

《python数据分析基础》之Excel文件
1、针对Excel文件,查看Excel文件各工作簿的基本信息
源数据“测试数据.xlsx”,该文件只有一个sheet1:
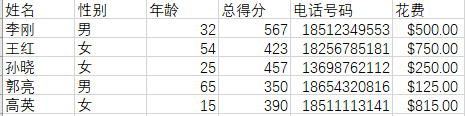
查看Excel文件的基本信息代码:
#!/usr/bin/env python3 #读取Excel文件 from xlrd import open_workbook input_file = "F://python入门//数据2//测试数据.xlsx" #打开目标文件 workbook = open_workbook(input_file) #打印Excel所有的工作簿数 print('Number of worksheets:',workbook.nsheets) #打印每个工作簿 for worksheet in workbook.sheets(): #将每个sheet中的工作簿名称,行数,列数计算出来 print("Worksheet name:",worksheet.name,"\tRows:",worksheet.nrows,\ "\tColumns:",worksheet.ncols)
结果:
Number of worksheets: 1
Worksheet name: Sheet1 Rows: 6 Columns: 6
2、针对Excel文件,复制Excel的内容到另一个Excel文件
源数据“测试数据.xlsx”:

将“测试数据.xlsx”复制到“测试数据copy.xlsx”中:
#!/usr/bin/env python3 #读取Excel文件 import pandas as pd input_file = "F://python入门//数据2//测试数据.xlsx" output_file = "F://python入门//数据2//测试数据copy.xlsx" data_frame = pd.read_excel(input_file,sheetname='one') writer = pd.ExcelWriter(output_file) data_frame.to_excel(writer,sheet_name = 'newsheet',index=False) writer.save()
“测试数据copy.xlsx”中的结果:

3、针对Excel文件,筛选特定的行
名为“测试数据.xlsx”的源数据:
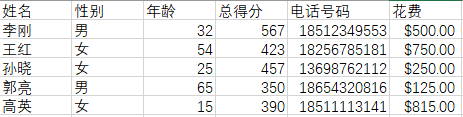
将“$”符号去掉,并筛选出花费大于700的目标数据:
#!/usr/bin/env python3 #读取Excel文件 import pandas as pd input_file = "F://python入门//数据2//测试数据.xlsx" output_file = "F://python入门//数据2//测试数据copy.xlsx" data_frame = pd.read_excel(input_file,sheetname='one',index_col = None) #将‘$’替换为空 data_frame_value_meeets_condition = data_frame['花费'] = data_frame['花费'].replace(r'$','') #将格式转化为float型 data_frame_value_meeets_condition = data_frame['花费'] = data_frame['花费'].astype(float) #筛选花费大于700的目标数据 data_frame_value_meeets_condition = data_frame[data_frame['花费'].astype(float) > 700.00] writer = pd.ExcelWriter(output_file) data_frame_value_meeets_condition.to_excel(writer,sheet_name = 'newsheet',index=False) writer.save()
“测试数据copy.xlsx”中的结果:

4、针对Excel文件,筛选出行中的值属于某个集合的目标数据
名为“测试数据.xlsx”的源数据:
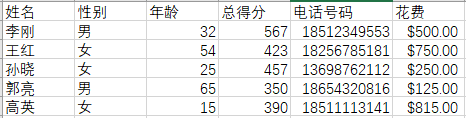
将在数据集['18256785181','13698762112']的数据取出:
#!/usr/bin/env python3 #读取Excel文件 import pandas as pd input_file = "F://python入门//数据2//测试数据.xlsx" output_file = "F://python入门//数据2//测试数据copy.xlsx" data_frame = pd.read_excel(input_file,sheetname='one',index_col = None) important_dates = ['18256785181','13698762112'] data_frame_value_in_set = data_frame[data_frame['电话号码'].isin(important_dates)] writer = pd.ExcelWriter(output_file) data_frame_value_in_set.to_excel(writer,sheet_name = 'newsheet',index=False) writer.save()
“测试数据copy.xlsx”中的结果:

5、针对Excel文件,将行中符合特定模式的值取出
名为“测试数据.xlsx”的源数据:
将行中姓名中以“高”开头的目标数据取出:
#!/usr/bin/env python3 #读取Excel文件 import pandas as pd input_file = "F://python入门//数据2//测试数据.xlsx" output_file = "F://python入门//数据2//测试数据copy.xlsx" data_frame = pd.read_excel(input_file,sheetname='one',index_col = None) data_frame_value_matches_pattern = data_frame[data_frame['姓名'].str.startswith("高")] writer = pd.ExcelWriter(output_file) data_frame_value_matches_pattern.to_excel(writer,sheet_name = 'newsheet',index=False) writer.save()
“测试数据copy.xlsx”中的结果:

6、针对Excel文件,使用索引选取特定列
名为“测试数据.xlsx”的源数据:
从源数据中选取第一列和第四列:
#!/usr/bin/env python3 #读取Excel文件 import pandas as pd input_file = "F://python入门//数据2//测试数据.xlsx" output_file = "F://python入门//数据2//测试数据copy.xlsx" data_frame = pd.read_excel(input_file,sheetname='one',index_col = None) data_frame_column_by_index = data_frame.iloc[:,[0,3]] writer = pd.ExcelWriter(output_file) data_frame_column_by_index.to_excel(writer,sheet_name = 'newsheet',index=False) writer.save()
“测试数据copy.xlsx”中的结果:
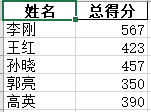
7、针对Excel文件,使用列标题选取特定列
名为“测试数据.xlsx”的源数据:
将列标题为:“电话号码”和“花费”的列取出:
#!/usr/bin/env python3 #读取Excel文件 import pandas as pd input_file = "F://python入门//数据2//测试数据.xlsx" output_file = "F://python入门//数据2//测试数据copy.xlsx" data_frame = pd.read_excel(input_file,sheetname='one',index_col = None) data_frame_column_by_index = data_frame.loc[:,['电话号码','花费']] writer = pd.ExcelWriter(output_file) data_frame_column_by_index.to_excel(writer,sheet_name = 'newsheet',index=False) writer.save()
“测试数据copy.xlsx”中的结果:
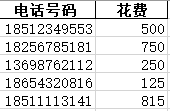
8、针对Excel文件,将“测试数据.xlsx”中的两个sheet的内容,经过筛选合并到“测试数据copy.xlsx”中
名为“测试数据.xlsx”的第一个sheet的内容:
名为“测试数据.xlsx”的第二个sheet的内容:

将“测试数据.xlsx”中的两个sheet的内容,经过筛选合并到“测试数据copy.xlsx”中:
#!/usr/bin/env python3 #读取Excel文件 import pandas as pd input_file = "F://python入门//数据2//测试数据.xlsx" output_file = "F://python入门//数据2//测试数据copy.xlsx" #通过在read_excel函数中设置sheetname=None,可以一次性读取工作簿中的所有工作表 data_frame = pd.read_excel(input_file,sheetname=None,index_col = None) row_output = [] for worksheet_name,data in data_frame.items(): #将‘$’替换为空 data['花费'] = data['花费'].replace(r'$','') #将格式转化为float型 data['花费'] = data['花费'].astype(float) #筛选花费大于700的目标数据 row_output.append(data[data['花费'].astype(float) > 700.00]) filtered_rows = pd.concat(row_output,axis=0,ignore_index=True) writer = pd.ExcelWriter(output_file) filtered_rows.to_excel(writer,sheet_name = 'newsheet',index=False) writer.save()
“测试数据copy.xlsx”中的结果:

9、针对Excel文件,将“测试数据.xlsx”中的两个sheet的内容,经过列名筛选合并到“测试数据copy.xlsx”中
名为“测试数据.xlsx”的第一个sheet的内容:
名为“测试数据.xlsx”的第二个sheet的内容:
将“测试数据.xlsx”中的两个sheet的内容,经过列名筛选合并到“测试数据copy.xlsx”中:
#!/usr/bin/env python3 #读取Excel文件 import pandas as pd input_file = "F://python入门//数据2//测试数据.xlsx" output_file = "F://python入门//数据2//测试数据copy.xlsx" #通过在read_excel函数中设置sheetname=None,可以一次性读取工作簿中的所有工作表 data_frame = pd.read_excel(input_file,sheetname=None,index_col = None) column_output = [] for worksheet_name,data in data_frame.items(): # column_output.append(data.loc[:,['姓名','性别']]) selected_columns = pd.concat(column_output,axis=0,ignore_index=True) writer = pd.ExcelWriter(output_file) selected_columns.to_excel(writer,sheet_name = 'newsheet',index=False) writer.save()
“测试数据copy.xlsx”中的结果:
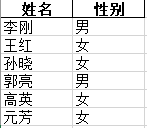
10、针对Excel文件,将“测试数据.xlsx”中的三个sheet中的两个sheet的内容,经过列名筛选合并到“测试数据copy.xlsx”中
名为“测试数据.xlsx”的第一个sheet的内容:
名为“测试数据.xlsx”的第二个sheet的内容:

名为“测试数据.xlsx”的第三个sheet的内容:
将“测试数据.xlsx”中的三个sheet中的前两个sheet的内容,经过列名筛选合并到“测试数据copy.xlsx”中
#!/usr/bin/env python3 #读取Excel文件 import pandas as pd input_file = "F://python入门//数据2//测试数据.xlsx" output_file = "F://python入门//数据2//测试数据copy.xlsx" my_sheets = [0,1] cost = 700.00 data_frame = pd.read_excel(input_file,sheet_name=my_sheets,index_col = None) row_output = [] for worksheet_name,data in data_frame.items(): #将‘$’替换为空 data['花费'] = data['花费'].replace(r'$','') #将格式转化为float型 data['花费'] = data['花费'].astype(float) #筛选花费大于700的目标数据 row_output.append(data[data['花费'].astype(float) > cost]) filtered_rows = pd.concat(row_output,axis=0,ignore_index=True) writer = pd.ExcelWriter(output_file) filtered_rows.to_excel(writer,sheet_name = 'newsheet',index=False) writer.save()
“测试数据copy.xlsx”中的结果:

11、针对Excel文件,处理多个工作簿,合并多个Excel,多个sheet,生成新Excel文件:
源数据共有两个Excel,分别为“测试数据1.xlsx”和“测试数据2.xlsx”,这两个Excel的布局和内容一样,下面仅展示“测试数据1.xlsx”文件的内容:
名为“测试数据1.xlsx”的第一个sheet的内容:
名为“测试数据1.xlsx”的第二个sheet的内容:
名为“测试数据1.xlsx”的第三个sheet的内容:
处理“测试数据1.xlsx”和“测试数据2.xlsx”,合并所有的工作表和Excel文件,将所有内容放到“测试数据copy.xlsx”中
#!/usr/bin/env python3 #读取Excel文件 import pandas as pd import glob import os input_path = "F://python入门//数据2" output_file = "F://python入门//数据2//测试数据copy.xlsx" all_workbooks = glob.glob(os.path.join(input_path,'*.xlsx')) data_frames = [] for workbook in all_workbooks: all_worksheets = pd.read_excel(workbook,sheet_name=None,index_col = None) for worksheet_name,data in all_worksheets.items(): data_frames.append(data) all_data_concatenated = pd.concat(data_frames,axis=0,ignore_index=True) writer = pd.ExcelWriter(output_file) all_data_concatenated.to_excel(writer,sheet_name = 'all_data',index=False) writer.save()
“测试数据copy.xlsx”中的结果:
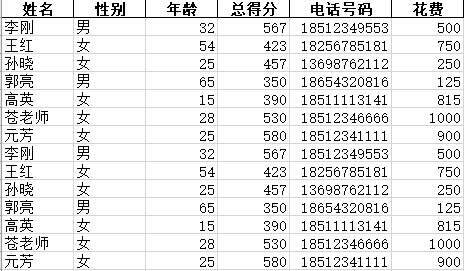
12、针对Excel文件,计算每个工作簿和工作表的总数和均值
源数据共有两个Excel,分别为“测试数据1.xlsx”和“测试数据2.xlsx”,这两个Excel的布局和内容一样,下面仅展示“测试数据1.xlsx”文件的内容:
名为“测试数据1.xlsx”的第一个sheet的内容:
名为“测试数据1.xlsx”的第二个sheet的内容:
名为“测试数据1.xlsx”的第三个sheet的内容:
计算每个工作簿和工作表的总数和均值:
#!/usr/bin/env python3 #读取Excel文件 import pandas as pd import glob import os input_path = "F://python入门//数据2" output_file = "F://python入门//数据2//测试数据copy.xlsx" all_workbooks = glob.glob(os.path.join(input_path,'*.xlsx')) #遍历每个Excel文件 for workbook in all_workbooks: all_worksheets = pd.read_excel(workbook,sheet_name=None,index_col = None)#遍历每个工作表 for worksheet_name,data in all_worksheets.items(): #将每个工作表的总花费计算出来 total_sales_com = pd.DataFrame([float(str(value).strip('$'))\ for value in data.loc[:,'花费']]).sum() total_sales=int(total_sales_com[0]) #将每个sheet的行数计算出来 number_of_sales = len(data.loc[:,'花费']) #将每个sheet的花费均值计算出来 average_sales = int(total_sales/number_of_sales)#对每个sheet的计算结果都放到字典data中 data = {'workbook':os.path.basename(workbook),'worksheet':worksheet_name,\ 'worksheet_total':total_sales,'worksheet_average':average_sales} print(data)
结果数据:
{'workbook': '测试数据1.xlsx', 'worksheet': 'one', 'worksheet_total': 2440, 'worksheet_average': 488}
{'workbook': '测试数据1.xlsx', 'worksheet': 'new', 'worksheet_total': 1000, 'worksheet_average': 1000}
{'workbook': '测试数据1.xlsx', 'worksheet': 'two', 'worksheet_total': 900, 'worksheet_average': 900}
{'workbook': '测试数据2.xlsx', 'worksheet': 'one', 'worksheet_total': 2440, 'worksheet_average': 488}
{'workbook': '测试数据2.xlsx', 'worksheet': 'new', 'worksheet_total': 1000, 'worksheet_average': 1000}
{'workbook': '测试数据2.xlsx', 'worksheet': 'two', 'worksheet_total': 900, 'worksheet_average': 900}

声明:样例中的电话号码纯属小编胡编~
