
《python数据分析基础》之CSV文件
1、针对更为复杂的CSV文件(含有标题和多列)做简单的处理和过滤
“CSV测试数据.csv”文件里的内容:
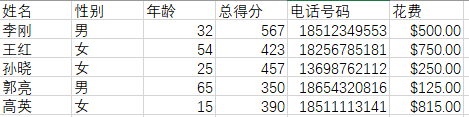
代码,对“花费”进行了去除“$”和类型转换,使用loc函数将满足性别是“女”或花费大于750的行取出,最后写入文件“CSV测试数据copy.csv”:
#!/usr/bin/env python3
#读取文本文件
import pandas as pd
input_file = "F://python入门//数据//CSV测试数据.csv"
output_file = "F://python入门//数据//CSV测试数据copy.csv"
f = open(input_file)
#当我们处理的CSV文件名带有中文时,如果没有open,直接read_csv就会报错。
#报错信息:OSError: Initializing from file failed
#将文件内容存放到data_frame中
data_frame = pd.read_csv(f)
#对“花费”进行了去除“$”和类型转换
data_frame['花费'] = data_frame['花费'].str.strip('$').astype(float)
#使用loc函数将满足性别是“女”或花费大于750的行取出
data_frame_value_meets_condition = data_frame.loc[(data_frame['性别'].str.contains('女'))|\
(data_frame['花费'] > 750.0),:]
#loc函数里面的“|”是或的意思,满足条件a或条件b
#print(data_frame_value_meets_condition)
#写入文件“CSV测试数据copy.csv”
data_frame_value_meets_condition.to_csv(output_file,index=False,encoding='gb2312')
#如果没有encoding='gb2312',会出现写入乱码
“CSV测试数据copy.csv”里的结果内容:

2、针对更为复杂的CSV文件(含有标题和多列),当行中的值属于某个集合时,则保留输出这些行。
源数据:
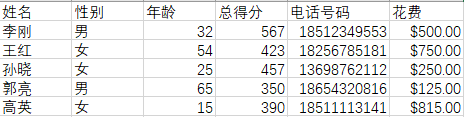
当行中的值属于某个集合时,则保留输出这些行:
#!/usr/bin/env python3 #读取文本文件 import pandas as pd input_file = "F://python入门//数据//CSV测试数据.csv" output_file = "F://python入门//数据//CSV测试数据copy.csv" f = open(input_file) #当我们处理的CSV文件名带有中文时,如果没有open,直接read_csv就会报错。 #报错信息:OSError: Initializing from file failed data_frame = pd.read_csv(f) #将目标集合放到变量important_datas中 important_datas = ['18256785181','13698762112'] #将符合条件的目标数据集取出 data_frame_value_in_set = data_frame.loc[(data_frame['电话号码'].isin(important_datas)),:] #将目标数据集导入“CSV测试数据copy.csv”中 data_frame_value_in_set.to_csv(output_file,index=False,encoding='gb2312') #如果没有encoding='gb2312',会出现写入乱码
结果:

3、针对更为复杂的CSV文件(含有标题和多列),筛选出匹配某个模式的行
源数据:
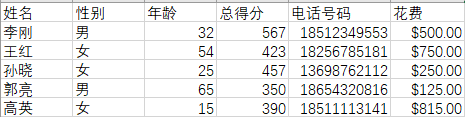
正则表达式的应用(代码):
#!/usr/bin/env python3 #读取文本文件 import pandas as pd input_file = "F://python入门//数据//CSV测试数据.csv" output_file = "F://python入门//数据//CSV测试数据copy.csv" f = open(input_file) #当我们处理的CSV文件名带有中文时,如果没有open,直接read_csv就会报错。 #报错信息:OSError: Initializing from file failed data_frame = pd.read_csv(f) #将符合条件的目标数据集取出 data_frame_value_matches_pattern = data_frame.loc[data_frame['姓名'].str.startswith("王"),:] #将目标数据集导入“CSV测试数据copy.csv”中 data_frame_value_matches_pattern.to_csv(output_file,index=False,encoding='gb2312') #如果没有encoding='gb2312',会出现写入乱码
结果:

4、针对更为复杂的CSV文件(含有标题和多列),根据索引值选取列
源文件:
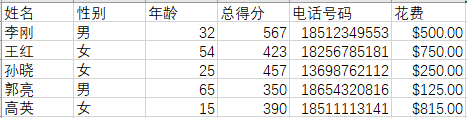
将索引值为0和3的列打印到屏幕,使用iloc函数来根据索引位置选取列。
#!/usr/bin/env python3 #读取文本文件 import pandas as pd input_file = "F://python入门//数据//CSV测试数据.csv" output_file = "F://python入门//数据//CSV测试数据copy.csv" f = open(input_file) #当我们处理的CSV文件名带有中文时,如果没有open,直接read_csv就会报错。 #报错信息:OSError: Initializing from file failed data_frame = pd.read_csv(f) #将符合条件的目标数据集取出 data_frame_column_by_index = data_frame.iloc[:,[0,3]] #将目标数据集导入“CSV测试数据copy.csv”中 data_frame_column_by_index.to_csv(output_file,index=False,encoding='gb2312') #如果没有encoding='gb2312',会出现写入乱码
结果集:
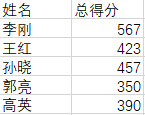
5、针对更为复杂的CSV文件(含有标题和多列),根据列标题选取列
源数据:
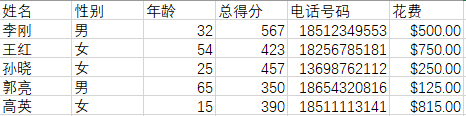
根据列标题选取列,使用loc函数选取列,代码:
#!/usr/bin/env python3 #读取文本文件 import pandas as pd input_file = "F://python入门//数据//CSV测试数据.csv" output_file = "F://python入门//数据//CSV测试数据copy.csv" f = open(input_file) #当我们处理的CSV文件名带有中文时,如果没有open,直接read_csv就会报错。 #报错信息:OSError: Initializing from file failed data_frame = pd.read_csv(f) #将符合条件的目标数据集取出 data_frame_column_by_name = data_frame.loc[:,['姓名','年龄']] #将目标数据集导入“CSV测试数据copy.csv”中 data_frame_column_by_name.to_csv(output_file,index=False,encoding='gb2312') #如果没有encoding='gb2312',会出现写入乱码
结果集:
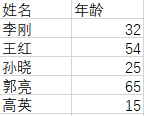
6、针对更为复杂的CSV文件(含有标题和多列),选取连续的行,去除不需要的行
源数据:
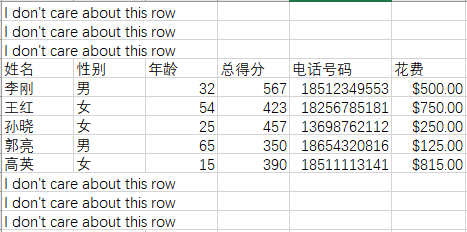
去除不需要的行,剩下的行重新生成索引:
#!/usr/bin/env python3
#读取文本文件
import pandas as pd
input_file = "F://python入门//数据//CSV测试数据.csv"
output_file = "F://python入门//数据//CSV测试数据copy.csv"
f = open(input_file)
#当我们处理的CSV文件名带有中文时,如果没有open,直接read_csv就会报错。
#报错信息:OSError: Initializing from file failed
#无标题行
data_frame = pd.read_csv(f,header=None)
#将不需要的行删掉,开头三行和结尾三行
data_frame = data_frame.drop([0,1,2,9,10,11])
#使用iloc函数选取第一行单独作为列索引,
data_frame.columns = data_frame.iloc[0]
print(data_frame.columns)
#删除第一行(标题行),为数据框重新生成索引
data_frame = data_frame.reindex(data_frame.index.drop(3))
print('……')
print(data_frame)
#将目标数据集导入“CSV测试数据copy.csv”中
data_frame.to_csv(output_file,index=False,encoding='gb2312')
#如果没有encoding='gb2312',会出现写入乱码
结果数据:
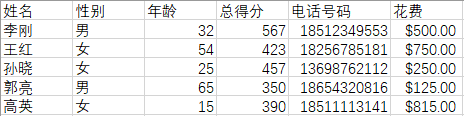
Spyder右下角打印出来的数据:
Index(['姓名', '性别', '年龄', '总得分', '电话号码', '花费'], dtype='object', name=3) …… 3 姓名 性别 年龄 总得分 电话号码 花费 4 李刚 男 32 567 18512349553 $500.00 5 王红 女 54 423 18256785181 $750.00 6 孙晓 女 25 457 13698762112 $250.00 7 郭亮 男 65 350 18654320816 $125.00 8 高英 女 15 390 18511113141 $815.00
7、针对更为复杂的CSV文件(含有标题和多列),添加标题行
源数据:
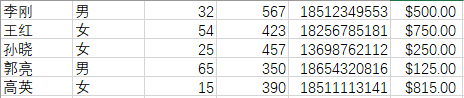
添加新标题行:
#!/usr/bin/env python3 #读取文本文件 import pandas as pd input_file = "F://python入门//数据//CSV测试数据.csv" output_file = "F://python入门//数据//CSV测试数据copy.csv" f = open(input_file) #当我们处理的CSV文件名带有中文时,如果没有open,直接read_csv就会报错。 #报错信息:OSError: Initializing from file failed #设置标题行 header_list = ['姓名','性别','年龄','总得分','电话号码','花费'] #原始无标题行,添加新标题行 data_frame = pd.read_csv(f,header=None,names=header_list) #将目标数据集导入“CSV测试数据copy.csv”中 data_frame.to_csv(output_file,index=False,encoding='gb2312') #如果没有encoding='gb2312',会出现写入乱码
结果:
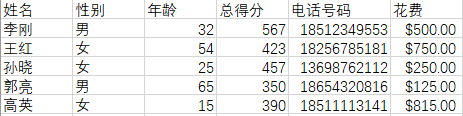
8、针对更为复杂的CSV文件(含有标题和多列),从多个文件中连接数据
数据源是三个CSV文件:
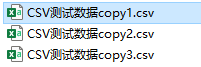
为了方便,这里每个CSV文件的内容都相同,以其中一个CSV文件为例:
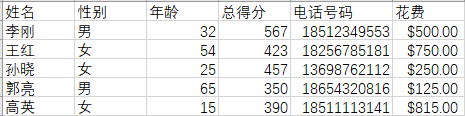
将这三个内容相同的CSV文件合并:
#!/usr/bin/env python3 #读取文本文件 import pandas as pd import glob import os #输入文件路径 input_path = "F://python入门//数据" output_file = "F://python入门//数据//CSV测试数据copy.csv" #将以开头为“CSV测试数据copy”的文件放到all_files中 all_files = glob.glob(os.path.join(input_path,'CSV测试数据copy*')) #将三个目标文件的内容都放到列表all_data_frames中 all_data_frames = [] for file in all_files: #打开每个文件 f = open(file) #读取每个文件,重新设置一列成为index值 data_frame = pd.read_csv(f,index_col = None) all_data_frames.append(data_frame) #这里,如果你需要平行连接数据,就设置axis=1,指连接后再重新赋值index(len(index)) data_frame_concat = pd.concat(all_data_frames,axis=0,ignore_index=True) #将目标数据集导入“CSV测试数据copy.csv”中 data_frame_concat.to_csv(output_file,index=False,encoding='gb2312') #如果没有encoding='gb2312',会出现写入乱码
结果为生成文件“CSV测试数据copy.csv”,其内容为:
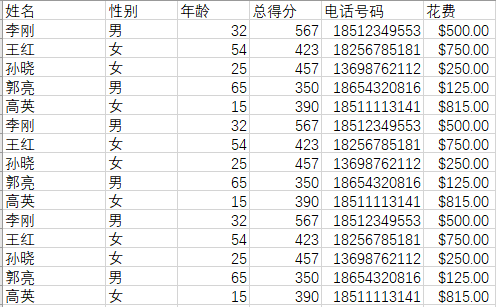
9、针对更为复杂的CSV文件(含有标题和多列),计算每个文件中值的总和和均值
源数据为四个文件夹,三个相同内容的文件,一个是前三个文件的汇总:
这三个文件与(8)中的例子一样,这里不再赘述。
另一个汇总的文件:

其内容为前三个文件内容的加总:
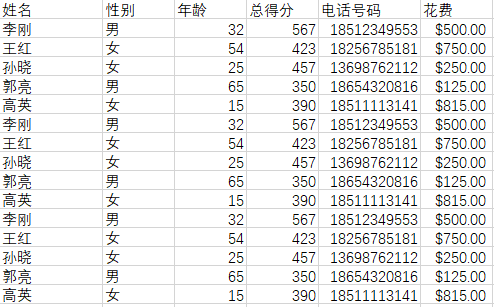
对这三个文件取中的花费字段取总和和均值:
#!/usr/bin/env python3 #读取文本文件 import pandas as pd import glob import os #输入文件路径 input_path = "F://python入门//数据" output_file = "F://python入门//数据//CSV测试数据copy_new.csv" #将以开头为“CSV测试数据copy”的文件放到all_files中 all_files = glob.glob(os.path.join(input_path,'CSV测试数据copy*')) #将三个目标文件的内容都放到列表all_data_frames中 all_data_frames = [] for input_file in all_files: #打开每个文件 f = open(input_file) #读取每个文件,重新设置一列成为index值 data_frame = pd.read_csv(f,index_col = None) #求花费总和 total_sales = pd.DataFrame([float(str(value).strip('$').replace(',',''))\ for value in data_frame.loc[:,'花费']]).sum() print(total_sales) #求花费均值 average_sales = pd.DataFrame([float(str(value).strip('$').replace(',',''))\ for value in data_frame.loc[:,'花费']]).mean() print(average_sales) #生成一个字典 data = {'file_name':os.path.basename(input_file), 'total_sales':total_sales, 'average_sales':average_sales} #将处理的每个文件的总和和均值放到all_data_frames中 all_data_frames.append(pd.DataFrame(data,columns = ['file_name','total_sales',\ 'average_sales'])) #这里,如果你需要平行连接数据,就设置axis=1,指连接后再重新赋值index(len(index)) data_frame_concat = pd.concat(all_data_frames,axis=0,ignore_index=True) #将目标数据集导入“CSV测试数据copy.csv”中 data_frame_concat.to_csv(output_file,index=False,encoding='gb2312') #如果没有encoding='gb2312',会出现写入乱码
生成的“CSV测试数据copy_new.csv”结果:
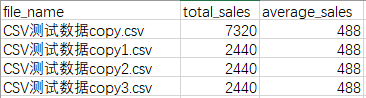
打印到Spyder右下角的结果:
0 7320.0 dtype: float64 0 488.0 dtype: float64 0 2440.0 dtype: float64 0 488.0 dtype: float64 0 2440.0 dtype: float64 0 488.0 dtype: float64 0 2440.0 dtype: float64 0 488.0 dtype: float64
好了,以上内容是小编整理的python处理CSV文件的代码及运行结果~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号