
MySql学习-5.索引与开窗函数
1. 索引
1.1 概念:
索引是 MySQL 中一种十分重要的数据库对象。它是数据库性能调优技术的基础,常用于实现数据的快速检索。 索引就是根据表中的一列或若干列按照一定顺序建立的列值与记录行之间的对应关系表,实质上是一张描述索引列的列值与原表中记录行之间一一对应关系的有序表。 在 MySQL 中,通常有以下两种方式访问数据库表的行数据: 1) 顺序访问 顺序访问是在表中实行全表扫描,从头到尾逐行遍历,直到在无序的行数据中找到符合条件的目标数据。这种方式实现比较简单,但是当表中有大量数据的时候,效率非常低下。 2) 索引访问 索引访问是通过遍历索引来直接访问表中记录行的方式。使用这种方式的前提是对表建立一个索引,在列上创建了索引之后,查找数据时可以直接根据该列上的索引找到对应记录行的位置,从而快捷地查找到数据。索引存储了指定列数据值的指针,根据指定的排序顺序对这些指针排序。 例如,在学生基本信息表 students 中,如果基于 student_id 建立了索引,系统就建立了一张索引列到实际记录的映射表,当用户需要查找 student_id 为 12022 的数据的时候,系统先在 student_id 索引上找到该记录,然后通过映射表直接找到数据行,并且返回该行数据。因为扫描索引的速度一般远远大于扫描实际数据行的速度,所以采用索引的方式可以大大提高数据库的工作效率。
1.2 索引的分类:
###根据存储方式的不同,MySQL 中常用的索引在物理上分为以下两类。### ##B-树索引## B-树索引又称为 BTREE 索引,目前大部分的索引都是采用 B-树索引来存储的。B-树索引是一个典型的数据结构,基于这种树形数据结构,表中的每一行都会在索引上有一个对应值。因此,在表中进行数据查询时,可以根据索引值一步一步定位到数据所在的行。(类似于Linux的目录结构)
##哈希索引## 哈希(Hash)一般翻译为“散列”,也有直接音译成“哈希”的,就是把任意长度的输入(又叫作预映射,pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。 HASH 索引不是基于树形的数据结构查找数据,而是根据索引列对应的哈希值的方法获取表的记录行。
##根据索引的具体用途,MySQL 中的索引在逻辑上分为以下 3 类:## √ ##普通索引## 普通索引是最基本的索引类型,唯一任务是加快对数据的访问速度,没有任何限制。创建普通索引时,通常使用的关键字是 INDEX 或 KEY。 ##唯一性索引## 唯一性索引是不允许索引列具有相同索引值的索引。如果能确定某个数据列只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该用关键字 UNIQUE 把它定义为一个唯一性索引。 创建唯一性索引的目的往往不是为了提高访问速度,而是为了避免数据出现重复。 ##主键索引## 主键索引是一种唯一性索引,即不允许值重复或者值为空,并且每个表只能有一个主键。主键可以在创建表的时候指定,也可以通过修改表的方式添加,必须指定关键字 PRIMARY KEY。
1.3 索引的操作:
1.3.1 普通索引
# (1)创建索引:方式1-直接创建 # CREATE INDEX indexName ON mytable(username([length])); # 如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。 create index price_index on products(price) # (2)创建索引:方式2-修改表结构 # ALTER table tableName ADD INDEX indexName(columnName) alter table products add index pname_index(pname) # (3)创建索引:方式3-创建表的时候直接指定 CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX indexName(username(length)) ); create table products( id int not null, username varchar(16) not null, index username_index(username) )
# 查询索引-----------不用记------------# #1、查看表中所有索引 # SHOW INDEX FROM table_name; SHOW INDEX FROM peoducts; #2、查看数据库所有索引 SELECT * FROM mysql.`innodb_index_stats` a WHERE a.`database_name` = '数据库名'; #3、查看某一表索引 SELECT * FROM mysql.`innodb_index_stats` a WHERE a.`database_name` = '数据库名' and a.table_name like '%表名%';
# 删除索引 # DROP INDEX [indexName] ON mytable; drop index pname_index on products; # alter table mytable drop index indexName; alter table producrs drop index price_index;
1.3.2 唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
# 创建索引 #方式1-直接创建 # CREATE UNIQUE INDEX indexName ON mytable(username(length)) create unique index pname_index on products(pname) #方式2-修改表结构(添加索引) ALTER table mytable ADD UNIQUE [indexName] (username(length)) alter table products add unique pname_index2(pname) #方式3-创建表的时候直接指定 CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, UNIQUE [indexName] (username(length)) ); CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, UNIQUE index_username(username) );
# 删除索引 # DROP INDEX [indexName] ON mytable; drop index pname_index on products; # alter table mytable drop index indexName; alter table products drop index pname_index;
1.3.3 主键索引
见主键约束(4.1 主键约束):https://www.cnblogs.com/xiao-yu-/p/12337135.html
1.4 索引的使用原则和注意事项
虽然索引可以加快查询速度,提高 MySQL 的处理性能,但是过多地使用索引也会造成以下弊端:
1.创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
2.除了数据表占数据空间之外,每一个索引还要占一定的物理空间。如果要建立聚簇索引,那么需要的空间就会更大。
3.当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。(衡量能不能?)
4.对于那些在查询中很少使用或参考的列不应该创建索引。因为这些列很少使用到,所以有索引或者无索引并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度,并增大了空间要求。
2. 开窗函数
2.1 简介:
# MySql在8.0的版本增加了对开窗函数的支持,终于可以在MySql使用开窗函数了。 # 开窗函数的语法结构: #Key word :Partiton by & order by <开窗函数> over ([PARTITION by <列清单>] Order by <排序用列清单>) Mysql中支持的开窗函数有很多,这里重点给大家介绍三个:row_number(),rank() ,dense_rank()
2.2 开窗函数介绍:
row_number(),rank(),dense_rank()这三个函数都是用于返回结果集的分组内每行的排名 三者区别: row_number:不管排名是否有相同的,都按照顺序1,2,3…..n rank:排名相同的名次一样,同一排名有几个,后面排名就会跳过几次 dense_rank:排名相同的名次一样,且后面名次不跳跃
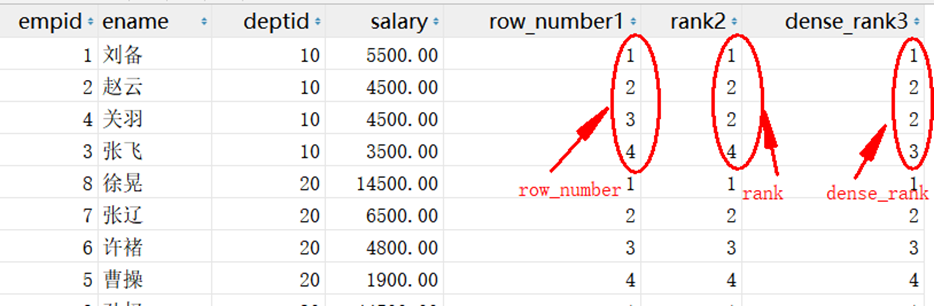
2.3 案例
2.3.1 数据准备
create table employee (empid int,ename varchar(20) ,deptid int ,salary decimal(10,2)); insert into employee values(1,'刘备',10,5500.00); insert into employee values(2,'赵云',10,4500.00); insert into employee values(2,'张飞',10,3500.00); insert into employee values(2,'关羽',10,4500.00); insert into employee values(3,'曹操',20,1900.00); insert into employee values(4,'许褚',20,4800.00); insert into employee values(5,'张辽',20,6500.00); insert into employee values(6,'徐晃',20,14500.00); insert into employee values(7,'孙权',30,44500.00); insert into employee values(8,'周瑜',30,6500.00); insert into employee values(9,'陆逊',30,7500.00);
2.3.2 代码:
# 分组排序打编号
# 对employee表中按照deptid进行分组,并对每一组的员工按照薪资进行排名: # empid 就是index # ename 姓名 # deptid 所属国家 # salary 薪资 SELECT empid, ename, deptid, salary, row_number() over (PARTITION BY deptid ORDER BY salary DESC) AS row_number1, # PARTITION BY 分组的意思 rank() OVER (PARTITION BY deptid ORDER BY salary desc) AS rank2, dense_rank() OVER (PARTITION BY deptid ORDER BY salary desc) AS dense_rank3 FROM employee;
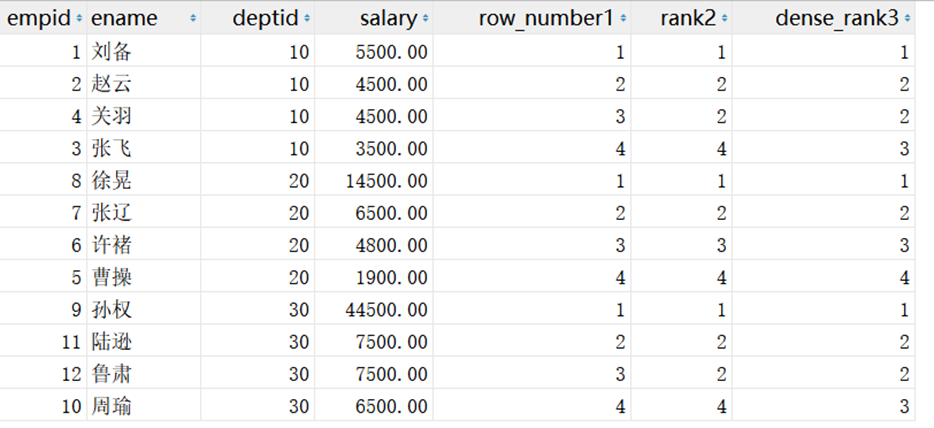
# 全表排序打编号 SELECT empid, ename, deptid, salary, row_number() over (BY deptid ORDER BY salary DESC) AS row_number1, FROM employee;
# 查询每一组中薪资最高的员工:TopN select * from ( SELECT empid, ename, deptid, salary, row_number() over (PARTITION BY deptid ORDER BY salary DESC) AS row_number1, FROM employee; ) t where t.row_number1 = 1; # <=2
# 全表求TopN select * from ( SELECT empid, ename, deptid, salary, rank() OVER (BY deptid ORDER BY salary desc) AS rank1, FROM employee; ) t where t.rank1<=3;

