通过Lua脚本来控制页面的渲染过程
- 在Splash-Jupyter 笔记本中开发Splash Lua脚本。
- 以HAR格式获取详细的渲染信息
二、Scrapy-Splash的安装
Scrapy-Splash的安装分为两部分,一个是Splash服务的安装,具体通过Docker来安装服务,运行服务会启动一个Splash服务,通过它的接口来实现JavaScript页面的加载;另外一个是Scrapy-Splash的Python库的安装,安装后就可在Scrapy中使用Splash服务了。
环境说明
操作系统:centos 7.6
docker版本:19.03.12
ip地址:192.168.0.10
说明:使用docker安装Splash服务
操作系统:windows 10
python版本:3.7.9
ip地址:192.168.0.9
说明:使用Pycharm开发工具,用于本地开发。
安装splash服务
通过Docker安装Scrapinghub/splash镜像,然后启动容器,创建splash服务
docker pull scrapinghub/splash docker run -d --name splash -p 8050:8050 scrapinghub/splash
Python包Scrapy-Splash安装
pip3 install scrapy-splash
plash Lua脚本
运行splash服务后,通过web页面访问服务的8050端口
http://192.168.0.10:8050/
即可看到其web页面,如下图:

上面有个输入框,默认是http://google.com,我们可以换成想要渲染的网页如:https://www.baidu.com然后点击Render me按钮开始渲染

但是,等了许久,一直是Initializing...状态。不管它了,可能有bug
登录centos系统,使用curl命令测试,访问百度
curl 'http://localhost:8050/render.html?url=https://www.baidu.com/page-with-javascript.html&timeout=10&wait=0.5'
它会返回一段html代码,说明渲染是没有问题的。
三、示例页面分析
这里我们可以观察一个典型的供我们练习爬虫技术的网站:quotes.toscrape.com/js/

说明:这里是一个留意列表,都在<div class="quote">里面。
接下来使用scrapy命令来分析一下,打开Pycharm,打开Terminal,输入以下命令:
scrapy shell http://quotes.toscrape.com/js/
输出如下:
... [s] view(response) View response in a browser >>>
然后输入: response.css('div.quote')
>>> response.css('div.quote') [] >>>
代码分析:这里我们爬取了该网页,但我们通过css选择器爬取页面每一条名人名言具体内容时发现没有返回值
我们来看看页面:这是由于每一条名人名言是通过客户端运行一个Js脚本动态生成的。
我们将script脚本打开看看发现这里包含了每一条名人名言的具体信息

注意:在<div class="quote">上面一个标签,也就是<script></script>里面,就可以看到。
问题分析
scrapy爬虫框架没有提供页面js渲染服务,所以我们获取不到信息,所以我们需要一个渲染引擎来为我们提供渲染服务---这就是Splash渲染引擎(大侠出场了)
1、Splash渲染引擎简介:
Splash是为Scrapy爬虫框架提供渲染javascript代码的引擎,它有如下功能:(摘自维基百科)
(1)为用户返回渲染好的html页面
(2)并发渲染多个页面
(3)关闭图片加载,加速渲染
(4)执行用户自定义的js代码
(5)执行用户自定义的lua脚步,类似于无界面浏览器phantomjs
2、Splash渲染引擎工作原理:(我们来类比就一清二楚了)
这里我们假定三个小伙伴:(1--懒惰的我 , 2 --提供外卖服务的小哥,3---本人喜欢吃的家味道餐饮点)
今天正好天气不好,1呆在宿舍睡了一早上起来,发现肚子饿了,它就想去自己爱吃的家味道餐饮点餐,他在床上大喊一声我要吃大鸡腿,但3并没有返回东西给他,这是后怎么办呢,2出场了,1打来自己了饿了吗APP点了一份荷叶饭,这是外卖小哥收到订单,就为他去3那,拿了他爱吃的荷叶饭给了1,1顿时兴高采烈!

Client----相当于1 /Splash---相当于2 /Web server---相当于3
即:我们将下载请求告诉Splash ,然后Splash帮我们去下载并渲染页面,最后将渲染好的页面返回给我们
Splash简要使用说明
render.html端点
Splash为我们提供了多种端点的服务,具体参见http://splash.readthedocs.io/en/stable/api.html#render-html
1、下面我们以render.html端点来体验下:(这里我们使用requests库)
实验:
在Pycharm里,新建一个test.py,代码如下:

import requests from scrapy.selector import Selector splash_url = 'http://192.168.0.10:8050/render.html' args = {'url': 'http://quotes.toscrape.com/js', 'timeout': 10, 'image': 0} response = requests.get(splash_url, params=args) sel = Selector(response) ret = sel.css('div.quote span.text::text').extract() print(type(ret)) for i in ret: print(i)
执行输出:
<class 'list'> “The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” ...
可以发现,这里已经得到留言列表了。
sel.css('div.quote span.text::text') 这里表示使用css选择器,div.quote表:div下的class为:quote 。span.text::text表示:span下的class为:text,并提取text文本信息。相当于jquery里面的text()。这里有点绕,可能有点不太好理解。

它相当于jquery代码
$('div.quote span.text').text()
使用console,测试一下
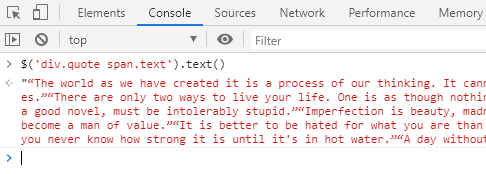
你看,它真的得到了留言列表。
execute端点
2、下面我们来介绍另一个重要的端点:execute端点
execute端点简介:它被用来提供如下服务:当用户想在页面中执行自己定义的Js代码,如:用js代码模拟浏览器进行页面操作(滑动滚动条啊,点击啊等等)
这里:我们将execute看成是一个可以模拟用户行为的浏览器,而用户的行为我们通过lua脚本进行定义:
比如:
打开url页面
等待加载和渲染
执行js代码
获取http响应头部
获取cookies
实验:
使用Pycharm新建一个test1.py,内容如下:
import requests import json #编写lua脚本,:访问属性 lua = ''' function main(splash) --打开页面 splash:go('http:example.com') --等待加载 splash:wait(0.5) --执行js代码 local title = splash:evaljs('document.title') --{中的内容类型python中的键值对} return {title = title} end ''' splash_url = 'http://192.168.0.10:8050/execute' #定义端点地址 headers = {'content-type':'application/json'} data = json.dumps({'lua_source':lua}) #做成json对象 response = requests.post(splash_url,headers = headers,data=data) #使用post请求 ret = response.content ret1 = response.json() print(ret) print(ret1)
执行输出:
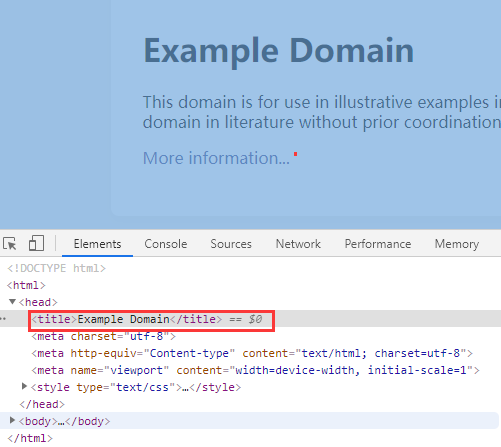
b'{"title": "Example Domain"}' {'title': 'Example Domain'}
注意:它是访问http://example.com/,提取title标签对的文字。刚开始,我以为这个网站打不开,没想到,居然可以打开。
Splash对象常用属性和方法总结:参考官网http://splash.readthedocs.io/en/stable/scripting-overview.html#和书本
splash:args属性----传入用户参数的表,通过该属性可以访问用户传入的参数,如splash.args.url、splash.args.wait
spalsh.images_enabled属性---用于开启/禁止图片加载,默认值为True
splash:go方法---请求url页面
splash:wait方法---等待渲染的秒数
splash:evaljs方法---在当前页面下,执行一段js代码,并返回最后一句表达式的值
splash:runjs方法---在当前页面下,执行一段js代码
splash:url方法---获取当前页面的url
splash:html方法---获取当前页面的HTML文档
splash:get_cookies---获取cookies信息
四、在Scrapy 中使用Splash
在scrapy_splash中定义了一个SplashRequest类,用户只需使用scrapy_splash.SplashRequst来替代scrapy.Request发送请求
该构造器常用参数如下:
url---待爬取的url地址
headers---请求头
cookies---cookies信息
args---传递给splash的参数,如wait\timeout\images\js_source等
cache_args--针对参数重复调用或数据量大大情况,让Splash缓存该参数
endpoint---Splash服务端点
splash_url---Splash服务器地址,默认为None
实验:https://github.com/scrapy-plugins/scrapy-splash(这里有很多使用例子供大家学习)
新建项目
打开Pycharm,并打开Terminal,执行以下命令
scrapy startproject dynamic_page
cd dynamic_page
scrapy genspider quotes quotes.toscrape.com
在scrapy.cfg同级目录,创建bin.py,用于启动Scrapy项目,内容如下:
#在项目根目录下新建:bin.py from scrapy.cmdline import execute # 第三个参数是:爬虫程序名 execute(['scrapy', 'crawl', 'quotes',"--nolog"])
创建好的项目树形目录如下:
./
├── bin.py
├── dynamic_page
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── quotes.py
└── scrapy.cfg
修改settIngs.py
改写settIngs.py文件这里小伙伴们可参考github(https://github.com/scrapy-plugins/scrapy-splash)---上面有详细的说明
在最后添加如下内容:
# Splash服务器地址 SPLASH_URL = 'http://192.168.0.10:8050' # 开启两个下载中间件,并调整HttpCompressionMiddlewares的次序 DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, } # 设置去重过滤器 DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' # 用来支持cache_args(可选) SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100, } DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage' ITEM_PIPELINES = { 'dynamic_page.pipelines.DynamicPagePipeline': 100, }
注意:请根据实际情况,修改Splash服务器地址,其他的不需要改动。
修改文件quotes.py


# -*- coding: utf-8 -*- import scrapy from scrapy_splash import SplashRequest #重新定义了请求 from dynamic_page.items import DynamicPageItem class QuotesSpider(scrapy.Spider): name = 'quotes' allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/js/'] def start_requests(self): # 重新定义起始爬取点 for url in self.start_urls: yield SplashRequest(url, args={'timeout': 8, 'images': 0}) def parse(self, response): authors = response.css('div.quote small.author::text').extract() # 选中名人并返回一个列表 quotes = response.css('div.quote span.text::text').extract() # 选中名言并返回一个列表 # 创建item字段对象,用来存储信息 item = DynamicPageItem() item['authors'] = authors item['quotes'] = quotes ##使用zip()函数--小伙伴们自行百度菜鸟教程即可 # 构造了一个元祖再进行遍历,再次使用zip结合dict构造器做成了列表,由于yield ,所以我们使用生成器解析返回 yield from (dict(zip(['author', 'quote'], item)) for item in zip(authors, quotes)) next_url = response.css('ul.pager li.next a::attr(href)').extract_first() if next_url: complete_url = response.urljoin(next_url) # 构造了翻页的绝对url地址 yield SplashRequest(complete_url, args={'timeout': 8, 'images': 0})
修改items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class DynamicPageItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 与itcast.py定义的一一对应 authors = scrapy.Field() quotes = scrapy.Field()
修改pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import json class DynamicPagePipeline(object): def __init__(self): #python3保存文件 必须需要'wb' 保存为json格式 self.f = open("dynamicpage_pipline.json",'wb') def process_item(self, item, spider): # 读取item中的数据 并换行处理 content = json.dumps(dict(item), ensure_ascii=False) + ',\n' self.f.write(content.encode('utf=8')) return item def close_spider(self,spider): #关闭文件 self.f.close()
执行bin.py,等待1分钟,就会生成文件dynamicpage_pipline.json。
打开json文件,内容如下:
{"author": "Albert Einstein", "quote": "“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”"},
{"author": "J.K. Rowling", "quote": "“It is our choices, Harry, that show what we truly are, far more than our abilities.”"},
...
本文参考链接:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2018-09-07 python 全栈开发,Day121(DButils,websocket)