
Python之深浅copy与字符编码
一、深浅copy
1. 首先看赋值运算
l1 = [1,2,3,['barry','alex']] l2 = l1 l1[0] = 111 print(l1) # [111, 2, 3, ['barry', 'alex']] print(l2) # [111, 2, 3, ['barry', 'alex']] l1[3][0] = 'wusir' print(l1) # [111, 2, 3, ['wusir', 'alex']] print(l2) # [111, 2, 3, ['wusir', 'alex']]
PS: 所以对于赋值运算来说他们指向的是同一个内存地址,所以他们是完全相同的。
2. 浅拷贝copy
l1 = [1,2,3] l2 = l1.copy() l1.append(666) print(l1,l2)#[1, 2, 3, 666] [1, 2, 3] print(id(l1),id(l2))#1733495294216 1733495317192 l1 = [1,2,3,[22,33]] l2 = l1.copy() l1[-1].append(666) print(l1,l2)#[1, 2, 3, [22, 33, 666]] [1, 2, 3, [22, 33, 666]] print(id(l1[-1]),id(l2[-1]))#1770640312584 1770640312584
PS: 对于浅copy来说,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
3. 深copy
import copy l1 = [1,2,3,[22,33]] l2 = copy.deepcopy(l1) l1[-1].append(666) print(l1,l2)#[1, 2, 3, [22, 33, 666]] [1, 2, 3, [22, 33]] print(id(l1[-1]),id(l2[-1]))#2011177553288 2011177553352
PS: 对于深copy来说,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变。
二、字符编码
1.字符编码的历史与分类
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
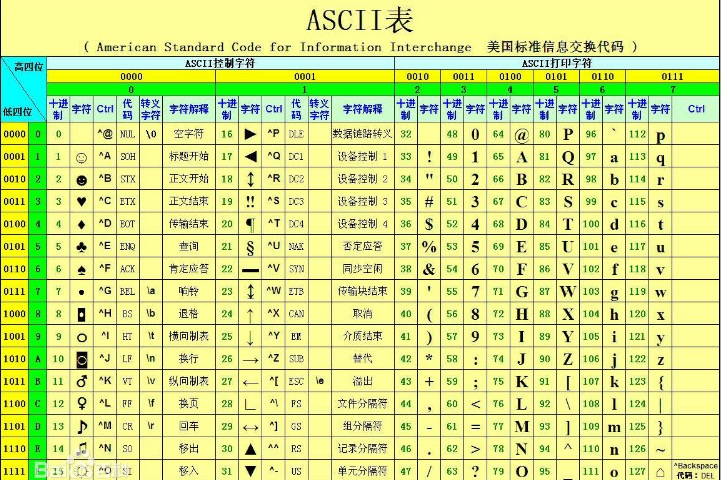
当然我们编程语言都用英文没问题,ASCII够用,但是在处理数据时,不同的国家有不同的语言,小日本会在自己的程序中加入日文,中国人会加入中文。而要表示中文,就要一个字节用>8位2进制代表,位数越多,代表的变化就多,这样,就可以尽可能多的表达出不通的汉字,所以中国人规定了自己的标准gb2312编码,规定了包含中文在内的字符->数字的对应关系。
ascii用1个字节(8位二进制)代表一个字符
unicode常用2个字节(16位二进制)代表一个字符,生僻字需要用4个字节
例:
字母x,用ascii表示是十进制的120,二进制0111 1000
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
字母x,用unicode表示二进制0000 0000 0111 1000,所以unicode兼容ascii,也兼容万国,是世界的标准
这时候乱码问题消失了,所有的文档我们都使用但是新问题出现了,如果我们的文档通篇都是英文,你用unicode会比ascii耗费多一倍的空间,在存储和传输上十分的低效
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 |
11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
基于目前的现状,内存中的编码固定就是unicode,我们唯一可变的就是硬盘的上对应的字符编码。
此时你可能会觉得,那如果我们以后开发软时统一都用unicode编码,那么不就都统一了吗,关于统一这一点你的思路是没错的,但我们不可会使用unicode编码来编写程序的文件,因为在通篇都是英文的情况下,耗费的空间几乎会多出一倍,这样在软件读入内存或写入磁盘时,都会徒增IO次数,从而降低程序的执行效率。因而我们以后在编写程序的文件时应该统一使用一个更为精准的字符编码utf-8(用1Bytes存英文,3Bytes存中文),再次强调,内存中的编码固定使用unicode。
1、在存入磁盘时,需要将unicode转成一种更为精准的格式,utf-8:全称Unicode Transformation Format,将数据量控制到最精简
2、在读入内存时,需要将utf-8转成unicode
所以我们需要明确:内存中用unicode是为了兼容万国软件,即便是硬盘中有各国编码编写的软件,unicode也有相对应的映射关系,但在现在的开发中,程序员普遍使用utf-8编码了,估计在将来的某一天等所有老的软件都淘汰掉了情况下,就可以变成:内存utf-8<->硬盘utf-8的形式了。
2. 编码:
ascii:字母,数字,特殊字符。
万国码:unicode :
A: 0000 0010 0000 0010 两个字节,表示一个字符。
中: 0000 0010 0000 0010 两个字节,表示一个字符。
升级:
A: 0000 0010 0000 0010 0000 0010 0000 0010 四个字节,表示一个字符。
中: 0000 0010 0000 0010 0000 0010 0000 0010 四个字节,表示一个字符。
占空间,浪费资源。
utf-8:最少用一个字节,表示一个字符.
A: 0000 0010
欧洲:0000 00100000 0010
中文:0000 00100000 00100000 0010
gbk国标。
A: 0000 0010
中: 0000 0010 0000 0010
python3x:
1,不同编码之间的二进制是不能互相识别的。
2,python3x str内部编码方式(内存)为unicode,但是,对于文件的存储,和传输不能用unicode
bytes类型:内部编码方式(内存)为非unicode
#对于英文
str:
s = 'laonanhai' 表现形式
#内部编码方式 unicode
bytes:
s1 = b'laonanhai' 表现形式
#内部编码方式 非unicode (utf-8,gbk,gb2312....)
#对于中文:
str:
s = '中国'
print(s,type(s))
bytes:
s1 = b'\xe4\xb8\xad\xe5\x9b\xbd'
print(s1,type(s1))
转化:
s = 'laonanhai' s2 = s.encode('utf-8') #str -->bytes encode 编码 s3 = s.encode('gbk') print(s2,s3)#b'laonanhai' b'laonanhai' s = '中国' s2 = s.encode('utf-8') #str -->bytes encode 编码 # s3 = s.encode('gbk') # print(s2)#b'\xe4\xb8\xad\xe5\x9b\xbd' # print(s3)#b'\xd6\xd0\xb9\xfa' ss = s2.decode('utf-8') # bytes ---> str decode 解码 print(ss)#中国
!!!总结非常重要的两点!!!
#1、保证不乱吗的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码 #2、在内存中写的所有字符,一视同仁,都是unicode编码,比如我们打开编辑器,输入一个“你”,我们并不能说“你”就是一个汉字,
此时它仅仅只是一个符号,该符号可能很多国家都在使用,根据我们使用的输入法不同这个字的样式可能也不太一样。
只有在我们往硬盘保存或者基于网络传输时,才能确定”你“到底是一个汉字,还是一个日本字,这就是unicode转换成其他编码格式的过程了
unicode----->encode-------->utf-8
utf-8-------->decode---------->unicode

