《python编程锦囊》之网络爬虫
1、对中国天气预报网站爬虫
在使用python实现爬取某些动态加载的信息时,经常会出现找到了动态加载的json请求地址,但是直接访问该地址却反悔403错误的现象,解决这一问题的方法就是将该网页的“Referer”和“User-Agent”的信息提取并设置。
#!/usr/bin/env python3 #导入网络请求模块 import requests #导入Json模块 import json #头部信息,需要设置网络工具中提取的重要信息“User-Agent”和“Referer” headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36'\ '(KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36',\ 'Referer':'http://www.weather.com.cn/weather1d/101010100.shtml'} #网络请求网址 url = 'http://d1.weather.com.cn/sk_2d/101010100.html?_=1555986533582' #发送网络请求 response = requests.get(url,headers = headers) #判断请求是否成功 if response.status_code==200: #编码返回信息 response.encoding = 'utf-8' #将json字符串中“var dataSK =”去除 print('发送网页请求,返回的网页内容:',response.text) json_str = response.text.replace('var dataSK =','') print('解码前,返回的json类型:',json_str) #将json字符串转换为字典类型 json_info = json.loads(json_str) #打印当前的字典 print('解码后,返回的字典类型:',json_info) #打印城市 print('城市:',json_info['cityname']) #打印温度 print('当前温度:',json_info['temp']) #打印湿度 print('相对湿度:',json_info['SD']) #打印风向等级 print('风向等级:',json_info['WD'],json_info['WS']) #打印空气质量 print('空气质量pm2.5:',json_info['aqi_pm25']) #打印车辆限号 print('车辆限号为:',json_info['limitnumber'])
结果:
发送网页请求,返回的网页内容: var dataSK = {"nameen":"beijing","cityname":"北京","city":"101010100","temp":"18","tempf":"64","WD":"西风","wde":"W","WS":"3级","wse":"<12km/h","SD":"53%","time":"18:22","weather":"多云","weathere":"Cloudy","weathercode":"d01","qy":"1002","njd":"8.93km","sd":"53%","rain":"0.0","rain24h":"0","aqi":"67","limitnumber":"不限行","aqi_pm25":"67","date":"04月19日(星期日)"}
解码前,返回的json类型: {"nameen":"beijing","cityname":"北京","city":"101010100","temp":"18","tempf":"64","WD":"西风","wde":"W","WS":"3级","wse":"<12km/h","SD":"53%","time":"18:22","weather":"多云","weathere":"Cloudy","weathercode":"d01","qy":"1002","njd":"8.93km","sd":"53%","rain":"0.0","rain24h":"0","aqi":"67","limitnumber":"不限行","aqi_pm25":"67","date":"04月19日(星期日)"}
解码后,返回的字典类型: {'nameen': 'beijing', 'cityname': '北京', 'city': '101010100', 'temp': '18', 'tempf': '64', 'WD': '西风', 'wde': 'W', 'WS': '3级', 'wse': '<12km/h', 'SD': '53%', 'time': '18:22', 'weather': '多云', 'weathere': 'Cloudy', 'weathercode': 'd01', 'qy': '1002', 'njd': '8.93km', 'sd': '53%', 'rain': '0.0', 'rain24h': '0', 'aqi': '67', 'limitnumber': '不限行', 'aqi_pm25': '67', 'date': '04月19日(星期日)'}
城市: 北京
当前温度: 18
相对湿度: 53%
风向等级: 西风 3级
空气质量pm2.5: 67
车辆限号为: 不限行
说明:获取User-Agent和Referer的方法,打开谷歌浏览器,打开中国天气预报网站:http://www.weather.com.cn/weather1d/101010100.shtml,右键>审查元素,会出现以下页面:
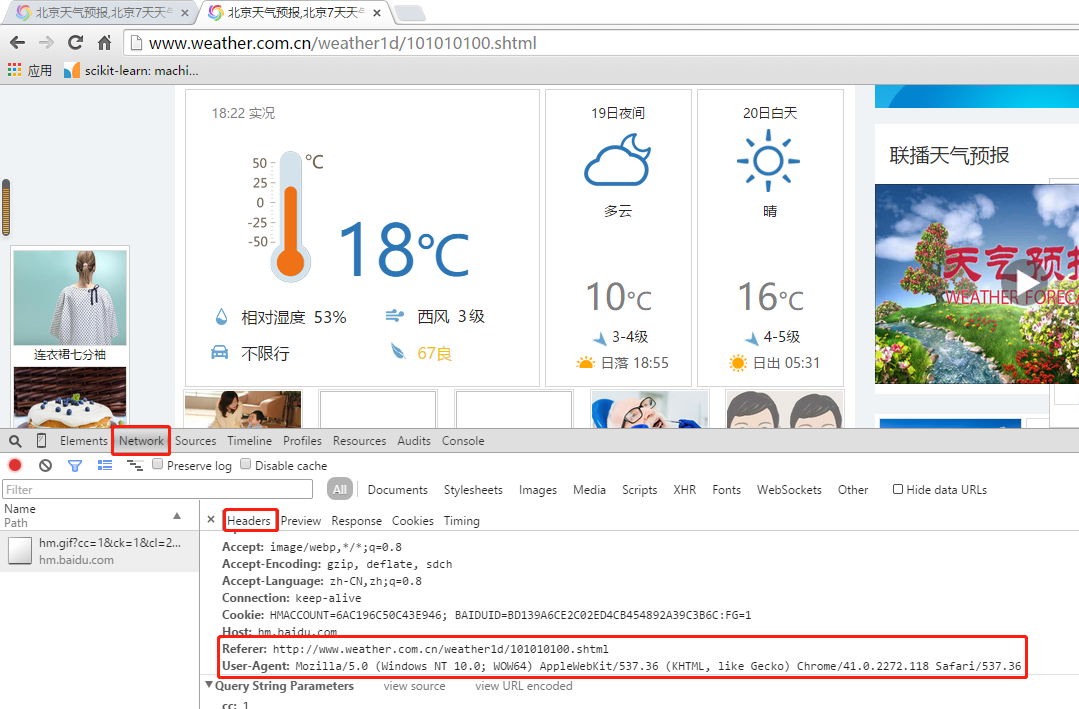
选择network>Headers,获取User-Agent和Referer。
2、对阳光电影网站中日韩影视频道的爬虫
在爬取网页信息时,在HTML代码中通过获取标签的方式来提取电影的下载地址时,可以使用正则表达式的方式快速提取某个标签内的指定信息。以爬取电影的下载地址为例。
阳光电影网站,https://www.ygdy8.com/index.html
阳光电影网站中日韩电视剧频道:
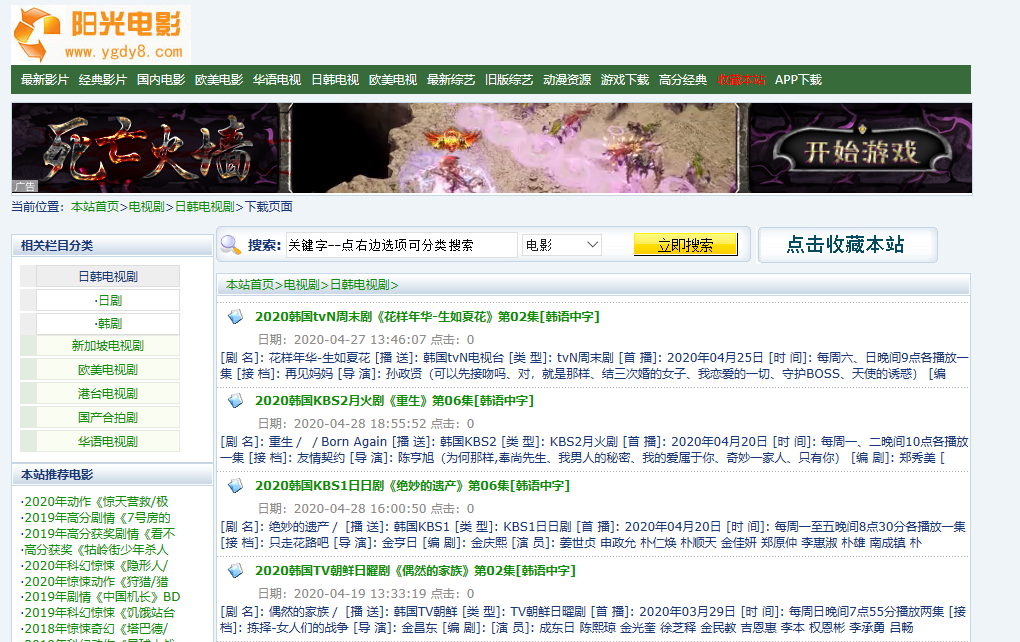
阳光电影网站中日韩电视剧频道爬虫:
#!/usr/bin/env python3 #导入网络请求模块 import requests import re def get_movies(url): #头部信息,需要设置网络工具中提取的重要信息“User-Agent”和“Referer” headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '\ 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'} #发送网络请求 response = requests.get(url,headers = headers) #设置编码 response.encoding = 'gb2312' #判断请求是否成功 if response.status_code==200: #将括号中的内容取出 movies_info = re.findall('<a href="(.*?)" class="ulink">',response.text) #返回的是日韩一级频道的后半截url #print(movies_info) #遍历日韩后半截url for url in movies_info: #拼装成完整的url info_url = 'https://www.ygdy8.com'+url movies_info_response = requests.get(info_url,headers=headers) movies_info_response.encoding = 'gb2312' #将日韩影视取出 download_url = re.findall('<a href=".*?">(.*?)</a></td>',movies_info_response.text) print(download_url) if __name__ == '__main__': get_movies('https://www.ygdy8.com/html/tv/rihantv/index.html')
结果:
['ftp://ygdy8:ygdy8@yg76.dydytt.net:5996/[阳光电影-www.ygdy8.com]契约友情-01+02.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:5997/[阳光电影-www.ygdy8.com]契约友情-03+04.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:7005/[阳光电影-www.ygdy8.com]契约友情-05+06.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:7006/[阳光电影-www.ygdy8.com]契约友情-07+08.mp4'] ['ftp://ygdy8:ygdy8@yg76.dydytt.net:5993/[阳光电影-www.ygdy8.com]危险的约定-01.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:5993/[阳光电影-www.ygdy8.com]危险的约定-02.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:5993/[阳光电影-www.ygdy8.com]危险的约定-03.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:5993/[阳光电影-www.ygdy8.com]危险的约定-04.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:5993/[阳光电影-www.ygdy8.com]危险的约定-05.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:5996/[阳光电影-www.ygdy8.com]危险的约定-06.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:5997/[阳光电影-www.ygdy8.com]危险的约定-07.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:7001/[阳光电影-www.ygdy8.com]危险的约定-08.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:7002/[阳光电影-www.ygdy8.com]危险的约定-09.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:7004/[阳光电影-www.ygdy8.com]危险的约定-10.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:7005/[阳光电影-www.ygdy8.com]危险的约定-11.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:7006/[阳光电影-www.ygdy8.com]危险的约定-12.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:7007/[阳光电影-www.ygdy8.com]危险的约定-13.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:7008/[阳光电影-www.ygdy8.com]危险的约定-14.mp4', 'ftp://ygdy8:ygdy8@yg76.dydytt.net:7008/[阳光电影-www.ygdy8.com]危险的约定-15.mp4'] ………………后面还有很多,略
3、对国内高匿代理IP网站的爬虫
在执行爬虫任务时,如果频繁的向某个网站多次发送请求,就会出现访问验证等现象,此类现象多数是因为目标网页的后台服务器对我们实施了封锁IP操作。为了避免此类现象的出现,我们可以使用代理IP来实现爬虫任务,每发送一次网络请求更换一个IP,从而降低被发现的风险。
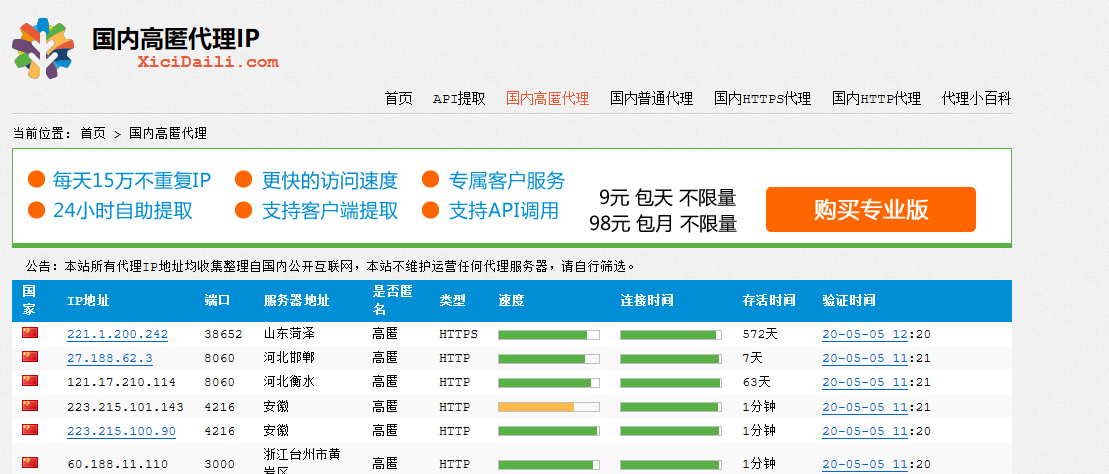
免费代理IP网页爬虫代码:
#导入网络请求模块 import requests #导入HTML解析模块 from lxml import etree #头部信息 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '\ 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'} #发送网络请求 response = requests.get('https://www.xicidaili.com/nn',headers=headers) #设置编码方式 response.encoding = 'utf-8' #判断请求是否成功 if response.status_code == 200: #解析HTML html = etree.HTML(response.text) #获取table标签内容 table = html.xpath('//table[@id="ip_list"]')[0] #获取所有tr标签,排除第一条 trs = table.xpath('//tr')[1:] #循环遍历tr标签内容 for t in trs: #获取服务器地址 address = t.xpath('td/a/text()') #获取IP ip = t.xpath('td/text()')[0] #获取端口 port = t.xpath('td/text()')[1] #输出 print('代理IP为:',ip,'对应端口为:',port,'服务器地址:',address)
结果:
代理IP为: 221.1.200.242 对应端口为: 38652 服务器地址: ['山东菏泽'] 代理IP为: 27.188.62.3 对应端口为: 8060 服务器地址: ['河北邯郸'] 代理IP为: 121.17.210.114 对应端口为: 8060 服务器地址: ['河北衡水'] 代理IP为: 223.215.101.143 对应端口为: 4216 服务器地址: ['安徽'] 代理IP为: 223.215.100.90 对应端口为: 4216 服务器地址: ['安徽'] 代理IP为: 60.188.11.110 对应端口为: 3000 服务器地址: ['浙江台州市黄岩区'] 代理IP为: 223.215.103.243 对应端口为: 4216 服务器地址: ['安徽'] 代理IP为: 114.104.139.93 对应端口为: 8691 服务器地址: ['安徽黄山'] ………………(此处省略其他内容)

