mysql主从同步异常原因及恢复
mysql主从同步异常原因及恢复
前言
mysql数据库做主从复制,不仅可以为数据库的数据做实时备份,保证数据的完整性,还能做为读写分离,提升数据库的整体性能。但是,mysql主从复制经常会因为某些原因使主从数据同步出现异常。因此,下面介绍的是mysql主从同步异常的原因及恢复的方法。
auto.cnf 配置问题
这个问题是在部署主从复制的时候,可能会遇到的
【1】报错
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work
【2】分析:
当mysql做了主从时,每个mysql都会有个uuid 作为唯一标识的。上面是由于主从复制的mysql数据库了相同的UUID,所以,只需要修改auto.cnf配置文件即可。
【3】解决方法
<1>查找auto.cnf文件的位置(位置一般为:/var/lib/mysql/auto.cnf)
find / -iname auto.cnf
<2>将文件中的uuid修改为不同数值。
my.cnf配置问题
这个问题也是在部署主从复制的时候,可能会遇到的
【1】报错
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids; these ids must be different for replication to work (or the –replicate-same-server-id option must be used on slave but this does not always make sense; please check the manual before using it).
【2】分析
在mysql的主从配置中,每台mysql数据库的my.cnf中的server-id 必须是唯一,但是有的时候可能因为粗心而配成了相同的数值,也有可能mysql没有加载到my.cnf 文件中的server-id。
【3】解决方法
<1>找到mysql的配置文件my.cnf(默认位置为:/etc/my.cnf)
find / -name my.cnf
<2>修改从服务器的my.cnf配置文件中的server-id(注意要改为与主服务器不同的)
<3>在从服务器的数据库中直接添加server_id(此server_id数值与my.cnf中的一致)
mysql> set global server_id=2;
mysql> start slave;
主库重启(数据库服务器宕机)
重点问题
这个问题常见于运维mysql数据库主从的过程中,一般都是由于数据库的误操作引起的,也有可能是数据库服务器因某些原因宕机或重启引起的。
数据库备份一定要定期进行,确保数据万无一失 .
【1】报错
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ‘binlog truncated in the middle of event; consider out of disk space on master; the first event ‘mysql-bin.001989’ at 9179, the last event read from ‘./mysql-bin.001989’ at 9179, the last byte read from ‘./mysql-bin.001989’ at 9179.’
【2】分析
由报错可看出是由于从库的二进制文件位置与主库的不一致导致的
【3】解决方法
<1>查看主库的二进制文件的位置
mysql -uroot -p’…..’ 进入数据库
show master status; 查看主库

重点关注:
File 与 Position
<2>查看从库的状态
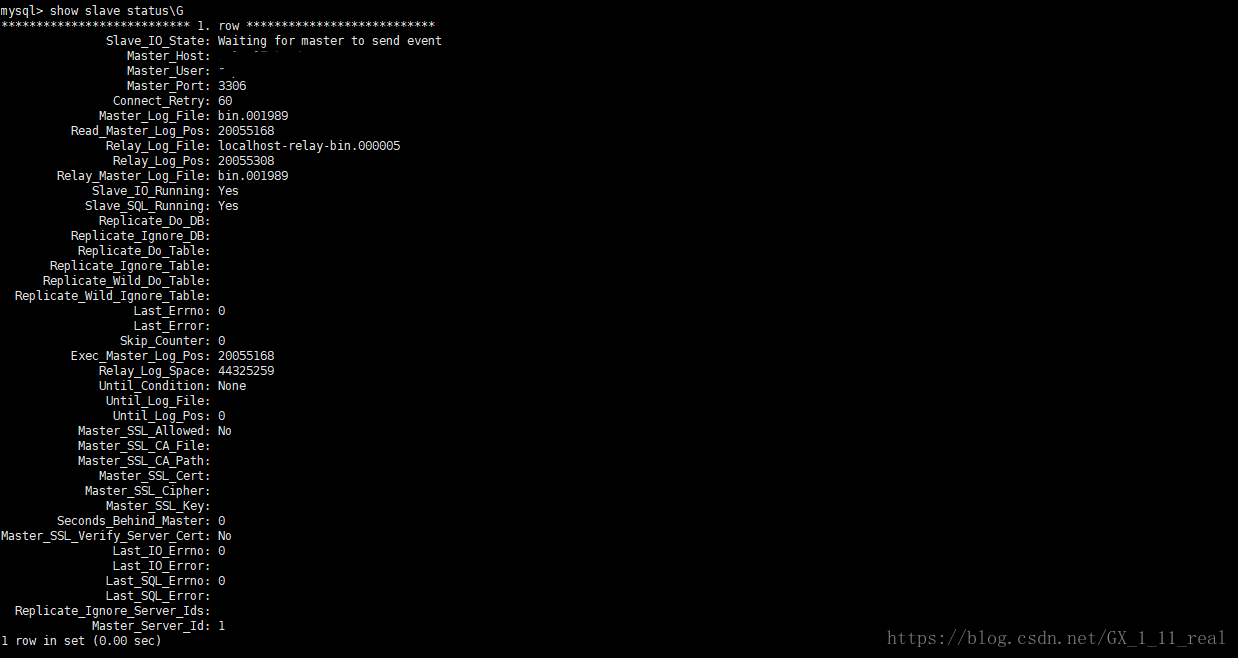
show slave status\G ;
重点关注下列两个的状态[yes/no]:
Slave_IO_Running
Slave_SQL_Running
<3>解决方法一:
忽略错误后,继续同步
(适用于主库与从库数据相差不大;要求数据可以不完全统一,数据要求不严格的情况)
{1}进入从库操作:
mysql -uroot -p‘…’
{2}停止从库同步
stop slave;
{3}跳过1步错误(后面的数字可更改)
set global sql_slave_skip_counter =1;
{4}开启从库
start slave;
{5}查看从库状态
show slave status\G;
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
即为正常
<4>解决方法二
重新做主从,完全同步
(适用于主库从库的数据相差较大;要求数据完全统一的情况 )
{1}先进入主库,进行锁表,此处锁定为只读状态,防止数据写入 (可选,因如有数据库备份,可直接利用备份)
flush tables with read lock;
{2}进行数据备份,把数据备份为.sql的文件(可选,因如有数据库备份,可直接利用备份)
mysqldump -uroot -p‘密码’ –all-databases > mysql.back.sql
{3}进入主库,进行解锁(可选,因如有数据库备份,可直接利用备份)
unlock tables;
{4}把mysql的备份文件传输到从库服务器上(位置任意,但要能找到)
scp -r /root/mysql.bask.sql root@node2:/tmp/
{5}进入从库,停止从库的状态
stop slave;
清除slave上的同步位置,删除所有旧的同步日志,使用新的日志重新开始.(使用前先停止slave服务)
reset slave;(可选)
{6}在从库中导入数据备份
source /tmp/mysql.back.sql ;
或
mysql -uroot -p‘….’ database -f < /tmp/mysql.bask.sql
(-f 为跳过错误的Sql,继续往下执行,可不加)
{7}设置从库同步
change master to master_host = ‘主库的IP’, master_user = ‘设置主从时设定的主库的用户’, master_port=主库的端口, master_password=’主库设定的密码’, master_log_file = ‘mysqld-bin.001989’, master_log_pos=24110520;
注意:
master_log_file与master_log_pos 是主库show master status信息里的| File与Position
{8}重新开启从库同步
start slave;
{9}查看同步状态
mysql> show slave status\G 查看:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes