kafka介绍与搭建(单机版)
一、kafka介绍
1.1 主要功能
根据官网的介绍,ApacheKafka®是一个分布式流媒体平台,它主要有3种功能:
1:It lets you publish and subscribe to streams of records.发布和订阅消息流,这个功能类似于消息队列,这也是kafka归类为消息队列框架的原因
2:It lets you store streams of records in a fault-tolerant way.以容错的方式记录消息流,kafka以文件的方式来存储消息流
3:It lets you process streams of records as they occur.可以再消息发布的时候进行处理
1.2 使用场景
1:Building real-time streaming data pipelines that reliably get data between systems or applications.在系统或应用程序之间构建可靠的用于传输实时数据的管道,消息队列功能
2:Building real-time streaming applications that transform or react to the streams of data。构建实时的流数据处理程序来变换或处理数据流,数据处理功能
1.3 详细介绍
Kafka目前主要作为一个分布式的发布订阅式的消息系统使用,下面简单介绍一下kafka的基本机制
1.3.1 消息传输流程
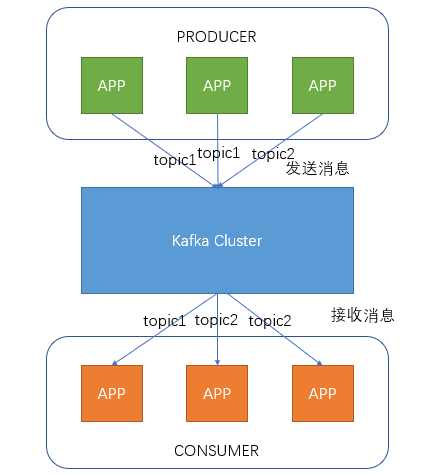
Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即Topic,上图展示了两个producer发送了分类为topic1的消息,另外一个发送了topic2的消息。
- Topic即主题,通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息
- Consumer即消费者,消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
从上图中就可以看出同一个Topic下的消费者和生产者的数量并不是对应的。
1.3.2 kafka服务器消息存储策略

谈到kafka的存储,就不得不提到分区,即partitions,创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。
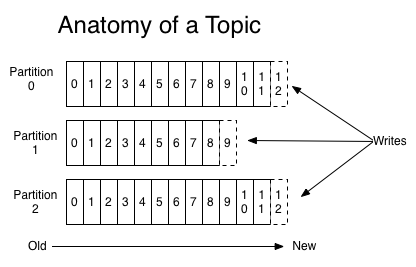
在每个分区中,消息以顺序存储,最晚接收的的消息会最后被消费。
1.3.3 与生产者的交互

生产者在向kafka集群发送消息的时候,可以通过指定分区来发送到指定的分区中
也可以通过指定均衡策略来将消息发送到不同的分区中
如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中
1.3.4 与消费者的交互
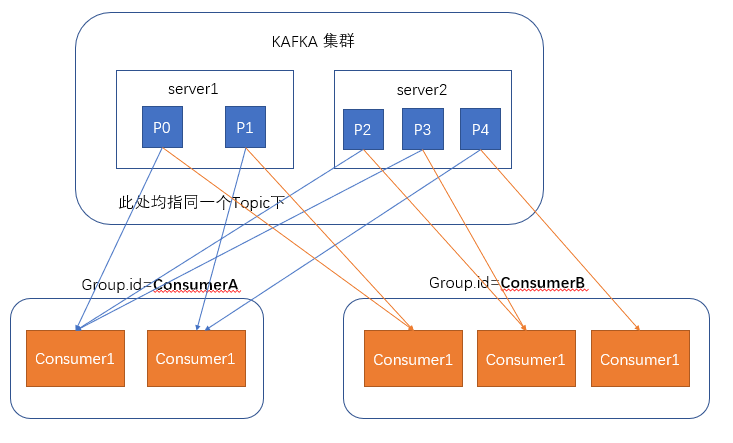
在消费者消费消息时,kafka使用offset来记录当前消费的位置
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的的消费的记录位置offset各不相同,不互相干扰。
对于一个group而言,消费者的数量不应该多余分区的数量,因为在一个group中,每个分区至多只能绑定到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费
因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
二、Kafka安装与使用
2.1 下载
你可以在kafka官网 http://kafka.apache.org/downloads下载到最新的kafka安装包,选择下载二进制版本的tgz文件,这里我们选择的版本是2.12-2.1.0,目前的最新版
2.2 安装
Kafka是使用scala编写的运行与jvm虚拟机上的程序,虽然也可以在windows上使用,但是kafka基本上是运行在linux服务器上,因此我们这里也使用linux来开始今天的实战。
首先确保你的机器上安装了jdk,kafka需要java运行环境,以前的kafka还需要zookeeper,新版的kafka已经内置了一个zookeeper环境,实验环境可以直接使用
说是安装,如果只需要进行最简单的尝试的话我们只需要解压到任意目录即可,这里我们将kafka压缩包解压到 / 目录
2.3 配置
在kafka解压目录下下有一个config的文件夹,里面放置的是我们的配置文件
- consumer.properites 消费者配置,这个配置文件用于配置于2.5节中开启的消费者,此处我们使用默认的即可
- producer.properties 生产者配置,这个配置文件用于配置于2.5节中开启的生产者,此处我们使用默认的即可
- server.properties kafka服务器的配置,此配置文件用来配置kafka服务器
目前仅介绍几个最基础的配置
- broker.id 申明当前kafka服务器在集群中的唯一ID,需配置为integer,并且集群中的每一个kafka服务器的id都应是唯一的,我们这里采用默认配置即可
- listeners 申明此kafka服务器需要监听的端口号,如果是在本机上跑虚拟机运行可以不用配置本项,默认会使用localhost的地址,如果是在远程服务器上运行则必须配置,例如:
listeners=PLAINTEXT://192.168.91.129:9092。并确保服务器的9092端口能够访问
- zookeeper.connect 申明kafka所连接的zookeeper的地址 ,需配置为zookeeper的地址,如果使用的是kafka高版本中自带zookeeper,使用默认配置即可。本文使用的是自己搭建的zookeeper,例如: zookeeper.connect=192.168.91.128:2181
基于docker 安装
环境说明
| 操作系统 | IP地址 | 角色 | 软件版本 |
| ubuntu-16.04.5-server-amd64 | 192.168.91.128 | zookeeper | 3.4.13 |
| ubuntu-16.04.5-server-amd64 | 192.168.91.129 | Kafka_server | 2.12-2.1.0 |
| ubuntu-16.04.5-server-amd64 | 192.168.91.131 | Kafka_client | 2.12-2.1.0 |
安装zookeeper
关于 zookeeper 的安装,请参考链接:
https://www.cnblogs.com/xiao987334176/p/10037490.html
安装kafka_server
新建空目录
mkdir /opt/kafka_server_base
dockerfile
内容如下:

FROM ubuntu:16.04 # 修改更新源为阿里云 ADD sources.list /etc/apt/sources.list ADD kafka_2.12-2.1.0.tgz / # 安装jdk RUN apt-get update && apt-get install -y openjdk-8-jdk --allow-unauthenticated && apt-get clean all EXPOSE 9092 # 添加启动脚本 ADD run.sh . RUN chmod 755 run.sh ENTRYPOINT [ "/run.sh"]
run.sh
内容如下:
#!/bin/bash if [ -z $zookeeper ];then echo "zookeeper变量不能为空" exit 2 fi cd /kafka_2.12-2.1.0 # 设置zookeeper连接地址 sed -i "123s/localhost/$zookeeper/" /kafka_2.12-2.1.0/config/server.properties # 设置外部访问地址,绑定域名。注意:此域名必须被docker解析 echo " advertised.listeners=PLAINTEXT://kafka-1.default.svc.cluster.local:9092 " >> /kafka_2.12-2.1.0/config/server.properties # 获取docker ip ip=`cat /etc/hosts | tail -1 | awk '{print $1}'` # 增加hosts,方便解析域名 echo "$ip kafka-1.default.svc.cluster.local" >> /etc/hosts # 启动kafka bin/kafka-server-start.sh config/server.properties
注意:
特别要注意 listeners 参数,不能是0.0.0.0,否则启动报错!必须是IP地址或者为空。如果是IP地址,客户端连接时,必须和它是同样的ip,否则报错。默认就是保持为空
listeners=PLAINTEXT://:9092
它会监听本机的所有IP地址。但是,一旦这样,即使进入docker容器,使用127.0.0.1:9092也无法正常操作。它必须配合另外一个参数advertised.listeners
advertised.listeners 是用来设置外部访问地址,推荐使用域名。这里使用域名kafka-1.default.svc.cluster.local,注意:使用域名时,docker必须要求能够解析,否则客户端操作时,会报错。
所以在run.sh中,添加了一条hosts记录。默认情况下,/etc/hosts最后一行的ip就是docker的ip地址。
sources.list
内容如下:
deb http://mirrors.aliyun.com/ubuntu/ xenial main deb-src http://mirrors.aliyun.com/ubuntu/ xenial main deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main deb http://mirrors.aliyun.com/ubuntu/ xenial universe deb-src http://mirrors.aliyun.com/ubuntu/ xenial universe deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universe deb http://mirrors.aliyun.com/ubuntu/ xenial-security main deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe
此时,/opt/kafka_server 目录结构如下:
./ ├── dockerfile ├── kafka_2.12-2.1.0.tgz ├── run.sh └── sources.list
创建镜像
docker build -t kafka_server_base /opt/kafka_server_base
启动kafka
docker run -it -p 9092:9092 -e zookeeper=172.17.0.2 kafka_server_base
注意:172.17.0.2 是zookeeper的容器地址
查看9092端口是否启动
root@jqb-node129:/opt/kafka_danji# netstat -anpt Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1392/sshd tcp6 0 0 :::22 :::* LISTEN 1392/sshd tcp6 0 0 :::9092 :::* LISTEN 10291/java
安装kafka_client
安装kafka客户端就比较简单了,直接解压压缩包,使用里面的shell脚本即可,配置文件不需要修改,使用默认即可!
dockerfile
内容如下:
FROM ubuntu:16.04 # 修改更新源为阿里云 ADD sources.list /etc/apt/sources.list ADD kafka_2.12-2.1.0.tgz / # 安装jdk RUN apt-get update && apt-get install -y openjdk-8-jdk --allow-unauthenticated && apt-get clean all # 添加启动脚本 ADD run.sh . RUN chmod 755 run.sh ENTRYPOINT [ "/run.sh"]
run.sh
内容如下:
#!/bin/bash tail -f /kafka_2.12-2.1.0/NOTICE
sources.list
内容如下:
deb http://mirrors.aliyun.com/ubuntu/ xenial main deb-src http://mirrors.aliyun.com/ubuntu/ xenial main deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main deb http://mirrors.aliyun.com/ubuntu/ xenial universe deb-src http://mirrors.aliyun.com/ubuntu/ xenial universe deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universe deb http://mirrors.aliyun.com/ubuntu/ xenial-security main deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe
此时 /opt/kafka_client 目录结构如下:
./ ├── dockerfile ├── kafka_2.12-2.1.0.tgz ├── run.sh └── sources.list
创建镜像
docker build -t kafka_client /opt/kafka_client
启动kafka_client
docker run -d -it kafka_client /bin/bash
查看docker进程
root@jqb-node131:/opt/kafka_client# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e07fd7d20814 kafka_client_test "/run.sh /bin/bash" 4 minutes ago Up 4 minutes epic_bardeen
进入 docker
root@jqb-node131:/opt/kafka_client# docker exec -it e07fd7d20814 /bin/bash root@e07fd7d20814:/#
添加一条hosts记录
echo "172.17.0.2 kafka-1.default.svc.cluster.local" >> /etc/hosts
2.5 创建第一个消息
2.5.1 创建一个topic
Kafka通过topic对同一类的数据进行管理,同一类的数据使用同一个topic可以在处理数据时更加的便捷
创建一个测试topic,名为test,单分区,副本因子是1
root@e07fd7d20814:/# cd /kafka_2.12-2.1.0/ root@e07fd7d20814:/kafka_2.12-2.1.0# bin/kafka-topics.sh --create --zookeeper 192.168.91.128:2181 --topic test --partitions 1 --replication-factor 1 Created topic "test".
在创建topic后可以通过输入以下命令,来查看已经创建的topic
root@e07fd7d20814:/kafka_2.12-2.1.0# bin/kafka-topics.sh --list --zookeeper 192.168.91.128:2181 test
2.4.2 创建一个消息生产者
打开一个新的终端,重新进入docker
root@jqb-node131:/opt/kafka_client# docker exec -it e07fd7d20814 /bin/bash root@e07fd7d20814:/#
接下来我们创建第一个消息生产者,输入hello
root@e07fd7d20814:/kafka_2.12-2.1.0# bin/kafka-console-producer.sh --broker-list 192.168.91.129:9092 --topic test >hello >
2.4.3 创建一个消息消费者
root@e07fd7d20814:/kafka_2.12-2.1.0# bin/kafka-console-consumer.sh --bootstrap-server 192.168.91.129:9092 --topic test --from-beginning
消费者创建完成之后,因为还没有发送任何数据,因此这里在执行后没有打印出任何数据
不过别着急,不要关闭这个终端,它会一直hold住
在发送完消息之后,可以回到我们的消息消费者终端中,可以看到,终端中已经打印出了我们刚才发送的消息hello
root@e07fd7d20814:/kafka_2.12-2.1.0# bin/kafka-console-consumer.sh --bootstrap-server 192.168.91.129:9092 --topic test --from-beginning hello
kafka错误解决
[2018-12-13 14:29:58,771] ERROR Error when sending message to topic test with key: null, value: 4 bytes with error: (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback) org.apache.kafka.common.errors.TimeoutException: Expiring 1 record(s) for test-0: 1537 ms has passed since batch creation plus linger time
出现上面的错误,表示listeners配置和当前连接不匹配。
就如上面提到的,如果listeners指定了监听ip,客户端连接时,也必须是这个ip地址,否则会出现上面的提示。
[2018-12-13 14:35:18,017] WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 1 : {test=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
出现此错误,表示客户端无法解析advertised.listeners配置的域名,这个时候,添加hosts就可以解决了!
三、使用python操作kafka
使用python操作kafka目前比较常用的库是kafka-python库
安装kafka-python
pip3 install kafka-python
生产者
producer_test.py
from kafka import KafkaProducer producer = KafkaProducer(bootstrap_servers='192.168.0.121:9092') # 连接kafka msg = "Hello World".encode('utf-8') # 发送内容,必须是bytes类型 producer.send('test', msg) # 发送的topic为test producer.close()
执行此程序,它没有输出!这个是正常的
消费者
from kafka import KafkaConsumer consumer = KafkaConsumer('test', bootstrap_servers=['192.168.0.121:9092']) for msg in consumer: recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value) print(recv)
执行此程序,此时会hold住,因为它在等待生产者发送消息!
再次执行生产者,此时会输出:
test:0:9: key=None value=b'Hello World'
本文参考链接:
https://www.cnblogs.com/hei12138/p/7805475.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix