
Python-练习题目(21-40)
21.题目21:
交换的定义是:交换两个相邻的字符
例如mamad
第一次交换 ad : mamda
第二次交换 md : madma
第三次交换 ma : madam (回文!完美!)
第二行是一个字符串,长度为N.只包含小写字母
否则输出Impossible



''' ①判断: 若字符串长度为偶数,则每个字符出现的次数都必须是偶数次,否则不对称 若字符串长度为奇数,则只能有一个字符出现奇数次(在字符串最中间出现一次) 判断实现比较简单,注意减少代码复杂度(题给字符串长度范围是8000,python很容易运行超时) ②贪心策略: 对于偶数长度的字符串,我们从第一个开始遍历,再倒序遍历出同样的,这个倒序遍历出来的序号,就是该移动的步数。 倒序列表需要不断更新,已经构成回文的外层字符不再考虑。 对于奇数的字符串,其实贪心策略和偶数的时候一样,只不过我们一直遍历下去会有一个字符没有匹配,那么这个字符肯定是放在中间的,我们设置一个判断,假如剩余的该字符个数不是1, 按照和偶数一样的遍历,如果该字符是1,直接移动到最中间的位置。 #原文地址:https://blog.csdn.net/hallohalloha/article/details/113332805?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-2&spm=1001.2101.3001.4242 #https://blog.csdn.net/qq_45894553/article/details/104611483 ''' n = int(input()) S = list(input()) count = 0 # 用于计算交换的次数 i = 0 #用于计数外层丢弃的字符串(单侧),用来显示当前判断字符串(从前往后数)的位置 flag = 0 #用来判断是否已经有了一个单独的奇数个字符串 while len(S)>1: for k in range(len(S)-1,0,-1): if S[k] == S[0]: count += len(S) - 1 - k S.pop(0) #将开始元素pop出去,其将会导致列表的索引整体向前移动1 i += 1 S.pop(k - 1) break #找下一个 elif k == 1: #没找到相同的(孤独的),移动到中间 S.pop(0) # 单个的话,直接扔掉没事的 # impossible的两种情况: # ①偶数个字符,却存在一个字符出现奇数次 # ②奇数个字符,但已经有一个字符只出现奇数次了,不能再出现下一个 if n%2 == 0 or flag == 1:#对于flag只能一次被赋值为1,这块再来第二次的话就不是回文数了 print("Impossible") exit()# 使得程序正常退出 flag = 1 count += n//2 - i #原来字符串一半减去之前丢弃掉的单侧字符串 print(count)
22. 题目22(这个我找的代码和我的都有些瑕疵,但是系统可以100通过,希望会的大佬可以帮下小弟):
Tom教授正在给研究生讲授一门关于基因的课程,有一件事情让他颇为头疼:一条染色体上有成千上万个碱基对,它们从0开始编号,到几百万,几千万,甚至上亿。
比如说,在对学生讲解第1234567009号位置上的碱基时,光看着数字是很难准确的念出来的。
所以,他迫切地需要一个系统,然后当他输入12 3456 7009时,会给出相应的念法:
十二亿三千四百五十六万七千零九
用汉语拼音表示为
shi er yi san qian si bai wu shi liu wan qi qian ling jiu
这样他只需要照着念就可以了。
你的任务是帮他设计这样一个系统:给定一个阿拉伯数字串,你帮他按照中文读写的规范转为汉语拼音字串,相邻的两个音节用一个空格符格开。
注意必须严格按照规范,比如说“10010”读作“yi wan ling yi shi”而不是“yi wan ling shi”,“100000”读作“shi wan”而不是“yi shi wan”,“2000”读作“er qian”而不是“liang qian”。
#原文地址:https://blog.csdn.net/qq_42212961/article/details/103687709 #1.初始化及变量 num = list(map(int, input())) wei = {1:'shi', 2:'bai', 3:'qian', 4:'wan',5:'shi', 6:'bai', 7:'qian', 8:'yi', 9:'shi'} yin = {1:'yi', 2:'er', 3:'san', 4:'si', 5:'wu', 6:'liu', 7:'qi', 8:'ba', 9:'jiu'} qu = {1:'wan',2:'yi'} all_yin = [] ''' 1234: 1 在 yin里边,读作'yi',all_yin加'yi'; len(num)-1-i = 4-1-0 = 3(对应于qian) # len(num)-1是因为没有个位 ''' def elseWei(j): if num[j:] == ['0']*(len(num)-1-j): return True else: return False def fayin(num): for i in range(len(num)): #1.特殊的0的发言处理: if num[i] == 0 and i < len(num) - 1: #123005,底下有个i+1会出范围 if num[i+1] != 0 and (len(num)-1-i == 9 or len(num) - 1 - i == 5): all_yin.append('ling') if len(num)//4 != 0 and elseWei(i): all_yin.append(qu[len(num)//4]) continue continue #结束本次循环 #2.高位的10 #主体部分 if num[i] in yin: #判断key是否在yin里边 all_yin.append(yin[num[i]]) if len(num)-1-i in wei: all_yin.append(wei[len(num)-1-i]) return all_yin all_yin = fayin(num) print(' '.join(all_yin)) #这个还是挺好用的
23.题目23
最近FJ为他的奶牛们开设了数学分析课,FJ知道若要学好这门课,必须有一个好的三角函数基本功。所以他准备和奶牛们做一个“Sine之舞”的游戏,寓教于乐,提高奶牛们的计算能力。
不妨设
An=sin(1–sin(2+sin(3–sin(4+...sin(n))...)
Sn=(...(A1+n)A2+n-1)A3+...+2)An+1
FJ想让奶牛们计算Sn的值,请你帮助FJ打印出Sn的完整表达式,以方便奶牛们做题。
仅有一个数:N<201。
请输出相应的表达式Sn,以一个换行符结束。输出中不得含有多余的空格或换行、回车符。
#Sine之舞 #本代码并不是本人原创; #源码地址:https://www.cnblogs.com/fate-/p/12294459.html def An(n,s): for i in range(1,n+1): s = s + "sin({}".format(i) if i != n: if i%2 == 1: s = s + "-" else: s = s + "+" else: s = s + ")"*n return s def sn(n,s): s = s + "("*(n-1) for i in range(1,n+1): s = An(i,s) s = s + "+{}".format(n-i+1) if i != n: s = s + ")" return s def main(): n = int(input()) s = '' s = sn(n,s) print(s) if __name__ == '__main__': main() ''' an就先输出一个sin(+数字 如果数字没到n的话,数字是奇数就加减号,偶数就加加号 到n的话,输出n个括号 sn要先输出n-1个括号 然后调用an 然后+数字 数字是从n到1 数字没到1·的话,就接括号 到1的话,就啥也不接。 '''
24.题目24
FJ在沙盘上写了这样一些字符串:
A1 = “A”
A2 = “ABA”
A3 = “ABACABA”
A4 = “ABACABADABACABA”
… …
你能找出其中的规律并写所有的数列AN吗?
def FJ(N,letters,S): AN = [] #用来存储每次的An AN.append(S) for i in range(N): AN.append(AN[i] + letters[i+1] + AN[i]) return AN def main(): #1.产生所有字母 N = int(input()) #An的N letters = '' #存储所有的字母 for i in range(26): letters += chr(ord("A") + i) S = 'A'#每次递归的字符串 #2.FJ,返回来一个列表 AN = FJ(N,letters,S) #3.格式化输出 result = list(AN[-2]) #因为有个'A' print("".join(result)) if __name__ == "__main__": main()
25.题目25(这个看测评的输入,输出都是正确的,不知道为什么不对)
每个芯片都能用来测试其他芯片。用好芯片测试其他芯片时,能正确给出被测试芯片是好还是坏。而用坏芯片测试其他芯片时,会随机给出好或是坏的测试结果(即此结果与被测试芯片实际的好坏无关)。
给出所有芯片的测试结果,问哪些芯片是好芯片。
第二行到第n+1行为n*n的一张表,每行n个数据。表中的每个数据为0或1,在这n行中的第i行第j列(1≤i, j≤n)的数据表示用第i块芯片测试第j块芯片时得到的测试结果,1表示好,0表示坏,i=j时一律为1(并不表示该芯片对本身的测试结果。芯片不能对本身进行测试)。
#解析:题目中已知好的芯片比坏的芯片多,而且用每个芯片都测试其他的芯片, #所有对于一个芯片来说,当测试结果为好的次数大于测试结果为坏的次数时,他就是好的芯片。 import numpy as np #1.输入存储 n = int(input()) #芯片的个数 a = np.zeros((n,n)) i = 0 while i<n: a[i] = list(map(int,input().split())) i = i + 1 #2.判断 sum1 = np.sum(a,axis = 0) #0竖着,1横着 result = []#存储每片芯片的判断结果 for i in range(n): if n%2 == 1: if sum1[i] > n//2: #奇数,因为有个1是自己判断自己的 result.append(1) else: result.append(0) else: if sum1[i] >= n//2: #因为有个1是自己判断自己的 result.append(1) else: result.append(0) #3.输出 result1 = [str(i+1) for i in range(n) if result[i] != 0] #[表达式 for 迭代变量 in 可迭代对象 [if 条件表达式] ] print(" ".join(result1)) #join期待的是一个存放字符串的列表
26.题目26:
给定一个系统时间,输出HH:MM:SS;
例如:
输入:46800999 输出:13:00:00
输入:1618708103123 输出:01:08:23
t = int(input()) # ms 46800999 1618708103123 d = 60*60*24 h = 60*60 # s m = 60 # s t = int(t/1000) # s s = '' if t/h >= 24: str_h = str(int(t/h)%24) if int(t/h)%24>9 else '0' + str(int(t/h)%24) t = t- (int(t/(3600*24)))*(3600*24) else: str_h = str(int(t/h)) if int(t/h) != 0 else '00' # print(str_h) fen_miao = t - int(str_h)*60*60 # 除了h后余下的秒 str_m = str(int(fen_miao/60)) if int(fen_miao/m) > 9 else '0' + str(int(fen_miao/m)) # print(str_m) miao = fen_miao - int(str_m)*60 # 剩余的秒 str_miao = str(miao) if miao>9 else '0' + str(miao) # print(str_miao) print(str_h + ':' + str_m + ':' + str_miao)
27.题目27:
ip_list = input().split(".") flag = True for num in ip_list: if len(ip_list) == 4 and num.isdigit() and 0 <= int(num) <= 255: continue else: flag = False break print(flag)
28. Python约瑟夫环,1->n编号,第s个人报数,到m出圈; 输出最后一个出圈的人:
def circle_sort(n, s, m): # 1->n编号,第s个人报数,到m出圈; 输出最后一个出圈的人 x_list = list(range(1, n + 1)) x_new_list = x_list[s - 1:] + x_list[:s - 1] temp_index = 0 while len(x_new_list) != 1: if temp_index + m - 1 < len(x_new_list): temp_index = temp_index + m - 1 else: temp_index = (temp_index + m - 1) % len(x_new_list) x_new_list.pop(temp_index) print(x_new_list) circle_sort(7, 2, 3) circle_sort(3, 1, 2)
29. 超级玛丽过吊桥:
# 华为超级玛过吊桥 ''' 生命数:M 吊桥的长度:N 缺失的木板数:K 缺失的木板:L 解决: 每次判断生命数M、当前是否到达N 输入1: 1 3 2 1 3 输出1: 1 输入2: 2 2 1 2 输出2: 4 ''' def find_num(life: int, current: int, step: int): current += step global N global NUM if current < N: if A[current] == 0: life -= 1 if life > 0: find_num(life, current, 1) find_num(life, current, 2) find_num(life, current, 3) else: find_num(life, current, 1) find_num(life, current, 2) find_num(life, current, 3) elif current == N: NUM += 1 if __name__ == '__main__': M, N, K = 2, 2, 1 L = [2, ] A = [1] * 32 # 32个木板,最大的木板长度 NUM = 0 # 过关次数 for i in L: # 陷阱 A[i - 1] = 0 find_num(M, -1, 1) find_num(M, -1, 2) find_num(M, -1, 3) print(NUM)
30. 数据包传输:
# 华为传输包 ''' 1. 按照数据包大小排序 2. 先弄大的,再弄小的(有多个选择尽量找空闲) M:队列长度 N:通道个数 P:通道大小 Q:数据包大小 S:数据包时间 ''' if __name__ == '__main__': M, N = 3, 2 # 3, 2 # 5, 2 P = [6, 13] # [6, 13] # [5, 3] sorted(P) Q = [2, 11, 5] # [2, 11, 5] # [1, 4, 5, 2, 3] S = [3, 25, 14] # [3, 25, 14] # [1, 6, 10, 3, 4] qs = list(zip(Q, S)) for i in range(len(qs) - 1): for j in range(i, len(qs)): if qs[i][0] < qs[j][0]: temp = qs[i] qs[i] = qs[j] qs[j] = temp flag = [0]*N # 指示当前通道有几个在传 flag_time = [0]*N # 指示当前通道花费的时间 for item in qs: temp_num = [1 if item[0] <= i else 0 for i in P] # 通道标志位,是否可传 # 1. 只可选择其中的一个通道 if temp_num.count(1) == 1: flag[temp_num.index(1)] += 1 flag_time[temp_num.index(1)] += item[1] continue # 2. 可选择其余通道 # 2.1 找空闲通道传(找出空闲通道的index) min_index = flag.index(min(flag)) if [flag[0]] * N == flag: # 所有通道占用情况都是一样的,选择时间少的那个通道 short_time_index = flag_time.index(min(flag_time)) flag[short_time_index] += 1 flag_time[short_time_index] += item[1] elif item[0] <= P[min_index]: # 可去通道 flag[min_index] += 1 flag_time[min_index] += item[1] else: # 非空闲通道 no_free_index = temp_num.index(1) flag[no_free_index] += 1 flag_time[no_free_index] += item[1] print(max(flag_time))
31. 能整除1-n的最小数
x = [0, 1, 2, 6, 12] n = 100 for i in range(5, n): j = 1 while True: temp = j * x[i - 1] if temp % i == 0: x.append(temp) break j += 1 print(x)
32. python实现数据库的查询功能——找出每个类别中年龄最大的两个人
# // 现在有这样一份数据: # // 1,huangxiaoming,45,a # // 2,huangzitao,36,b # // 3,huanglei,41,c # // 4,liushishi,22,a # // 5,liudehua,39,b # // 6,liuyifei,35,c # // 7,huangxiaoming,41,a # // 8,huangzitao,33,b # // 9,huanglei,32,c # // 10,liushishi,44,a # // 11,liudehua,18,b # // 12,liuyifei,55,c # // 字段的意义: # // id,name,age,favors # // id,姓名,年龄,爱好 # // 需求: # // 求出每种爱好中,年龄最大的两个人(爱好,年龄,姓名) data = [[1, 'huangxiaoming', 45, 'a'], [2, 'huangzitao', 36, 'b'], [3, 'huanglei', 41, 'c'], [4, 'liushishi', 22, 'a'], [5, 'liudehua', 39, 'b'], [6, 'liuyifei', 35, 'c'], [7, 'huangxiaoming', 41, 'a'], [8, 'huangzitao', 33, 'b'], [9, 'huanglei', 32, 'c'], [10, 'liushishi', 44, 'a'], [11, 'liudehua', 18, 'b'], [12, 'liuyifei', 55, 'c']] all_keys = list(set([i[3] for i in data])) result = {i: [] for i in all_keys} for i in data: result[i[3]].append(i) for key, values in result.items(): result[key] = sorted(values, key=lambda x: x[2], reverse=True)[-2:] print(result)
33. leetcode 859. 亲密字符串
# 给定两个由小写字母构成的字符串 A 和 B ,只要我们可以通过交换 A 中的两个字母得到与 B 相等的结果,就返回 true ;否则返回 false 。 # # 示例 1: # # 输入: A = “ab”, B = “ba” # 输出: true # 示例 2: # # 输入: A = “ab”, B = “ab” # 输出: false # 示例 3: # # 输入: A = “aa”, B = “aa” # 输出: true # 示例 4: # # 输入: A = “aaaaaaabc”, B = “aaaaaaacb” # 输出: true # 示例 5: # # 输入: A = “”, B = “aa” # 输出: false # # 提示: # # 0 <= A.length <= 20000 # 0 <= B.length <= 20000 # A 和 B 仅由小写字母构成。 # 解题思路 # # 字符串长度不相等, 直接返回false # 字符串相等的时候, 只要有重复的元素就返回true # A, B字符串有不相等的两个地方,需要查看它们交换后是否相等即可。 # ———————————————— # 版权声明:本文为CSDN博主「算法黑哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 # 原文链接:https://blog.csdn.net/weixin_41504611/article/details/104645845 class Solution(object): def buddyStrings(self, A: str, B: str) -> bool: if len(A) != len(B): return False if A == B: if len(set(A)) <len(A): return True return False res = [] for i in range(len(A)): if A[i] != B[i]: res.append(i) if len(res) > 2: return False if len(res) == 1: return False if A[res[0]] == B[res[1]] and A[res[1]] == B[res[0]]: return True return False s = Solution() A = input() B = input() print(s.buddyStrings(A=A, B=B))
34. 数字字母排序
题目:给定一个仅包含字母和数字的字符串,对其做如下修改:
1. 字母顺序不变,位置不变;
2. 数字整体参与排序,升序和降序按照第一个和最后一个字母的字典序列进行升序排列
3. 任意两个字母之间的数字,按照首尾两个字母进行字典序,进行升序或者降序排列,如果相同则默认升序拍了
4. 局部字母数量不足不满足排序条件,使用整体排序,如果整体排序没有,则保持升序输出;
输入和输出:
输入1:a143b
输出1:a134b
输入2:b143a
输出2:b431a
输入3:aD132b45c978b65
输出3:aD123b45c765b89
import copy ''' 题目:给定一个仅包含字母和数字的字符串,对其做如下修改: 1. 字母顺序不变,位置不变; 2. 数字整体参与排序,升序和降序按照第一个和最后一个字母的字典序列进行升序排列 3. 任意两个字母之间的数字,按照首尾两个字母进行字典序,进行升序或者降序排列,如果相同则默认升序拍了 4. 局部字母数量不足不满足排序条件,使用整体排序,如果整体排序没有,则保持升序输出; 输入和输出: 输入1:a143b 输出1:a134b 输入2:b143a 输出2:b431a 输入3:aD132b45c978b65 输出3:aD123b45c765b89 ''' x = 'a143b' # input() # 'a143b' # 'b143a' # 'aD132b45c978b65' out = [] i = 0 j = 0 # 0. 找出数字的位置并参与整体排序 x = list(x) num_index_list = [i for i in range(len(x)) if x[i].isdigit()] num_value_list = [x[i] for i in range(len(x)) if x[i].isdigit()] num_value_list = sorted(num_value_list) for index, value in zip(num_index_list, num_value_list): x[index] = value # 1. 先切分 flag = True # while i <= len(x) - 1: temp = [] temp_s = x[i] for j in range(i, len(x)): if not temp_s.isdigit() == x[j].isdigit(): break else: temp.append(x[j]) out.append(copy.copy(temp)) if (j == len(x) - 1) and (x[-1].isdigit() == x[-2].isdigit()): # 最后一个和前面有联系,导致退出的,直接结束 break elif (j == len(x) - 1) and (x[-1].isdigit() != x[-2].isdigit()): # 最后一个和前面没联系,追加后退出 out.append([x[-1]]) break i = j # [['a', 'D'], ['1', '3', '2'], ['b'], ['4', '5'], ['c'], ['9', '7', '8'], ['b'], ['6', '5']] print(out) # 2. 再排序 for item_i in range(len(out)): if out[item_i][0].isdigit(): # 当前是数字,需要排序 # 判断是升序还是降序 # 判断是否超出范围: if (item_i + 1 <= len(out) - 1) and (item_i - 1 >= 0): # 在中间要根据左右判断 if out[item_i - 1][0] < out[item_i + 1][-1]: # 升序 out[item_i] = sorted([int(s) for s in out[item_i]]) else: # 降序 out[item_i] = sorted([int(s) for s in out[item_i]], reverse=True) elif (item_i == 0) or (item_i == len(x) - 1): # 在开头或者结尾直接升序 item_i = [int(s) for s in out[item_i]] item_i = sorted(item_i) out[item_i] = sorted([int(s) for s in out[item_i]]) else: # 不管 pass # 3. 输出 outs = ''.join([str(j) for i in out for j in i]) print(outs)
35. 给出一个未排序的整数数组,请写出能够文现找出其中没有出现的最小的正整数的函数
# 1. 给出一个未排序的整数数组,请写出能够文现找出其中没有出现的最小的正整数的函数
# 输入:[1,2,0]
# 输出:3
# 1. 给出一个未排序的整数数组,请写出能够文现找出其中没有出现的最小的正整数的函数 # 输入:[1,2,0] # 输出:3 # class Solution: # def firstMissingPositive(self, nums): # n = len(nums) # for i in range(n): # if nums[i] <= 0: # nums[i] = n + 1 # # for i in range(n): # num = abs(nums[i]) # if num <= n: # nums[num - 1] = -abs(nums[num - 1]) # # for i in range(n): # if nums[i] > 0: # return i + 1 # # return n + 1 # # # s = Solution() # print(s.firstMissingPositive(nums=[1, 2, 0]))
36. 在始定的numpy数组中找到重复的条目(第二次出现以后),并将它们标记为True(第一次出现应该为False)
# 输入:[[0, 0, 3, 0], [2, 4, 2, 2]]
# 输出:[[False, True, False, True], [False, False, True, True]]
# https://blog.csdn.net/qq_70770395/article/details/127422954
# 2. 在始定的numpy数组中找到重复的条目(第二次出现以后),并将它们标记为True(第一次出现应该为False) # 输入:[[0, 0, 3, 0], [2, 4, 2, 2]] # 输出:[[False, True, False, True], [False, False, True, True]] # https://blog.csdn.net/qq_70770395/article/details/127422954 import numpy as np class Solution: def search_elements(self, ori_array): m, n = len(ori_array), len(ori_array[0]) b = np.concatenate(np.array(ori_array)) b.fill(True) ori_array = np.array(ori_array) vals, counts = np.unique(ori_array, return_index=True) b[counts] = False b = b.reshape((m, n)) out = [] for i in b: temp = [] for j in i: if j: temp.append(True) else: temp.append(False) out.append(temp) return out s = Solution() out = s.search_elements([[0, 0, 3, 0], [2, 4, 2, 2]]) print(out) # np.random.seed(100) # a = np.random.randint(0, 5, 10) # print(a) # # [0 0 3 0 2 4 2 2 2 2] # b = np.full(10, True) # print(b) # vals, counts = np.unique(a, return_index=True) # b[counts] = False # print(b) # # [False True False True False False True True True True]
37. 二叉树知道后序和中序求前续
class node: # 定义节点结构 def __init__(self, value=None, left=None, right=None): self.value = value self.left = left self.right = right def GetTwoTree(str1, str2): # str1为后序 str2为中序 root = node(str1[-1]) # 先给第一个值 Index = str2.index(root.value) # 根在中序中的索引 leftstr2 = str2[: Index] # 中序中的左半部分 maxindex = -1 for i in leftstr2: # 分离后序序列 tmpindex = str1.index(i) if maxindex < tmpindex: maxindex = tmpindex if len(leftstr2) == 1: # 如果只有一个元素 root.left = node(leftstr2) # 直接赋值 elif len(leftstr2) == 0: # 如果没有元素 root.left = None # 空 else: # 否则递归 root.left = GetTwoTree(str1[:maxindex + 1], leftstr2) # 递归构造左子树 rightstr2 = str2[Index + 1:] # 中序中的右半部分 if len(rightstr2) == 1: root.right = node(rightstr2) elif len(rightstr2) == 0: root.right = None else: root.right = GetTwoTree(str1[maxindex + 1:-1], rightstr2) # 递归构造右子树 return root def preTraverse(root): # 递归先序遍历 if root != None: print(root.value) preTraverse(root.left) preTraverse(root.right) if __name__ == '__main__': str1 = 'DABEC' # str1为后序结果 str2为中序结果 str2 = 'DEBAC' root = GetTwoTree(str1, str2) # 构造二叉树 preTraverse(root) # 遍历输出
38. 二叉树知道前序和中序求后续
def ToPostOrder(Pre,InOrder): length = len(Pre) if length == 0: return 0 root = Pre[0] # 前序遍历的根节点 for i in range(length): # 循环找到中序遍历中根节点的位置 if root == InOrder[i]: break ToPostOrder(Pre[1:i+1],InOrder[0:i])#递归,传入左子树的前序遍历序列和左子树的中序遍历序列 ToPostOrder(Pre[i+1:length],InOrder[i+1:length])#递归,传入右子树的前序遍历序列和右子树的中旭遍历序列 print(root,end="") #输出根节点数据,在递归中,为左右子树的根 ToPostOrder("126745","627154") print("\n") # ———————————————— # 版权声明:本文为CSDN博主「子滨」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 # 原文链接:https://blog.csdn.net/weixin_46079657/article/details/114754844
39. 归并
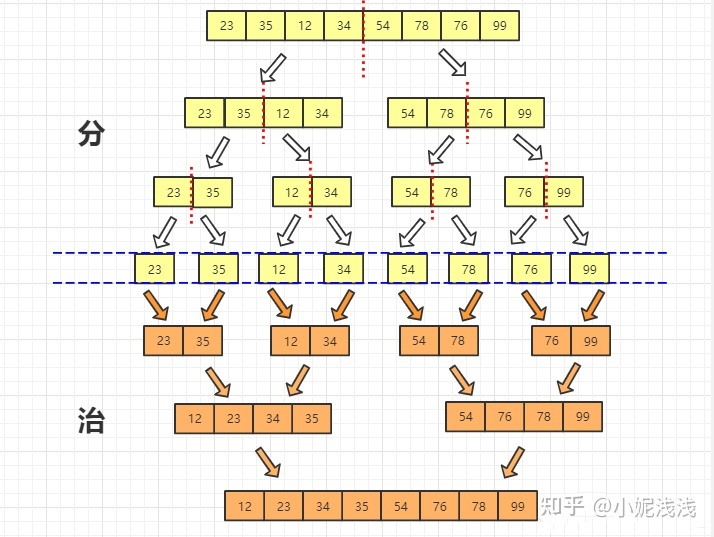
# https://zhuanlan.zhihu.com/p/347748325 #归并排序 def merge_sort(alist): n = len(alist) if n <= 1: return alist mid = n // 2 #left_li、right_li代表归并排序后形成的有序的新的列表 left_li = merge_sort(alist[:mid]) right_li = merge_sort(alist[mid:]) left_pointer, right_pointer = 0, 0 result = [] while left_pointer < len(left_li) and right_pointer < len(right_li): if left_li[left_pointer] <= right_li[right_pointer]: result.append(left_li[left_pointer]) left_pointer += 1 else: result.append(right_li[right_pointer]) right_pointer += 1 result += left_li[left_pointer:] result += right_li[right_pointer:] return result if __name__ == '__main__': li = [7,3,5,7,4,0,2,9,1,] print(li) #[7, 3, 5, 7, 4, 0, 2, 9, 1] sorted_li = merge_sort(li) print(li) #[7, 3, 5, 7, 4, 0, 2, 9, 1] print(sorted_li) #[0, 1, 2, 3, 4, 5, 7, 7, 9]
40. 快排
array = [30,24,5,58,18,36,12,42,39]为例,进行演示 # 一个一个把数字放到该放的位置;小的放前面,大的放后面; 1、初始化,i=0, j=len(L), pivot=array [low]=30 30,24,5,58,18,36,12,42,39 2、从后往前找小于等于pivot的数,找到R[j]=12,R[i]与R[j]交换,i++,i=1, j=6, pivot=array [j]=30 12,24,5,58,18,36,30,42,39 3、从前往后找大于pivot的数,找到R[3]=58,R[i]与R[j]交换,j--,i=3, j=6, pivot=array [i]=30 12,24,5,30,18,36,58,42,39 4、从后往前找小于等于pivot的数,找到R[4]=18,R[i]与R[j]交换,i++,i=4, j=4, pivot=array [i]=30 12,24,5,18,30,36,58,42,39 5、从前往后找大于pivot的数,这时i=j,第一轮排序结束,返回i的位置,mid=i 此时已mid为界,将原序列一分为二,左子序列为(12,24,5,18)元素都比pivot小,右子序列为(36,58,42,39)元素都比pivot大。然后在分别对两个子序列进行快速排序,最后即可得到排序后的结果。 # https://zhuanlan.zhihu.com/p/63227573 def quick_sort(lists,i,j): if i >= j: return list pivot = lists[i] low = i high = j while i < j: while i < j and lists[j] >= pivot: j -= 1 lists[i]=lists[j] while i < j and lists[i] <=pivot: i += 1 lists[j]=lists[i] lists[j] = pivot quick_sort(lists,low,i-1) quick_sort(lists,i+1,high) return lists if __name__=="__main__": lists=[30,24,5,58,18,36,12,42,39] print("排序前的序列为:") for i in lists: print(i,end =" ") print("\n排序后的序列为:") for i in quick_sort(lists,0,len(lists)-1): print(i,end=" ")

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步