pandas
一、创建数据
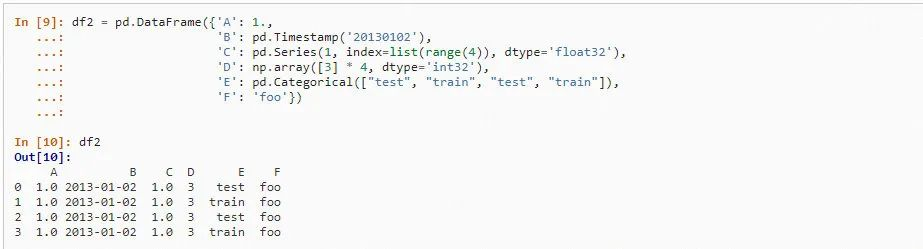
Python 里面有三种很重要的数据结构,其中一种是 Numpy 里的 Array,应用在了很多的科学计算场景里。另外两种则是 Pandas 的 Series 和 DataFrame,其中 Series 是一维的结构,DataFrame 则是二维的结构。DataFrame 可以来自于列表、字典,也可以来自于我们从各种接口里面读到的数据/文本。只要我们对其成功地 DataFrame 化,便可进入下一步的处理。

二、预览数据
1.通过 head 和 tail 观察头部和尾部的数据;

2.通过 index 和 columns 观察索引和列名;

3.通过 describe 进行简单的统计观察;

4.通过 sort 进行排序观察。

三、数据筛选
数据筛选,其实也是一种广义上的数据观察,只是相对于上面所说的预览数据而言,数据筛选不再局限于数据的外部轮廓,而是深入到了其内部的肌理。
1.通过列名和行数直接筛选;

2.基于行与列标签的 loc 筛选;

3.基于行与列位置的 iloc 筛选;

4.基于布尔索引的筛选。

四、缺失值处理
在不同的场景下,缺失值可以填 0,填众数,或者平均值。
1、缺失值清除

2、缺失值填充

五、函数操作
1、lambda匿名函数

6、数据拼接
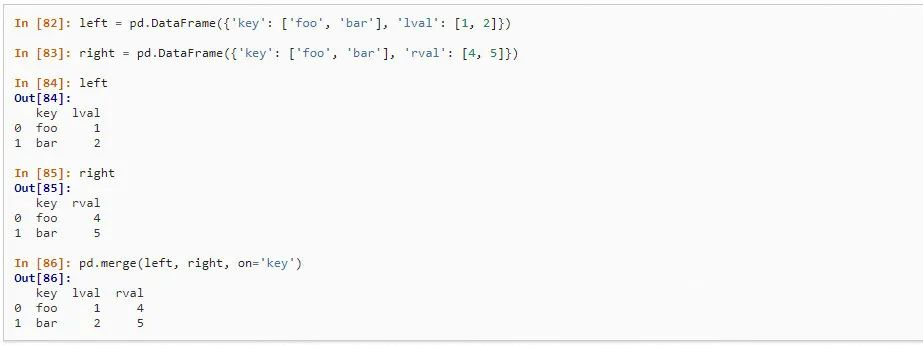
1、merge和sql里的join较为相似,
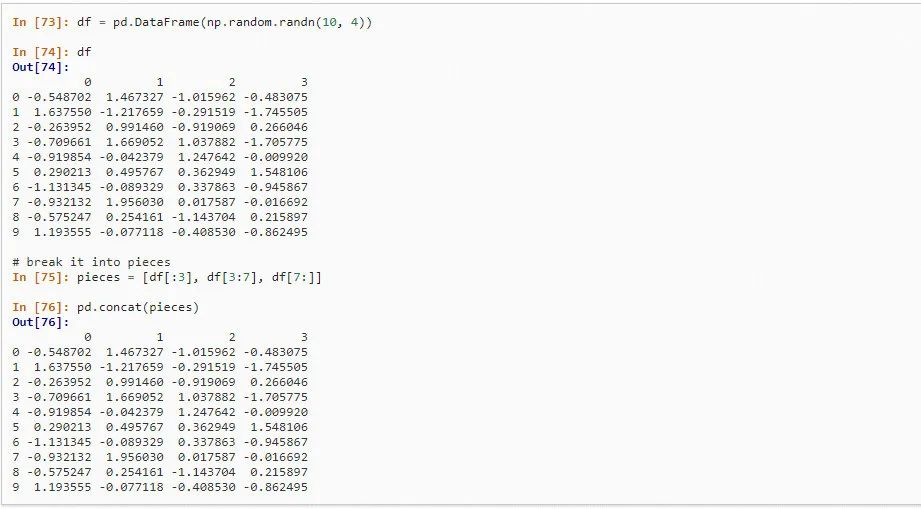
2、多表拼接的concat
七、数据聚合与重塑
1、groupby

2、stack

八、数据读取与写入
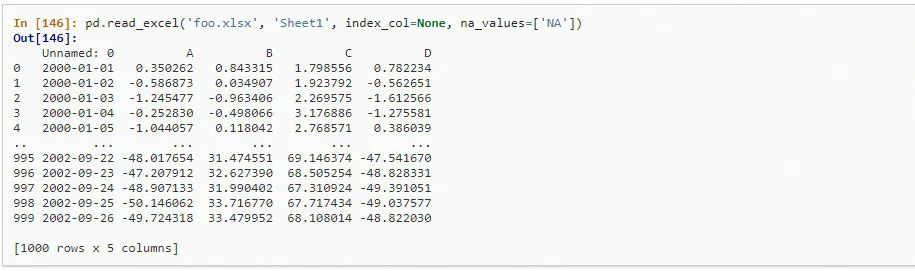
1、pandas读取CSV数据

2、pandas读取并处理excel数据