
决策树算法(python)
决策树
优点:
- - 计算复杂度不高,易于理解和解释,甚至比线性回归更直观;
- - 与人类做决策思考的思维习惯契合;
- - 模型可以通过树的形式进行可视化展示;
- - 可以直接处理非数值型数据,不需要进行哑变量的转化,甚至可以直接处理含缺失值的数据;
- - 可以处理不相关特征数据。
缺点:
- - 对于有大量数值型输入和输出的问题,特别是当数值型变量之间存在许多错综复杂的关系,如金融数据分析,决策树未必是一个好的选择;
- - 决定分类的因素更倾向于更多变量的复杂组合;
- - 模型不够稳健,某一个节点的小小变化可能导致整个树会有很大的不同。
- - 可能会产生过度匹配(过拟合)问题。
使用数据类型:数值型和离散型(标称型)。
工作原理:
决策树算法通常是一个递归的选择最优特征的过程,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类过程。这一过程对应着特征空间的划分,也对应着决策树的构建。开始,构建根结点,将所有训练数据都放在根结点。选择一个最优特征,按照这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶节点中去;如果还有子集不能被基本正确分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的节点。如此递归的进行下去,直到所有的训练数据子集被基本正确分类,或者没有合适的特征为止。最后每个子集都被分到叶节点上,即都有了明确的类,这就生成了一颗决策树。
决策树可以看作if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
将决策树转换成if-then规则的过程如下:
- 由决策树的根节点到叶节点的每一条路径构建一条规则;
- 路径内部结点的特征对应规则的条件;
- 叶节点的类对应规则的结论.
决策树的路径具有一个重要的性质:互斥且完备,即每一个样本均被且只能被一条路径所覆盖。
决策树由结点和有向边组成。结点有两种类型: 内部结点和叶节点。内部节点表示一个特征或属性,叶节点表示一个类。
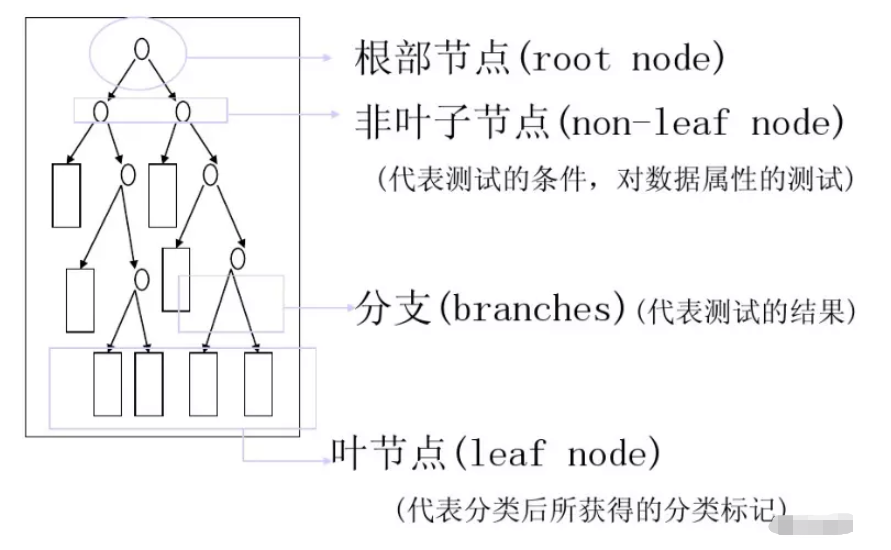
决策树通常有三个步骤:特征选择、决策树生成、决策树的修剪。
特征选择
如果利用一个特征进行分类的结果与随机分类的结果无异,则可以认为这个特征是不具备分类能力的。而我们应该基于什么准则来判定一个特征的分类能力呢?这时候,需要引入一个概念:信息增益。特征选择原则:对训练数据集,计算其每个特征的信息增益,并比它们的大小,从而选择信息增益最大的特征。
以信息增益作为特征选择准则,会存在偏向于选择取值较多的特征的问题。可以采用信息增益比对这一问题进行校正。原则也是选择信息增益比最大的特征。
决策树的生成
决策树的生成算法有很多变形,这里介绍几种经典的实现算法:ID3算法,C4.5算法和CART算法。这些算法的主要区别在于分类结点上特征选择的选取标准不同。下面详细了解一下算法的具体实现过程。
ID3算法
ID3算法的核心是在决策树的各个结点上应用信息增益准则进行特征选择。具体做法是:
-
- 从根节点开始,对结点计算所有可能特征的信息增益,选择信息增益最大的特征作为结点的特征,并由该特征的不同取值构建子节点;
- 对子节点递归地调用以上方法,构建决策树;
- 直到所有特征的信息增益均很小或者没有特征可选时为止。
C4.5算法(是ID3的升级,考虑自身熵值)
C4.5算法与ID3算法的区别主要在于它在生产决策树的过程中,使用信息增益比来进行特征选择。
CART算法
分类与回归树(classification and regression tree,CART)与C4.5算法一样,由ID3算法演化而来。CART假设决策树是一个二叉树,它通过递归地二分每个特征,将特征空间划分为有限个单元,并在这些单元上确定预测的概率分布。CART算法中,对于回归树(数值型),采用的是平方误差最小化准则;对于分类树(离散型),采用基尼指数最小化准则。
决策树的剪枝
如果对训练集建立完整的决策树,会使得模型过于针对训练数据,拟合了大部分的噪声,即出现过度拟合的现象。为了避免这个问题,有两种解决的办法:
- 当熵减少的数量小于某一个阈值时,就停止分支的创建。这是一种贪心算法。
- 先创建完整的决策树,然后再尝试消除多余的节点,也就是采用减枝的方法。
方法1存在一个潜在的问题:有可能某一次分支的创建不会令熵有太大的下降,但是随后的子分支却有可能会使得熵大幅降低。因此,我们更倾向于采用剪枝的方法。
剪枝策略:
-
- 预剪枝(实用):边建立决策树边进行剪枝操作。方法:限制树的深度,叶子节点的个数,叶子节点包含的样本树,信息增益量等。
- 后剪枝:当建立完决策树后来进行剪枝操作。
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,max_features=None, max_leaf_nodes=None,min_impurity_decrease=0.0, min_impurity_split=None,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, presort=False,random_state=None,splitter='best')
函数为创建一个决策树模型,其函数的参数含义如下所示:
- criterion:gini或者entropy,前者是基尼系数,后者是信息熵。
- splitter: best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中,默认的”best”适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐”random” 。
- max_features:None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的
- max_depth: int or None, optional (default=None) 设置决策随机森林中的决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间。
- min_samples_split:设置结点的最小样本数量,当样本数量可能小于此值时,结点将不会在划分。
- min_samples_leaf: 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
- min_weight_fraction_leaf: 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。
- max_leaf_nodes: 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。
- class_weight: 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
- min_impurity_split: 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
#导入 tree 模块 from sklearn import tree #导入红酒数据集,数据集包含来自3种不同起源的葡萄酒的共178条记录。 #13个属性是葡萄酒的13种化学成分。通过化学分析可以来推断葡萄酒的起源。起源为三个产地 #值得一提的是所有属性变量都是连续变量 from sklearn.datasets import load_wine #导入训练集和测试集切分包 from sklearn.model_selection import train_test_split import pandas as pd #import pydotplus #红酒数据集的数据探索 wine = load_wine() #print(wine) #print(wine.data) #178*13 print('x数据集形状:',wine.data.shape) #print(wine.target) #178*1 print('y数据集形状:',wine.target.shape) #将x,y都放到数据集data_frame中 data_frame = pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1) #显示前10行 print('数据前十行显示:\n',data_frame.head(10)) #显示数据集特征列名 print('数据集特征列名:',wine.feature_names) #显示数据集的标签分类 print('数据集标签分类:',wine.target_names) #70%为训练数据,30%为测试数据 Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3) print('训练数据的大小为:',Xtrain.shape) print('测试数据的大小为:',Xtest.shape) #初始化树模型,criterion:gini或者entropy,前者是基尼系数,后者是信息熵。 clf = tree.DecisionTreeClassifier(criterion="entropy") #实例化训练集 clf = clf.fit(Xtrain, Ytrain) #返回测试集的准确度 score = clf.score(Xtest, Ytest) y = clf.predict(Xtest) print('测试集的准确度:',score) for each in range(len(Ytest)): print('预测结果:',y[each],'\t真实结果:',Ytest[each],'\n') #特征重要性 feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类',\ '花青素','颜色强度','色调','od280/od315 稀释葡萄酒','脯氨酸'] print(clf.feature_importances_) print([*zip(feature_name,clf.feature_importances_)]) #生成一颗决策树,该部分未成功 #import graphviz #dot_data = StringIO() #tree.export_graphviz(clf # ,out_file=None # ,feature_names= feature_name # ,class_names=["琴酒","雪莉","贝尔摩德"] # ,filled=True # ,rounded=True # ) #graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) #graph.write_pdf("F://python入门//文件//wine.pdf")
结果
x数据集形状: (178, 13) y数据集形状: (178,) 数据前十行显示: 0 1 2 3 4 5 ... 8 9 10 11 12 0 0 14.23 1.71 2.43 15.6 127.0 2.80 ... 2.29 5.64 1.04 3.92 1065.0 0 1 13.20 1.78 2.14 11.2 100.0 2.65 ... 1.28 4.38 1.05 3.40 1050.0 0 2 13.16 2.36 2.67 18.6 101.0 2.80 ... 2.81 5.68 1.03 3.17 1185.0 0 3 14.37 1.95 2.50 16.8 113.0 3.85 ... 2.18 7.80 0.86 3.45 1480.0 0 4 13.24 2.59 2.87 21.0 118.0 2.80 ... 1.82 4.32 1.04 2.93 735.0 0 5 14.20 1.76 2.45 15.2 112.0 3.27 ... 1.97 6.75 1.05 2.85 1450.0 0 6 14.39 1.87 2.45 14.6 96.0 2.50 ... 1.98 5.25 1.02 3.58 1290.0 0 7 14.06 2.15 2.61 17.6 121.0 2.60 ... 1.25 5.05 1.06 3.58 1295.0 0 8 14.83 1.64 2.17 14.0 97.0 2.80 ... 1.98 5.20 1.08 2.85 1045.0 0 9 13.86 1.35 2.27 16.0 98.0 2.98 ... 1.85 7.22 1.01 3.55 1045.0 0 [10 rows x 14 columns] 数据集特征列名: ['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline'] 数据集标签分类: ['class_0' 'class_1' 'class_2'] 训练数据的大小为: (124, 13) 测试数据的大小为: (54, 13) 测试集的准确度: 0.9074074074074074 预测结果: 0 真实结果: 0 预测结果: 0 真实结果: 0 预测结果: 1 真实结果: 1 预测结果: 2 真实结果: 2 预测结果: 0 真实结果: 1 预测结果: 0 真实结果: 0 预测结果: 0 真实结果: 0 预测结果: 0 真实结果: 0 预测结果: 2 真实结果: 2 预测结果: 1 真实结果: 1 预测结果: 1 真实结果: 1 预测结果: 2 真实结果: 1 预测结果: 0 真实结果: 0 预测结果: 1 真实结果: 1 预测结果: 0 真实结果: 0 预测结果: 2 真实结果: 2 预测结果: 1 真实结果: 1 预测结果: 1 真实结果: 1 预测结果: 2 真实结果: 2 预测结果: 1 真实结果: 1 预测结果: 0 真实结果: 0 预测结果: 1 真实结果: 1 预测结果: 2 真实结果: 2 预测结果: 1 真实结果: 1 预测结果: 2 真实结果: 2 预测结果: 2 真实结果: 2 预测结果: 0 真实结果: 1 预测结果: 0 真实结果: 0 预测结果: 0 真实结果: 1 预测结果: 2 真实结果: 2 预测结果: 0 真实结果: 0 预测结果: 2 真实结果: 2 预测结果: 0 真实结果: 0 预测结果: 1 真实结果: 1 预测结果: 0 真实结果: 0 预测结果: 1 真实结果: 1 预测结果: 0 真实结果: 0 预测结果: 1 真实结果: 1 预测结果: 1 真实结果: 2 预测结果: 1 真实结果: 1 预测结果: 2 真实结果: 2 预测结果: 1 真实结果: 1 预测结果: 2 真实结果: 2 预测结果: 0 真实结果: 0 预测结果: 2 真实结果: 2 预测结果: 2 真实结果: 2 预测结果: 2 真实结果: 2 预测结果: 1 真实结果: 1 预测结果: 1 真实结果: 1 预测结果: 0 真实结果: 0 预测结果: 0 真实结果: 0 预测结果: 2 真实结果: 2 预测结果: 2 真实结果: 2 预测结果: 1 真实结果: 1 [0. 0.02120488 0. 0. 0. 0. 0.41936238 0. 0. 0.14980257 0.0354628 0. 0.37416737] [('酒精', 0.0), ('苹果酸', 0.021204876662634046), ('灰', 0.0), ('灰的碱性', 0.0), ('镁', 0.0), ('总酚', 0.0), ('类黄酮', 0.41936238395073366), ('非黄烷类酚类', 0.0), ('花青素', 0.0), ('颜色强度', 0.14980257279491835), ('色调', 0.03546279572288287), ('od280/od315 稀释葡萄酒', 0.0), ('脯氨酸', 0.37416737086883106)]
以上程序运行过程中会报错:ModuleNotFoundError: No module named 'pydotplus'
第一步:打开Anaconda Prompt,上直接pip install pydotplus,安装即可


