MySQL之索引
索引
知识回顾:数据都是存在于硬盘上的,查询数据不可避免的需要进行IO操作
索引:就是一种数据结构,类似于书的目录。意味着以后在查询数据的时候应该先找目录再找数据,而不是一页一页的番薯,从而提升查询熟读降低IO操作。
索引在MySQL中也叫“键”,是存储引擎用于快速查找记录的一种数据结构
- primary key
- unique
- index key
注意 foreign key 不是用来加速查询用的,不在我们的研究范围之内
上面的三种key,前面的两种除了可以增加查询速度之外各自还具有约束条件,而最后一种index key没有任何的约束条件,只是用来帮助你快速查询数据。
本质
通过不断的缩小想要的数据范围筛选出最终的结果,同时将随机事件(一页一页的翻)变成顺序事件(先找目录,再找数据),也就是说有了索引机制,我们可以总是用一种固定的方式查找数据。
一张表中可以有多个索引(多个目录)
索引虽然能够帮助你加快查询速度但是也有缺点
缺点:
- 当表中有大量数据存在的前提下,创建索引速度回很慢
- 在索引创建完毕之后,对表的查询性能会大幅度提升,但是写的性能也会大幅度的降低。
总结:
索引不要随意的创建!!!
索引操作
查看索引
语法
show index from 表名;
示例
show index from user_info; +-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | user_info | 0 | PRIMARY | 1 | id | A | 2 | NULL | NULL | | BTREE | | | +-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ desc user_info; +----------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+--------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(255) | YES | | NULL | | | password | varchar(255) | YES | | NULL | | +----------+--------------+------+-----+---------+----------------+
创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引
语法
create index 索引名 on 表名(字段名); # 索引名的命名规则一般是:index_表名_列名
示例
create index index_name on user_info(name); Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0
删除索引
语法
drop index 索引名 on 表名
示例
drop index index_name on user_info; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
索引的数据结构
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包含以下几种:
| 索引结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持B+树索引。 |
| Hash索引 | 底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询。 |
| R-tree(空间索引) | 空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式。类似于Lucene,Solr,ES。 |
B+Tree索引
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
只有叶子结点存放的是真实的数据,其他节点存放的是虚拟数据,仅仅是用来指路的。树的层级越高查询数据所需要经历的步骤就越多。而一个磁盘块存储是有限制的。

Hash索引
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
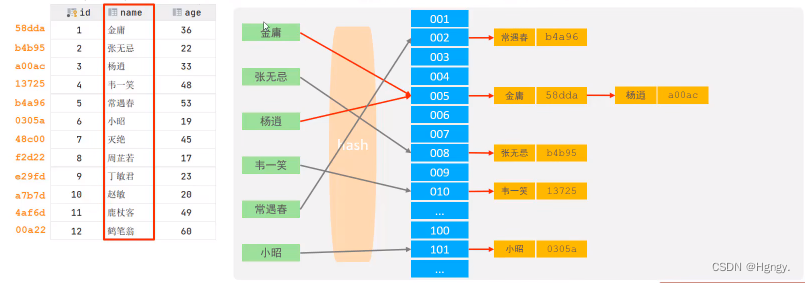
Hash索引特点:
- Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,<,....)
- 无法利用索引完成排序操作
- 查询效率高,通常只需要一次检索就可以了,效率通常要高于B+tree索引
存储引擎支持:
在MsaL中,支持hash索引的是Memory引擎,而innoDB中具有自适应hash功能,hash索引是存储引擎根据B+Tree索引在指定条件下自动构建的。
思考题:
1.为什么InnoDB存储引擎选择使用B+Tree索引结构?(面试题)
- 相对于二叉树,层级更少,搜索效率越高。
- 对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低。
- 相对Hash索引,B+Tree支持范围匹配以及排序操作。
2.为什么建议你将id字段作为索引?
- 占的空间少,一个磁盘块能够存储的数据多
- 那么就降低了树的高度,从而减少了查询次数
聚集索引(主键索引)
将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据(所有字段的值)。
- 聚集索引指的就是主键
- Innodb 只有两个文件,直接将主键存放在了idb表中
- MyIsam 三个文件,单独将索引存在一个文件
InnoDB的聚集索引图解

辅助索引(非聚集索引)
将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
查询数据的时候不可能一直使用到主键,也有可能会用到name、password等字段,那么这个时候就没有办法利用聚集索引,所以我们就可以根据情况给其他字段设置辅助索引(也是一个B+树)
- 叶子结点存放的是数据对应的主键值
- 先按照堵住索引拿到数据的主键值,之后还是需要主键的聚集索引里面来查询数据。
# 给name设置辅助索引(按照用户的名字来做辅助索引) select name from user where name='xiao';
InnoDB的非聚集索引图解

图示根据主键查询的过程:

整个查询的过程如下:
-
查询 id(主键) 为 18 的数据,SELECT id, name, age WHERE id = 18。
-
首先在「根节点:节点一」上,id = 18 落在了 15 <= id < 56 范围之内,这样我们就知道了下级节点「非叶子节点:节点2-1」的地址。
-
根据【步骤2】得到的「非叶子节点:节点2-1」的地址,找到对应的「非叶子节点:节点2-1」。然后,id = 18 又落在了 15 <= id < 20 范围之内,这样我们就知道了再下一级节点「叶子节点:节点3-1」的地址。
-
根据【步骤3】得到的「叶子节点:节点3-1」的地址,找到对应的「叶子节点:节点3-1」。最后,在「叶子节点:节点3-1」这个节点上找到 id = 18 对应的数据 {“id”: 18, “name”: “King”, “age”: 1
覆盖索引
覆盖索引(covering index ,或称为索引覆盖)即从非主键索引中就能查到的记录,而不需要查询主键索引中的记录,避免了回表的产生减少了树的搜索次数,显著提升性能。 如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫 做覆盖索引。
- 在辅助索引的叶子结点就已经拿到了需要的数据
例如: # 给name设置辅助索引(按照用户的名字来做辅助索引) select name from user where name='xiao'; 这种情况已经可以使用辅助索引来直接找到对应的数据了,就不需要再使用主键值来查找了,这就叫覆盖索引 select age from user where name='xiao'; 这种情况使用辅助索引来找对应的数据了,但是我们并没有得到相对应的数据,这就叫非覆盖索引
唯一索引(unique)
- 唯一索引是指该索引的所有值都是唯一的,不允许出现重复值。
语法
- MySQL中可以通过以下语法创建唯一索引
ALTER TABLE table_name ADD UNIQUE KEY index_name (column);
注意事项
- 与普通索引不同的是,如果尝试向包含唯一索引的列中插入重复的值,则会引发错误。
- 唯一索引可以用于确保数据的一致性和完整性,并且可以帮助提高查询性能。
组合索引(联合索引)
- 组合索引是一种由两个或更多列组成的索引。
- 当查询涉及多个列时,组合索引可以大大提高查询性能。
语法
- MySQL中可以通过以下语法创建组合索引
ALTER TABLE table_name ADD INDEX index_name (column1, column2, ...);
- 需要注意的是,组合索引中的列顺序很重要。
- 在执行查询时,MySQL会首先使用最左的列进行匹配,然后逐步向右扩展。
- 因此,应该将最常用的查询条件放在组合索引的前面。
缺点
- 例如,如果添加了不需要的列,或者删除了不需要的列,可能会导致组合索引变得无效。
- 此外,如果创建了太多的组合索引,也可能会增加索引维护的成本。
全文索引
- 全文索引是一种特殊的索引,它可以用来存储和检索文本数据。
- 全文索引可以包含单词、短语和其他类型的文本内容,并支持模糊匹配和近似匹配。
语法
- MySQL中可以通过以下语法创建全文索引
CREATE FULLTEXT INDEX index_name ON table_name (column);
注意事项
- 需要注意的是,只有MyISAM和InnoDB存储引擎支持全文索引。
- 此外,创建全文索引可能会增加索引维护的成本,并且可能会降低其他类型的查询性能。
- 因此,在创建全文索引时需要权衡其利弊。
前缀索引
- 前缀索引是一种特殊的索引,它只存储索引列的一部分,而不是完整的值。
- 前缀索引通常用于处理非常大的列,例如IP地址或邮政编码。
- 在这种情况下,全列索引可能会消耗大量的存储空间,并且可能会导致查询性能下降。
- 前缀索引可以大大减少索引大小,并且可以更快地执行范围查询。
语法
- MySQL中可以通过以下语法创建前缀索引
ALTER TABLE table_name ADD INDEX index_name (column(length));
- 其中,
length参数表示要保留的字符数。
示例
- 例如,如果我们有一个邮政编码列,并且我们只需要后两位数字进行索引,我们可以创建以下前缀索引:
ALTER TABLE table_name ADD INDEX idx_postcode(postcode(2));
- 在这个例子中,索引只会包含邮政编码的最后两位数字。
- 当我们执行范围查询时,MySQL可以直接使用前缀索引来缩小搜索范围,从而提高查询性能。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理