
05_Greenplum定义数据库对象_管理模式_创建表管理表
一、创建于管理模式
DB内组织对象的一种逻辑结构
1、创建模式

注:schema用来管理对象的一个内容
代码:
psql -d testdw
\dn(查看schema)
create schema sc01;
create schema sc02 authorization dylan;(不将schema赋个gpadmin,将他赋个其他用户,但是testdw没有权限,需要输入赋权限的命令)
grant all on database testdw to dylan;(给了权限后,需要在执行上一个命令)
\dn
2、模式搜索路径

(1)设置搜索路径

(2)查看当前模式

(3)使用DROP SCHEMA命令(空模式)

注:空模式下如果有对象,不能删除;
代码:
show search_path;(查看搜索路径)
alter database testdw set search_path to sc01, public, pg_catalog;(修改搜索路劲)
show search_path;
\d
create table tb01(id int );(不指定schema,但是会使用是sc01,如果没有修改搜索路径会是public)
\d
修改role的
alter role dylan set search_path to sc01, public, pg_catalog;
select * from pg_roles;(通过查看数据字典,搜索顺序)
注:如果查看两个表名相同的表,会通过修改后的顺序查看;
3、系统模式

二、创建与管理表
1、创建表
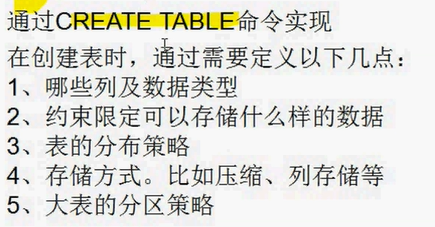

2、设置表的列约束


3、选择表的分布策略

注:DK为分布键
4、声明分布键

代码:
\d(查看表格)
\d tb02(可以查看表格的分布)
5、选择表的存储模式 (存储性能的优化)
(1)创建堆存储和追加存储

代码:
\d(其中Stor age这个字段可以查看是使用的什么存储模式:heap是堆存储)
创建追加表
create table tb06(a int , b text ) with (appendonly = true);
\d
insert into tb06 values(1, 'abc');
select * from tb06;
commit;
delete from tb06;(不支持删除)
(2)行存储和列存储


注:列存储不能使用update和delete;行存储不能压缩;
代码:
create table tb07(a int b text, c int, d int, e int, f int, g int) with (appendonly = true,orientation = column) distributend by (a);
\d
\timeing(记时功能)
(3)压缩存储

(4)创建压缩表
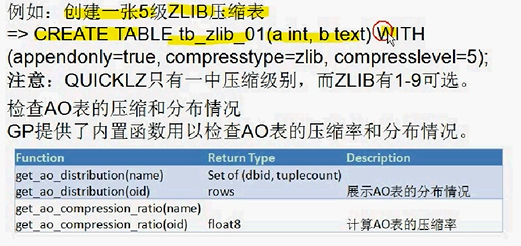
代码:
create table tb_zlip_01(a int ,b text ) with (appendonly=true, compresstype=zlib, compresslevel=5);
\d
insert into tb_zlip_01 values(1, 'abc');
insert into tb_zlip_01 values(2, 'def');
insert into tb_zlip_01 select * from tb_zlip_01;
重复多次
insert into tb_zlip_01 select * from tb_zlip_01;
select get_ao_distribution('tb_zlip_01');(展示ao表的分布情况)
select get_ao_compression_tation('tb_zlip_01');
select oid from pg_class where relname='tb_zlip_01';(查看oid)

注:如果压缩重复较少或者没有重复的,可能会导致压缩后更大;因为它存储的是其中一个重复元素,并不是所有重复的都存储。
(6)使用列级压缩



注: 子分区优先于分区,列级比表级优先 ;子分区>分区>列级>表级
代码:
例1:
create table tb_t1(c1 int encoding(compresstype=zlib),
c2 text encoding(compresstype=quicklz, blocksize=65536),
c3 text))
with (appendonly=true, orleatation=column);
例2:

例3:
create table tb_t3(c1 int encoding(compresstype=zlib ),
c2 text encoding (compresstype=quicklz, blocksize=65536),
c3 text encoding (compresstype=rle_type)
)
with (appendonly=true, orientation=column)
partition by range(c3) (start ('2022-01-01'::date)
end ('2022-12-31'::date),
column c3 encoding (compresstype=zlib)
);(::可以实现类型转换)
例4:

6、变更表

(1)修改分布策略

(2)重分布表数据

注:重分布的原因:生产环境中的一些操作有可能让数据倾斜等,所以需要重分布;
代码:
select gp_segment_id, count(1) from tb_zlip_02 group by 1;(可以查看segment分别存储了多少数据)
(3)修改表的存储模式

注:用like会很方便,虽然不是标准的写法
代码:
create table tb_zlib_02 (like tb_zlib_01)
with (appendonly=true, compresstype=quicklz, compresslevel=1, orientation=column );(创建新表)
(4)添加压缩列

注:default 0 意思是默认值为0
(5)继承压缩设置

注:在增加压缩列会继承子分区
(6)删除表



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App