
2018冬令营模拟测试赛(十五)
2018冬令营模拟测试赛(十五)
[Problem A]区间第k小
试题描述


输入
见“试题描述”
输出
见“试题描述”
输入示例
见“试题描述”
输出示例
见“试题描述”
数据规模及约定
见“试题描述”
题解
考虑从左往右依次加入每个数。假设所有询问的右端点固定,对于相同权值的数字我们可以将最后 \(w\) 个的贡献设置为 \(1\),然后从后往前第 \(w+1\) 个设置为 \(-w\),剩余的设置为 \(0\),那么这样询问的时候直接查询一个区间的贡献和即可。然而现在右端点并不固定,所以我们需要搞一个可持久化线段树来维护随着右端点向右推进,每个版本线段树长什么样。此题由于还要询问第 \(k\) 小,在内层套一颗权值线段树是必要的;询问区间 \([l, r]\) 时就在版本 \(r\) 的可持久化线段树上,找到对应区间的所有权值线段树的根,然后带着这 \(\log n\) 个节点二分就好了。
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <cctype>
#include <algorithm>
#include <vector>
using namespace std;
#define rep(i, s, t) for(int i = (s), mi = (t); i <= mi; i++)
#define dwn(i, s, t) for(int i = (s), mi = (t); i >= mi; i--)
const int BufferSize = 1 << 16;
char buffer[BufferSize], *Head, *Tail;
inline char Getchar() {
if(Head == Tail) {
int l = fread(buffer, 1, BufferSize, stdin);
Tail = (Head = buffer) + l;
}
return *Head++;
}
inline int read() {
int x = 0, f = 1; char c = Getchar();
while(!isdigit(c)){ if(c == '-') f = -1; c = Getchar(); }
while(isdigit(c)){ x = x * 10 + c - '0'; c = Getchar(); }
return x * f;
}
#define maxn 100010
#define maxnode 3200010
#define maxNode 53000010
vector <int> pos[maxn];
int n, w, q, type, Rt[maxn];
int tot, lc[maxnode], rc[maxnode], rt[maxnode];
int ToT, Lc[maxNode], Rc[maxNode], Sumv[maxNode];
inline void Update(int& y, int x, int l, int r, int p, int v) {
Sumv[y = ++ToT] = Sumv[x] + v;
// if(ToT % 10000 == 0) printf("ToT: %d\n", ToT);
if(l == r) return ;
int mid = l + r >> 1; Lc[y] = Lc[x]; Rc[y] = Rc[x];
if(p <= mid) Update(Lc[y], Lc[x], l, mid, p, v);
else Update(Rc[y], Rc[x], mid + 1, r, p, v);
return ;
}
inline void update(int& y, int x, int l, int r, int X, int Y, int v) {
Update(rt[y = ++tot], rt[x], 0, n - 1, Y, v);
// if(tot % 10000 == 0) printf("tot: %d\n", tot);
if(l == r) return ;
int mid = l + r >> 1; lc[y] = lc[x]; rc[y] = rc[x];
if(X <= mid) update(lc[y], lc[x], l, mid, X, Y, v);
else update(rc[y], rc[x], mid + 1, r, X, Y, v);
return ;
}
int Node[maxn], cn;
inline void query(int o, int l, int r, int ql, int qr) {
if(!o) return ;
if(ql <= l && r <= qr){ Node[++cn] = rt[o]; return ; }
int mid = l + r >> 1;
if(ql <= mid) query(lc[o], l, mid, ql, qr);
if(qr > mid) query(rc[o], mid + 1, r, ql, qr);
return ;
}
int num[50], cntn;
inline void putint(int x) {
if(!x) return (void)puts("0");
cntn = 0;
while(x) num[++cntn] = x % 10, x /= 10;
dwn(i, cntn, 1) putchar(num[i] + '0'); putchar('\n');
return ;
}
int main() {
n = read(); w = read(); q = read(); type = read();
rep(i, 1, n) {
Rt[i] = Rt[i-1];
int A = read();
pos[A].push_back(i);
if(pos[A].size() > w) update(Rt[i], Rt[i], 0, n, pos[A][pos[A].size()-1-w], A, -w - 1);
if(pos[A].size() > w + 1) update(Rt[i], Rt[i], 0, n, pos[A][pos[A].size()-2-w], A, w);
update(Rt[i], Rt[i], 0, n, i, A, 1);
}
int lst = 0;
while(q--) {
int ql = read() ^ lst * type, qr = read() ^ lst * type, K = read() ^ lst * type;
cn = 0; query(Rt[qr], 0, n, ql, qr);
int l = 0, r = n - 1;
while(l < r) {
int mid = l + r >> 1, ls = 0, tc = 0;
rep(i, 1, cn) ls += Lc[Node[i]] ? Sumv[Lc[Node[i]]] : 0;
if(K <= ls) {
r = mid;
rep(i, 1, cn) if(Lc[Node[i]]) Node[++tc] = Lc[Node[i]];
cn = tc;
}
else {
K -= ls;
l = mid + 1;
rep(i, 1, cn) if(Rc[Node[i]]) Node[++tc] = Rc[Node[i]];
cn = tc;
}
}
int nows = 0;
rep(i, 1, cn) nows += Node[i] ? Sumv[Node[i]] : 0;
putint(lst = K - nows > 0 ? n : l);
}
return 0;
}
[Problem B]求和
试题描述


输入
见“试题描述”
输出
见“试题描述”
输入示例
见“试题描述”
输出示例
见“试题描述”
数据规模及约定
见“试题描述”
题解
看到 \(\mathrm{gcd}(i, j)\),先反演一波。
这个时候先不急着将 \([\mathrm{gcd}(i, j) = 1]\) 化成莫比乌斯函数(否则最后时间复杂度会升高),考虑用 \(\varphi(t)\) 做。对于 \(i\),\(\le i\) 的且和 \(i\) 互质的数的个数就是 \(\varphi(i)\),而除 \(1\) 外所有数都不和自己互质,所以 \(n\) 中互质数对的个数是 \(2 (\sum_{i=1}^{\lfloor n \rfloor} { \varphi(i) }) - 1\)。
于是上面的可以继续变形下去
如果我们用 \(g(\lfloor \frac{n}{x} \rfloor)\) 去给后面的 \(2(\sum_{i=1}^{\lfloor \frac{n}{x} \rfloor} \varphi(i)) - 1\) 换元,要求什么就会看起来更清晰一些。
那么现在解决方法就一步步出来了:暴力枚举 \(d\),分块求 \(ans\),我们需要求出 \(g(n)\) 的值和 \(f_d(n)\) 的前缀和;对于 \(g(n)\),关键就是要求 \(\varphi(n)\) 的前缀和,这个杜教筛一下就好了。所以现在还差 \(f_d(n)\) 的前缀和。
令 \(\lambda(n) = f_{+\infty}(n)\),即若给 \(n\) 分解质因数,\(n = \prod_{i=1}^k p_i^{q_i}\),则 \(\lambda(n) = \prod_{i=1}^k {(-1)}^{q_i}\)。那么可以发现 \(\lambda(n)\) 是完全积性函数。
而对于 \(f_d(n)\),考虑用 \(\lambda(t)\) 表示它,我们发现可以容斥,即 \(\sum_{x=1}^n f_d(x) = \sum_{t=1}^n { \mu(t) \sum_{i=1}^{\lfloor \frac{n}{t^{d+1}} \rfloor} \lambda(t^{d+1} i) }\),接下来换元一下就好了。
然后我们需要求 \(\lambda(n)\) 的前缀和,首先对于前 \(n^{\frac{2}{3}}\) 的部分由于它的完全积性我们可以线性筛直接求出,更大的部分我们还是可以用杜教筛,令 \(\Lambda(n) = \sum_{i=1}^n \lambda(n)\),考虑下面这个式子
为什么呢?假如 \(j\) 有一个奇数次方的质因子(即 \(a^b | i\),\(b\) 是奇数),那么在所有 \(i\) 的约数中,\(a\) 从 \(0\) 次到 \(b\) 次,奇、偶数次方的数量是相同的,也即 \(\sum_{j|\frac{i}{a^b}} \lambda(j)\) 和 \(-\sum_{j|\frac{i}{a^b}} \lambda(j)\) 的个数是一样的,这样加起来就抵消了。那么如果所有的质因子都是偶数次幂(此时 \(b\) 是偶数),可以发现 \(\sum_{j|\frac{i}{a^b}} \lambda(j)\) 会比 \(-\sum_{j|\frac{i}{a^b}} \lambda(j)\) 多一个,然后归纳证明一下结果就恰好是 \(1\)。
所以二分一下求 \([1, n]\) 中完全平方数个数然后杜教筛就好了。
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <cctype>
#include <algorithm>
#include <cmath>
#include <map>
#include <cassert>
using namespace std;
#define rep(i, s, t) for(LL i = (s), mi = (t); i <= mi; i++)
#define repi(i, s, t) for(int i = (s), mi = (t); i <= mi; i++)
#define dwn(i, s, t) for(LL i = (s), mi = (t); i >= mi; i--)
#define LL long long
LL read() {
LL x = 0, f = 1; char c = getchar();
while(!isdigit(c)){ if(c == '-') f = -1; c = getchar(); }
while(isdigit(c)){ x = x * 10 + c - '0'; c = getchar(); }
return x * f;
}
#define maxn 6000010
#define maxk 8
#define uint unsigned int
const int MOD = 1 << 30;
bool vis[maxn];
int prime[maxn], cp, tot[maxn][maxk], cntp[maxn];
uint mu[maxn], lmd[maxn], sl[maxn], phi[maxn], sf[maxn], fsum[maxn];
void init(int n) {
mu[1] = lmd[1] = sl[1] = phi[1] = sf[1] = 1;
repi(i, 2, n) {
if(!vis[i]) prime[++cp] = i, mu[i] = lmd[i] = -1, phi[i] = i - 1;
for(int j = 1; j <= cp && i * prime[j] <= n; j++) {
vis[i*prime[j]] = 1;
lmd[i*prime[j]] = -lmd[i];
if(i % prime[j] == 0) {
phi[i*prime[j]] = phi[i] * prime[j];
mu[i*prime[j]] = 0;
break;
}
mu[i*prime[j]] = -mu[i];
phi[i*prime[j]] = phi[i] * (prime[j] - 1);
}
sl[i] = sl[i-1] + lmd[i];
sf[i] = sf[i-1] + phi[i];
}
return ;
}
const int HMOD = 1000037, maxtot = 5000;
struct Hash {
int ToT, head[HMOD], nxt[maxtot];
LL key[maxtot];
uint val[maxtot];
int Find(LL x) {
int u = x % HMOD;
for(int e = head[u]; e; e = nxt[e]) if(key[e] == x) return e;
return 0;
}
void Insert(LL x, uint v) {
int u = x % HMOD;
nxt[++ToT] = head[u]; key[ToT] = x; val[ToT] = v; head[u] = ToT;
return ;
}
} Ps, Gs, Ls;
uint Psum(LL n) {
if(n < maxn) return sf[n];
int e = Ps.Find(n);
if(e) return Ps.val[e];
uint ans = n * (n + 1) >> 1;
for(LL i = 2; i <= n; ) {
LL r = min(n / (n / i), n);
ans = ans - (uint)(r - i + 1) * Psum(n / i);
i = r + 1;
}
Ps.Insert(n, ans);
return ans;
}
int m;
LL squ[maxn];
uint Lsum(LL n) {
if(n < maxn) return sl[n];
int e = Ls.Find(n);
if(e) return Ls.val[e];
uint ans = upper_bound(squ + 1, squ + m + 1, n) - squ - 1;
// printf("%d %u\n", m, ans);
for(LL i = 2; i <= n; ) {
LL r = min(n / (n / i), n);
ans = ans - (uint)(r - i + 1) * Lsum(n / i);
i = r + 1;
}
Ls.Insert(n, ans);
return ans;
}
const int fkmax = 660000;
void initfk() {
int n = fkmax;
repi(i, 2, n) {
if(!vis[i]) tot[i][0] = cntp[i] = 1;
for(int j = 1; j <= cp && i * prime[j] <= n; j++) {
if(i % prime[j] == 0) {
cntp[i*prime[j]] = cntp[i];
rep(t, 0, cntp[i] - 1) tot[i*prime[j]][t] = tot[i][t];
tot[i*prime[j]][0]++;
break;
}
cntp[i*prime[j]] = cntp[i] + 1;
tot[i*prime[j]][0] = 1; rep(t, 0, cntp[i] - 1) tot[i*prime[j]][t+1] = tot[i][t];
}
}
return ;
}
void calc(int k) {
rep(i, 1, fkmax) {
int tmp = 1;
rep(j, 0, cntp[i] - 1)
if(tot[i][j] > k){ tmp = 0; break; }
else tmp *= (tot[i][j] & 1) ? -1 : 1;
fsum[i] = fsum[i-1] + tmp;
}
return ;
}
LL _t[maxn];
uint _lmd[maxn];
uint Fsum(uint d, LL n) {
if(n <= fkmax) return fsum[n];
uint ans = 0;
for(int t = 1; ; t++) {
LL B = _t[t];
if(n < B) break;
ans += mu[t] * _lmd[t] * Lsum(n / B);
}
return ans;
}
int main() {
init(maxn - 1);
LL n = read(); int K = read();
if(n == 9670278500ll) return puts("1029311104"), 0;
if(n == 9485173637ll) return puts("196173778"), 0;
// 怒而特判,卡常什么的去shi吧!
m = 0;
for(LL i = 1; i * i <= n; i++) squ[++m] = i * i;
initfk();
uint ans = 0;
repi(i, 1, m + 1) _t[i] = i, _lmd[i] = lmd[i];
rep(d, 1, K) {
int i = 1;
for(i = 1; i <= m + 1; i++) {
if(_t[i] <= n) _t[i] *= i; else break;
_lmd[i] *= lmd[i];
}
calc(d);
if(_t[2] > n) {
uint tmp = 0;
for(LL t = 1; t <= n; ) {
LL r = min(n / (n / t), n);
tmp += (Lsum(r) - Lsum(t - 1)) * ((Psum(n / t) << 1) - 1);
t = r + 1;
}
ans += tmp * (K - d + 1);
break;
}
for(LL t = 1; t <= n; ) {
LL r = min(n / (n / t), n);
ans += (Fsum(d, r) - Fsum(d, t - 1)) * ((Psum(n / t) << 1) - 1);
t = r + 1;
}
}
printf("%u\n", ans & MOD - 1);
return 0;
}
[Problem C]树
试题描述


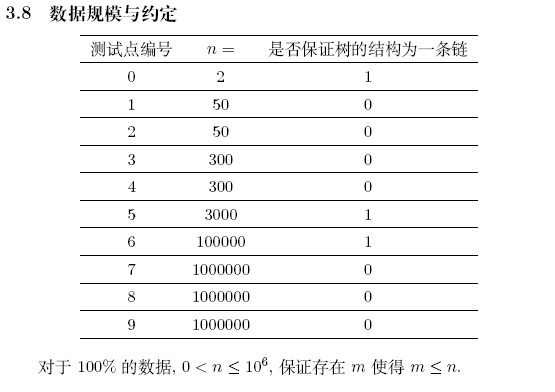
输入
见“试题描述”
输出
见“试题描述”
输入示例
见“试题描述”
输出示例
见“试题描述”
数据规模及约定
见“试题描述”
题解
首先有个性质 \(s \Rightarrow u\) 和 \(u \Rightarrow t\) 这两条路径可以合并成一条 \(s \Rightarrow t\) 的路径。
然后我们发现叶子节点只可能用它和父亲的连边来调整,于是这样的边的流量和方向就确定了,然后我们删掉叶子,往上依次确定每条边的流量和每个节点的入度、出度。
最后看哪些节点出度多、哪些入度多,贪心匹配即可。贪心匹配可行的原因是它还有另一个性质:\(a \Rightarrow b\) 和 \(c \Rightarrow d\) 两条路径等价于 \(a \Rightarrow d\) 和 \(c \Rightarrow b\),即只要起点、终点不变,可以任意组合,这个性质手画两种情况就发现很容易证明了。
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <cctype>
#include <algorithm>
using namespace std;
#define rep(i, s, t) for(int i = (s), mi = (t); i <= mi; i++)
#define dwn(i, s, t) for(int i = (s), mi = (t); i >= mi; i--)
int read() {
int x = 0, f = 1; char c = getchar();
while(!isdigit(c)){ if(c == '-') f = -1; c = getchar(); }
while(isdigit(c)){ x = x * 10 + c - '0'; c = getchar(); }
return x * f;
}
#define maxn 1000010
#define maxm 2000010
int n, m, head[maxn], nxt[maxm], to[maxm], val[maxn], up[maxn], ind[maxn];
void AddEdge(int a, int b) {
to[++m] = b; nxt[m] = head[a]; head[a] = m;
swap(a, b);
to[++m] = b; nxt[m] = head[a]; head[a] = m;
return ;
}
void dp(int u, int fa) {
int myind = 0, myval = 0;
for(int e = head[u]; e; e = nxt[e]) if(to[e] != fa) {
dp(to[e], u);
myval += up[to[e]] * (to[e] < u ? 1 : -1);
myind += up[to[e]];
}
up[u] = (val[u] - myval) * (u < fa ? 1 : -1);
myind -= up[u];
ind[u] = myind;
return ;
}
int st[maxn], en[maxn], cs, ce;
int main() {
n = read();
rep(i, 1, n) val[i] = read();
rep(i, 1, n - 1) {
int a = read(), b = read();
AddEdge(a, b);
}
dp(1, 0);
int ans = 0;
rep(i, 1, n)
if(ind[i] > 0) ans += ind[i], en[++ce] = i;
else if(ind[i] < 0) st[++cs] = i;
printf("%d\n", ans);
int i = 1, j = 1;
while(i <= cs) {
printf("%d %d\n", st[i], en[j]);
ind[st[i]]++; ind[en[j]]--;
if(!ind[st[i]]) i++;
if(!ind[en[j]]) j++;
}
return 0;
}

