

python读取或写入文件
一、创建并读取文本文件
1、该方法需要关闭filereader对象
#!/usr/bin/env python3 #读取文件 input_file = "F://python入门//文件//一个简单的文本文件.txt" filereader = open(input_file,'r') for row in filereader: print(row.strip()) filereader.close()
结果:
I'm already much better at python
2、下面介绍读取文件的新型语法,使用with语句,此方法不需要调用close函数:
#!/usr/bin/env python3 #读取文件 input_file = "F://python入门//文件//一个简单的文本文件.txt" with open(input_file,'r',newline='') as filereader: for row in filereader: print(row.strip())
结果:
I'm already much better at python
3、使用glob读取多个文本文件
本例导入了os模块和glob模块,导入os模块就可以使用它提供的若干路径名函数,例如os.path.join函数可以巧妙的将一个或多个路径成分连接在一起。glob模块可以找出与特定模式相匹配的所有路径名。os模块和glob模块组合在一起使用,可以找出特定模式的某个文件夹下面的所有文件。
#!/usr/bin/env python3 #读取多个文件 import os import glob input_path = "F://python入门//文件" for input_file in glob.glob(os.path.join(input_path,'*.txt')): with open(input_file,'r',newline='') as filereader: for row in filereader: print("{}".format(row.strip()))
结果(将"F://python入门//文件"路径下的TXT文件的内容取出):
I'm already much better at python This text comes from a different text file.
4、针对更为复杂的CSV文件(含有标题和多列)
使用pandas
#!/usr/bin/env python3 #读取文本文件 import pandas as pd input_file = "F://python入门//数据//CSV测试数据.csv" output_file = "F://python入门//数据//CSV测试数据copy.csv" f = open(input_file) #当我们处理的CSV文件名带有中文时,如果没有open,直接read_csv就会报错。 #报错信息:OSError: Initializing from file failed data_frame = pd.read_csv(f) print(data_frame) data_frame.to_csv(output_file,index=False,encoding='gb2312') #如果没有encoding='gb2312',会出现写入乱码
结果,将"CSV测试数据.csv"中的数据输出到"CSV测试数据copy.csv"中。
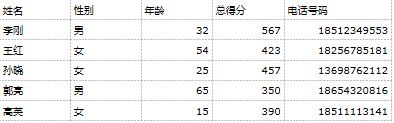
并打印到屏幕上:
姓名 性别 年龄 总得分 电话号码
0 李刚 男 32 567 18512349553
1 王红 女 54 423 18256785181
2 孙晓 女 25 457 13698762112
3 郭亮 男 65 350 18654320816
4 高英 女 15 390 18511113141
ps:这些电话号码都是我瞎编的~
二、写入文本文件
1、将列表中的元素写入新创建的文件"输出一个新的文本文件.txt"中,元素间以制表符相隔,最后加入换行符:
#!/usr/bin/env python3 #写入文本文件 output_file = "F://python入门//文件//输出一个新的文本文件.txt" my_letters = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n'] max_index = len(my_letters) filewriter = open(output_file,'w') for index_value in range(len(my_letters)): if index_value < (max_index-1): filewriter.write(my_letters[index_value]+'\t') else: filewriter.write(my_letters[index_value]+'\n') filewriter.close()
结果:
a b c d e f g h i j k l m n
2、向"输出一个新的文本文件.txt"追加新内容
#!/usr/bin/env python3 #写入文本文件 output_file = "F://python入门//文件//输出一个新的文本文件.txt" my_letters = [0,1,2,3,4,5,6,7,8,9] max_index = len(my_letters) filewriter = open(output_file,'a') for index_value in range(len(my_letters)): if index_value < (max_index-1): filewriter.write(str(my_letters[index_value])+';') else: filewriter.write(str(my_letters[index_value])+'\n') filewriter.close()
write函数处理的是字符串,在使用write函数时,需要将int型数据转换成字符串格式。
结果:
a b c d e f g h i j k l m n
0;1;2;3;4;5;6;7;8;9
