Python-并发编程(线程)


#进程复习 #队列:管道+锁 #因为pickle实现的,所以可以处理任意数据类型 #进程之间的数据安全--进程安全(所谓进程安全就是多进程抢占资源会不会出现,某个数据被取用多次) #管道(越是底层,处理的速度就越快) #有两端 #需要关闭掉不用的所有端口,才会在recv出报错 #进程不安全(安全与否,主要是指多进程才会出现) #进程池 #什么情况下要用进程池: #高CPU,高运行行的需要用进程池 #进程池个数:CPU个数+1 #Pool池 #apply 同步 #apply_asynv 异步提交 #get 获取返回值 #close #join #map #apply_asynv的简化版 #内部实现了close和join #但是没有get方法,无法接受返回值 #回调函数 appluy_asynv(callback=??) #回调函数是在主进程中执行的 #在子进程执行完任务之后立刻将结果返回给回调函数 #被回调函数作为参数,进行下一步处理 #数据共享Manager:dict,list #进程都在同一台计算机上才能用 #数据在进程之间不安全 #进程之间的数据共享:消息中间件 #memcache #rabbitmg #redis #信号量和池 #在同一时刻只会有n个进程在执行某段代码 #相似: #不同 #信号量是有多少任务开多少进程,信号量仍然给操作系统带来了很多负担 #池中进程的数量是固定的,只是分别借用池中的进程来执行任务而已

进程只做资源的分配,而代码的执行是由线程执行的
为什么有了多进程,有出息了多线程?
1,因为有些需求不需要内存隔离
2,多进程的开启资源分配,调度比较耽误时间
进程是计算机中资源分配的最小单位
多线程的特点:并发的,轻量级,数据不隔离,这也造成了数据不安全问题
多进程的特点:并发的,数据完全隔离,操作比较笨重
Python线程模块的选择--使用threading模块
Python提供了几个用于多线程编程的模块,包括thread、threading和Queue等。thread和threading模块允许程序员创建和管理线程。thread模块提供了基本的线程和锁的支持,threading提供了更高级别、功能更强的线程管理的功能。Queue模块允许用户创建一个可以用于多个线程之间共享数据的队列数据结构。
避免使用thread模块,因为更高级别的threading模块更为先进,对线程的支持更为完善,而且使用thread模块里的属性有可能会与threading出现冲突;其次低级别的thread模块的同步原语很少(实际上只有一个),而threading模块则有很多;再者,thread模块中当主线程结束时,所有的线程都会被强制结束掉,没有警告也不会有正常的清除工作,至少threading模块能确保重要的子线程退出后进程才退出。
thread模块不支持守护线程,当主线程退出时,所有的子线程不论它们是否还在工作,都会被强行退出。而threading模块支持守护线程,守护线程一般是一个等待客户请求的服务器,如果没有客户提出请求它就在那等着,如果设定一个线程为守护线程,就表示这个线程是不重要的,在进程退出的时候,不用等待这个线程退出。
threading模块
multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性
验证线程是能够并发的
#验证在一个进程里,并行执行 import os import time from threading import Thread #线程 Thread def func(): for i in range(10): print('in thread:',i,os.getpid()) time.sleep(0.5) if __name__ == '__main__': t = Thread(target=func) t.start() time.sleep(1) print('in main',os.getpid()) time.sleep(1) print('in main 2',os.getpid())
验证线程是轻量级的
import time from multiprocessing import Process from threading import Thread def func(n): print(n**n) if __name__ == '__main__': start = time.time() p_lst = [] for i in range(50): p =Process(target=func,args=(i,)) p.start() p_lst.append(p) for p in p_lst:p.join() print('*******',time.time()-start) start = time.time() t_lst = [] for i in range(50): t = Thread(target=func, args=(i,)) t.start() t_lst.append(t) for t in t_lst: t.join() print('*******',time.time() - start)
数据隔离验证
from threading import Thread n =100 def func(): global n n -=1 t = Thread(target=func) t.start() t.join() print(n)
主线程和子线程的关系:
主线程:程序开始运行的时候,就产生了一个主线程来运行这个程序
子线程:是由主线程开启的其他线程
各线程之间的工作:异步的,数据共享的
import time from threading import Thread,currentThread def func(): time.sleep(1) print('in 子线程',currentThread()) Thread(target=func).start()#开启一个子线程 print('主线程',currentThread()) #主线程的结束就意味着主进程的结束,主线程会等待子线程结束才结束 #currentThread()是个函数,打印出主线程,还是子线程,以及编号
使用线程通过socket实现TCP的多人聊天
server:
#线程实现socket的TCP协议 import socket from threading import Thread def talk(conn): while True: conn.send(b'hello') msg = conn.recv(1024) print(msg) conn.close() if __name__ == '__main__': sk = socket.socket() sk.bind(('127.0.0.1',8090)) sk.listen() while True: conn,addr = sk.accept() t = Thread(target=talk,args=(conn,)) t.start() sk.close() #线程的个数也是和CPU的个数相关的 #线程的个数:CPU的个数*5
client:
import socket sk = socket.socket() sk.connect(('127.0.0.1',8090)) while True: print(sk.recv(1024)) msg = input('>>>').encode('utf-8') sk.send(msg) sk.close()
复习:线程的开启
#GIL锁:CPython解释器中有一把锁,锁得是线程 from threading import Thread,currentThread def t_func(): global n n -= 1 print(currentThread()) if __name__ == '__main__': n = 100 t_lst =[] for i in range(100): t = Thread(target=t_func) t.start() t_lst.append(t) print(t.ident,t.name,t.is_alive()) for t in t_lst:t.join() print(n) #线程不能在外界的干扰下结束,而是等待程序执行完毕才结束 #主线程要等待子线程的结束而结束
守护线程
与进程的守护进程对比
import time from multiprocessing import Process def func1(): time.sleep(3) print('in func1') def func2(): while True: time.sleep(0.5) print('in func2') if __name__ == '__main__': Process(target=func1).start() t= Process(target=func2) # t.setDaemon(True)#守护进程,这个是传参,属于方法,而进程里的守护进程是属性,赋值 t.daemon=True t.start() print('主线程')
守护线程
import time from threading import Thread def func1(): time.sleep(3) print('in func1') def func2(): while True: time.sleep(0.5) print('in func2') Thread(target=func1).start() t= Thread(target=func2) t.setDaemon(True)#守护线程,这个是传参,属于方法,而进程里的守护进程是属性,赋值 t.start() #守护线程会等待主线程执行完毕才结束,主线程会等待所有子线程结束而结束 print('主线程')
线程的锁,不一定安全,这个是同步锁,数据量大,还是要加锁
import threading balance=0 def change_it(n): global balance balance = balance +n balance = balance-n def run_thread(n): for i in range(150000): change_it(n) lock = threading.Lock() #线程锁:保证同一时刻只有一个线程可以方案CPU #但是由于时间片轮转,偶尔还是会出现胡乱问题 t1 = threading.Thread(target=run_thread,args=(5,)) t2 = threading.Thread(target=run_thread,args=(8 ,)) t1.start() t2.start() t1.join() t2.join() print(balance)
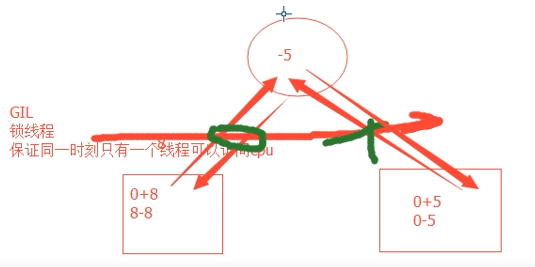
解决办法:加上锁
import threading balance=0 def change_it(n): global balance balance = balance +n balance = balance-n def run_thread(n,lock): for i in range(150000): with lock: change_it(n) lock = threading.Lock() #线程锁:保证同一时刻只有一个线程可以方案CPU #但是由于时间片轮转,偶尔还是会出现胡乱问题 t1 = threading.Thread(target=run_thread,args=(5,)) t2 = threading.Thread(target=run_thread,args=(8 ,)) t1.start() t2.start() t1.join() t2.join() print(balance)
锁
from threading import Lock #互斥锁:缺点,容易被阻塞 lock = Lock() lock.acquire() lock.acquire()#锁被两次acquire就会阻塞 print(123) lock.release() #----------------------------------------- from threading import RLock #递进锁 lock=RLock() lock.acquire() lock.acquire()#不会被阻塞 lock.acquire() print(123) lock.release()

死锁
#死锁 #科学家吃面问题 # import time from threading import Thread ,Lock def eat1(name,fork_lock,noodle_lock): fork_lock.acquire() print('%s拿到叉子了'%name) noodle_lock.acquire() print('%s拿到面条了'%name) print('%s吃面'%name) noodle_lock.release() fork_lock.release() def eat2(name,fork_lock,noodle_lock): noodle_lock.acquire() print('%s拿到面条了'%name) time.sleep(1) fork_lock.acquire() print('%s拿到叉子了'%name) print('%s吃面'%name) fork_lock.release() noodle_lock.release() fork_lock = Lock() noodle_lock = Lock() Thread(target=eat1,args=('aaa',fork_lock,noodle_lock)).start() Thread(target=eat2,args=('111',fork_lock,noodle_lock)).start() Thread(target=eat1,args=('bbb',fork_lock,noodle_lock)).start() Thread(target=eat2,args=('222',fork_lock,noodle_lock)).start()
解决死锁问题
import time from threading import Thread ,RLock def eat1(name,fork_lock,noodle_lock): fork_lock.acquire() print('%s拿到叉子了'%name) noodle_lock.acquire() print('%s拿到面条了'%name) print('%s吃面'%name) noodle_lock.release() fork_lock.release() def eat2(name,fork_lock,noodle_lock): noodle_lock.acquire() print('%s拿到面条了'%name) time.sleep(1) fork_lock.acquire() print('%s拿到叉子了'%name) print('%s吃面'%name) fork_lock.release() noodle_lock.release() noodle_lock = fork_lock=RLock() #创建一把锁 # print(noodle_lock,fork_lock)#地址完全一样,是一把锁,一把锁后,就不会发生死锁现象了 Thread(target=eat1,args=('aaa',fork_lock,noodle_lock)).start() Thread(target=eat2,args=('111',fork_lock,noodle_lock)).start() Thread(target=eat1,args=('bbb',fork_lock,noodle_lock)).start() Thread(target=eat2,args=('222',fork_lock,noodle_lock)).start()
总结:
#互斥锁和递归锁得区别 #互斥锁在同一个线程中连续acquire一次以上会死锁 #递归所在同一个线程中可以连续的acquire多次而不发生死锁 #普遍:递归锁可以代替互斥锁来解决死锁现象 #实际上:递归锁的解决死锁实际上是牺牲了时间和空间的 #死锁从本质上来讲是一种逻辑错误 #递归锁没有从根本上解决死锁问题
信号量
#信号量 #同进程的一样 #Semaphore管理一个内置的计数器 #每当调用acquire()时内置计数器-1 #调用release()时内置计数器+1 # 计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()
事件
#同进程的一样 #线程的一个关键特性是每个线程都是独立运行且状态不可预测,如果程序中的其他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常刺手。 #为了解决这些问题,我们需要使用threading库中的Event对象,对象包括一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在初始情况下,Event对象中的信号标志被设置为假。 #如果有线程等待一个Event对象,而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真,一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。 #如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件,继续执行
event.isSet():返回event的状态值 event.wait():如果event.isSet()==False将阻塞线程 event.set():设置event的状态为True,所有阻塞池的线程激活进入就绪状态,等待操作系统调度 event.clear():恢复event的状态值为False。
例子
import threading import time,random from threading import Thread,Event def conn_mysql(): count=1 while not event.is_set(): if count>3: raise TimeoutError('链接超时') print('<%s>第%s次尝试链接'%(threading.current_thread().getName(),count)) event.wait(1.5)#如果标志为True,那么就说明链接成功 count+=1 print('<%s>链接成功'%threading.current_thread().getName()) def check_mysql():#检查网络是否畅通 print('\033[45m[%s]正在检查mysql\033[0m'%threading.current_thread().getName()) time.sleep(random.randint(1,4))#来模拟检查的过程 event.set()#把事件标志设置为True if __name__ == '__main__': event=Event() conn1=Thread(target=conn_mysql) conn2 = Thread(target=conn_mysql) check = Thread(target=check_mysql) conn1.start() conn2.start() check.start()
定时器
from threading import Timer,currentThread def func(): print('in func',currentThread()) t = Timer(3,func)#定时 t.start() #定时3秒之后才开启线程执行代码 print(currentThread())
条件
import threading def run(n): con.acquire()#条件的acquire,涉及到阻塞这个机制。acquire是在 #wait或者notify之前必须执行的方法 #有acquire就要有release con.wait()#等待。con控制wait,正常情况下是阻塞 # notify是一个信号量,创建钥匙,配钥匙的 print('run the thread : %s'%n) con.release() if __name__ == '__main__': con = threading.Condition()#实例化一个条件 for i in range(10): #10个线程 t = threading.Thread(target=run,args=(i,)) t.start() while True: inp = input('>>>') if inp == 'q': break con.acquire() con.notify(int(inp))# con.release() print('*****')
线程队列
#线程队列 # queue队列:使用import queue,用法与进程Queue一样 # queue.Queue(maxsize=0)#先进先出 #维护了一个数据的秩序:先进先出 #还维护了数据在多个线程之间的安全问题 import queue q = queue.Queue() q.put(2) q.put(3) q.put(4) q.put(5) print(q.get()) print(q.get()) #queue.LifoQueue(maxsize=0)#后进先出--栈--算法 import queue q = queue.LifoQueue() q.put(2) q.put(3) q.put(4) q.put(5) print(q.get()) print(q.get()) #queue.PriorityQueue(maxsize=0)#存储数据时可以设置优先级的队列--淘宝下单退货 import queue q = queue.PriorityQueue() #put进入一个元祖,元组的第一个元素是优先级(通常是数字,也可以是非数字之间 #的比较 ),数字越小优先级越高 q.put((20,'a')) q.put((10,'a')) q.put((30,'a'))#如果,前面相同,那么就根据asicc码来判断优先级 q.put((30,'b')) print(q.get()) print(q.get()) print(q.get()) print(q.get())

concurrent.futures模块
#threading/multiprocessing #threading先有 #threading模块中没有池的概念 #concurrent.futures:提供了和池有关的所有工具 # from concurrent.futures import ThreadPoolExecutor # from concurrent.futures import ProcessPoolExecutor
#1 介绍 concurrent.futures模块提供了高度封装的异步调用接口 ThreadPoolExecutor:线程池,提供异步调用 ProcessPoolExecutor: 进程池,提供异步调用 Both implement the same interface, which is defined by the abstract Executor class. #2 基本方法 #submit(fn, *args, **kwargs) 异步提交任务 #map(func, *iterables, timeout=None, chunksize=1) 取代for循环submit的操作 #shutdown(wait=True) 相当于进程池的pool.close()+pool.join()操作 wait=True,等待池内所有任务执行完毕回收完资源后才继续 wait=False,立即返回,并不会等待池内的任务执行完毕 但不管wait参数为何值,整个程序都会等到所有任务执行完毕 submit和map必须在shutdown之前 #result(timeout=None) 取得结果 #add_done_callback(fn) 回调函数# done()判断某一个线程是否完成# cancle()取消某个任务
ThreadPoolExecutor例子
import time import random from concurrent.futures import ThreadPoolExecutor def func(n): print(n) time.sleep(random.randint(0,5)) tp = ThreadPoolExecutor(10)#池里面放10个线程 for i in range(20): tp.submit(func,i) tp.shutdown() print('主线程')#希望主线程这句话在所有子线程执行完后,在打印,解决办法:加上tp.shutdown()
tp.map实现for循环开启多进程的方法
import time import random from concurrent.futures import ThreadPoolExecutor def func(n): print(n) time.sleep(random.randint(0,5)) tp = ThreadPoolExecutor(10)#池里面放10个线程 # for i in range(20): # tp.submit(func,i) # tp.shutdown() tp.map(func,range(20))#map实现上面for循环的功能,但是没有tp.shutdown()的功能 tp.shutdown() print('主线程')#希望主线程这句话在所有子线程执行完后,在打印,解决办法:加上tp.shutdown()
map功能对比
import time,random from multiprocessing import Pool def func(n): print(n) time.sleep(random.randint(0,5)) if __name__ == '__main__': mp=Pool(10) mp.map(func,range(20))#自带有join功能,能够进行阻塞等待子进程执行完之后,打印下面‘主进程’ print('主进程')
例子
import os import requests #扩展模块 #urllib Python语言用来访问网页的 from threading import currentThread from concurrent.futures import ThreadPoolExecutor def get_page(url): print('<线程%s> get %s' %(currentThread ,url)) respone=requests.get(url) return {'url':url,'text':respone.text} urls = [ 'https://www.baidu.com', 'https://www.python.org', 'https://www.openstack.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] tp = ThreadPoolExecutor(3)#线程池 # t = tp.submit(get_page,urls[0]) # print(t.result()) t_lst =[] for url in urls: t = tp.submit(get_page,url) t_lst.append(t) # print(t.result())#result使程序同步 for t in t_lst: t.result() print(t.result())
回调函数
import requests #扩展模块 #urllib Python语言用来访问网页的 from threading import currentThread from concurrent.futures import ThreadPoolExecutor def get_page(url): print('<线程%s> get %s' %(currentThread ,url)) respone=requests.get(url) return {'url':url,'text':respone.text} def callback(ret):#回调函数-子线程或者子进程执行 # print(ret) print(ret.result()) urls = [ 'https://www.baidu.com', 'https://www.python.org', 'https://www.openstack.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] tp = ThreadPoolExecutor(3)#线程池 t_lst =[] for url in urls: t = tp.submit(get_page,url).add_done_callback(callback)
验证
import requests #扩展模块 #urllib Python语言用来访问网页的 from threading import currentThread from concurrent.futures import ThreadPoolExecutor def get_page(url): print('<线程%s> get %s' %(currentThread() ,url)) respone=requests.get(url) return {'url':url,'text':respone.text} def callback(ret):#回调函数-在concurrent.futures里面,回调函数子线程或者子进程执行 #在multiprocessing里面,回调函数是由主进程执行的 # print(ret.result()) print('____',currentThread()) urls = [ 'https://www.baidu.com', 'https://www.python.org', 'https://www.openstack.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] print('主线程',currentThread()) tp = ThreadPoolExecutor(3)#线程池 t_lst =[] for url in urls: t = tp.submit(get_page,url).add_done_callback(callback)
总结:
#multiprocess.Pool #apply_async异步提交任务 #得join,close之后才能维护主进程与池之间的同步 #map自带join,close效果 #获取执行结果,get #回调函数,指定callback参数,由主进程执行 #concurrent.futures.ThreadPoolExecutor #或者concurrent.futures.ProcessPoolExecutor #submit 异步提交任务 #shutdown 同步 #map是不自带shutdown #获取执行结果 result #回调函数 直接调用add_done_callback方法,由子线程或者子进程执行 #concurrent.futures的优势: #用concurrent.futures,可以轻松的在进程和线程之间切换 #并发程序,线程池,进程池都要用,使用concurrent.futures只需要导入一个模块 #concurrent.futures是一个新的模块,统一了线程池和进程池的使用方式,对一些操作 #进行了更合理的规划 #线程池一般的线程个数:CPU个数*5