

HDFS3.x集群配置
1、准备工作
-
准备3太centos机器并设置主机名
修改命令:vim /etc/hostname
一台作为Namenode,命名为master,
两台作为dataNode,命名为node-1, node-2 -
设置hosts
修改命令:vim /etc/hosts192.168.0.6 master 192.168.0.17 node-1 192.168.0.19 node-2 -
3台机器都创建hadoop用户并设置密码
useradd hadoop passwd hadoop -
免密登陆自身(3台)
su – hadoop ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys #测试 ssh localhost(首次需输入yes) -
设置hadoop账户的ssh信任关系(仅master)
#在master机器上操作 ssh-copy-id -i .ssh/id_rsa.pub hadoop@192.168.0.6 ssh-copy-id -i .ssh/id_rsa.pub hadoop@192.168.0.17 ssh-copy-id -i .ssh/id_rsa.pub hadoop@192.168.0.19 #测试一下,都能成功登录就行 ssh hadoop@master ssh hadoop@node-1 ssh hadoop@node-2 -
配置jdk
配置方法 -
非生产环境建议关闭防火墙:
firewall常用操作方法
2、安装
-
下载hadoop
下载地址 -
在3太机器上创建相同的目录路径, name目录只存放在master上,且权限为755,否则会导致后面的格式化失败
mkdir -p /hadoop/install mkdir -p /hadoop/name mkdir -p /hadoop/data1 mkdir -p /hadoop/data2 mkdir -p /hadoop/tmp- 解压安装包到/hadoop/install下
tar xzvf hadoop-3.1.2.tar.gz -C /hadoop/install/ -
修改属主为hadoop
chown -R hadoop.hadoop /hadoop
3、配置(3台机器都需配置)
- 修改hadoop-env.sh文件,指定jdk安装路径。
vim /hadoop/install/hadoop-3.1.2/etc/hadoop/hadoop-env.shexport JAVA_HOME=/usr/local/jdk1.8.0_181 export HDFS_NAMENODE_USER="hadoop" export HDFS_DATANODE_USER="hadoop" export HDFS_SECONDARYNAMENODE_USER="hadoop" export YARN_RESOURCEMANAGER_USER="hadoop" export YARN_NODEMANAGER_USER="hadoop" - 修改core-site.xml文件,指定hadoop默认的文件系统为HDFS,并同时指定namenode为master:
vim /hadoop/install/hadoop-3.1.2/etc/hadoop/core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration> - 修改hdfs-site.xml文件:
vim /hadoop/install/hadoop-3.1.2/etc/hadoop/hdfs-site.xml<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/hadoop/name/</value> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> </property> <property> <name>dfs.namenode.handler.count</name> <value>100</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/hadoop/data1/,/hadoop/data2/</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> - 编辑workers文件,批量启动hdfs时指定需要启动的datanode:
vim /hadoop/install/hadoop-3.1.2/etc/hadoop/workersnode-1 node-2 - 修改yarn-site.xml文件:
vim /hadoop/install/hadoop-3.1.2/etc/hadoop/yarn-site.xml<configuration> <!-- Site specific YARN configuration properties --> <!-- Configurations for ResourceManager and NodeManager: --> <!-- Configurations for ResourceManager: --> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> <!-- Configurations for NodeManager: --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- Configurations for History Server (Needs to be moved elsewhere): --> </configuration> - 修改mapred-site.xml文件:
vim /hadoop/install/hadoop-3.1.2/etc/hadoop/mapred-site.xml<configuration> <!-- Configurations for MapReduce Applications: --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
3、启动
- 初始化HDFS [只有首次部署才可使用]【谨慎操作,只在msater上操作】
在master机器上,初始化namenode的元数据目录,进入hadoop的bin目录下,执行命令:
有以下提示代表成功./hadoop namenode -format
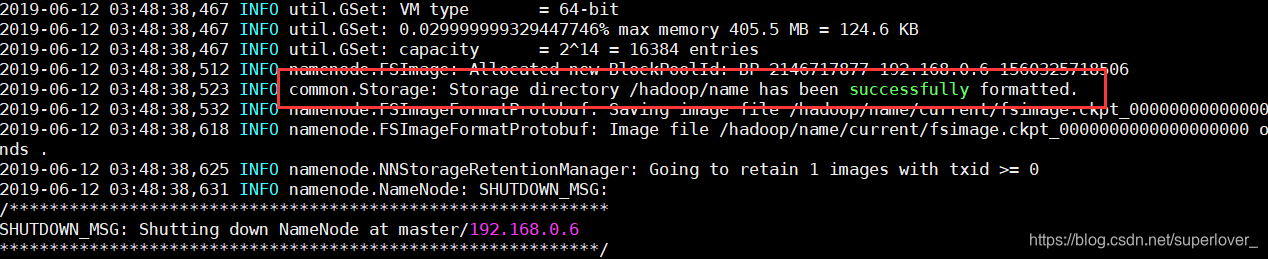
- 开启 【只在master上操作】
进入sbin目录下,执行以下命令:./start-dfs.sh ./start-yarn.sh - 查看装在 【3台机器分别执行
jps命令】
master:
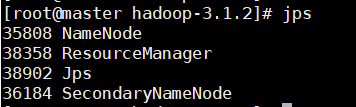
node-1
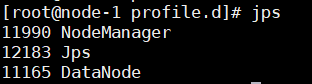
node-2
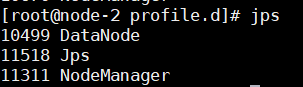
- web界面访问:
http://192.168.0.6:9870/
http://192.168.0.6:8088/
划重点:hadoop3.X的webUI已经改到端口 localhost:9870上面,而不是原来的50070,网上大多数的教程都是2.X的,当然不行!!
Java项目使用方法:Spring Boot项目中使用HDFS3.x

