
2018冬令营模拟测试赛(十三)
2018冬令营模拟测试赛(十三)
[Problem A]大佬的难题
试题描述


输入
见“试题描述”
输出
见“试题描述”
输入示例
见“试题描述”
输出示例
见“试题描述”
数据规模及约定
见“试题描述”
题解
三维偏序,暴力就是第一维排序第二维分治第三维数据结构,这样做是 \(O(n\mathrm{log}^2n)\) 的,会 T 飞。
我们搞一些事情可以让它降到一个 \(\mathrm{log}\) 的。
令 \(K_{x, y} = [a_x < a_y] + [b_x < b_y] + [c_x < c_y], S_{x,y} = \mathrm{max}\{ K_{x, y}, K_{y, x} \}\),然后令 \(A = \sum_{x, y \in [1, n], x < y} { [S_{x, y} = 3] }, B = \sum_{x, y \in [1, n], x < y} { [S_{x, y} = 2] }\),那么显然我们要求的是 \(A\) 的值。
首先我们知道有这样一个等量关系:
\begin{equation}
A + B = C_n^2
\end{equation}
因为对于一对 \((x, y)\),\(a_x, b_x, c_x\) 对应比 \(a_y, b_y, c_y\) 小的个数可以有 \(0, 1, 2, 3\) 这 \(4\) 种情况,而我们的 \(S_{x, y} = \mathrm{max}\{ K_{x, y}, K_{y, x} \}\),就会有 \(1, 2\) 合并(注意合并之后对于两个数对 \((x_0, y_0)\) 和 \((y_0, x_0)\) 只会算一次)、\(0, 3\) 合并,而 \(1, 2\) 合并后的集合大小就是 \(B\),\(0, 3\) 合并后的集合大小就是 \(A\),显然 \(A + B\) 就是全集的大小,即 \(n\) 中取 \(2\) 个数的方案数。
然后我们会知(?)道有另外一个等量关系,令 \(P_{d, e} = \sum_{x, y \in [1, n]} { [d_x < d_y][e_x < e_y] }\):
\begin{equation}
3A + B = P_{a, b} + P_{a, c} + P_{b, c}
\end{equation}
这个你要问我怎么想到,我无可奉告……
至于为什么相等还是很好考虑的。\(P_{a, b}\) 中统计的点对中,假设 \((x_1, y_1)\) 是被统计到的点对之一,那么就有 \([a_{x_1} < a_{y_1}] = [b_{x_1} < b_{y_1}] = 1\),但是 \([c_{x_1} < c_{y_1}]\) 到底是 \(1\) 还是 \(0\),不一定,这两种都被统计进去了;那么当 \([c_{x_1} < c_{y_1}] = 0\) 时,那么显然 \((x_1, y_1)\) 会被统计到 \(B\) 中(注意这里是排列,没有相等的数字);对于 \([c_{x_1} < c_{y_1}] = 1\) 的情况,此时 \((x_1, y_1)\) 肯定是符合 \(A\) 的条件的,而且在 \(P_{a, c}\) 和 \(P_{b, c}\) 它又都分别会被统计一次,所以 \(A\) 总共会被算 \(3\) 次。
那么做一下 \((2) - (1)\) 就发现 \(B\) 被消了,从而得出 \(A\)。
上面的过程只需要求二维偏序,于是时间复杂度变成了 \(O(n\mathrm{log}n)\)
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <cctype>
#include <algorithm>
using namespace std;
#define rep(i, s, t) for(int i = (s); i <= (t); i++)
#define dwn(i, s, t) for(int i = (s); i >= (t); i--)
int read() {
int x = 0, f = 1; char c = getchar();
while(!isdigit(c)){ if(c == '-') f = -1; c = getchar(); }
while(isdigit(c)){ x = x * 10 + c - '0'; c = getchar(); }
return x * f;
}
#define maxn 2000010
#define LL long long
#define pii pair <int, int>
#define x first
#define y second
#define mp(x, y) make_pair(x, y)
int n, A[maxn], B[maxn], C[maxn];
int tot[maxn];
void upd(int x) {
for(; x <= n; x += x & -x) tot[x]++;
return ;
}
int qry(int x) {
int res = 0;
for(; x; x -= x & -x) res += tot[x];
return res;
}
pii ps[maxn];
LL solve(int *a, int *b) {
rep(i, 1, n) ps[i] = mp(a[i], b[i]);
sort(ps + 1, ps + n + 1);
memset(tot, 0, sizeof(tot));
LL ans = 0;
rep(i, 1, n) ans += qry(ps[i].y), upd(ps[i].y);
return ans;
}
LL seed;
LL Rand() {
return seed = ((seed * 19260817) ^ 233333) & ((1 << 24) - 1);
}
void gen(int *a) {
rep(i, 1, n) a[i] = i;
rep(i, 1, n) swap(a[i], a[Rand()%i+1]);
return ;
}
int main() {
n = read();
seed = read(); gen(A);
seed = read(); gen(B);
seed = read(); gen(C);
LL sum1 = (LL)(n - 1) * n >> 1, sum2 = solve(A, B) + solve(B, C) + solve(A, C);
printf("%lld\n", sum2 - sum1 >> 1);
return 0;
}
[Problem B]回文串
试题描述


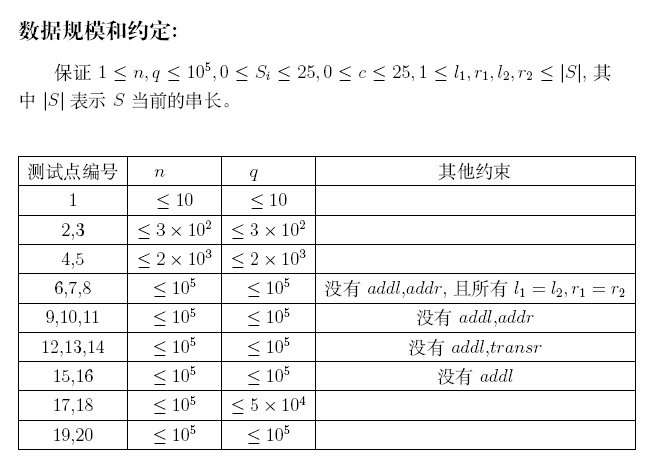
输入
见“试题描述”
输出
见“试题描述”
输入示例
见“试题描述”
输出示例
见“试题描述”
数据规模及约定
见“试题描述”
题解
先来介绍一下什么是回文树(回文自动机和它是一个东西)。知道回文树的请跳过下面五个自然段
维护两种东西:“转移(为了方便以下用 trans 表示)”和“失配边(同样为了方便以下用 fail 表示)”。
一个节点表示的是一个回文子串,如果我研究的这个串中有多个相同的回文子串,那就只开一个节点,如果你要知道什么对于这个串的信息直接在这个节点上记录就好了。一个节点 \(A\) 的转移数量不超过字符集大小,令 \(S\) 表示节点 \(A\) 代表的回文子串,再令 \(trans(A, x)\) 表示 \(S\) 两头都加一个字符 \(x\) 得到的回文串所对应的节点,嗯好这就是转移了;\(fail(A)\) 表示 \(S\) 的最长后缀回文子串所对应的节点,嗯好这就是失配边了。
那么怎么构造这样一个自动机呢?考虑一个个往后添加字符,令 \(lst\) 表示添加最后这个字符 \(c\) 之前的串以最后一个字符结尾的最长回文子串所对应的节点;那么我们从 \(lst\) 沿着 fail 边找,直到某个回文子串的前一位字符等于 \(c\),就跳出。现在令 \(u\) 表示我们找到后跳出的节点,如果 \(trans(u, c)\) 存在,那么本次添加操作完成(为什么呢,因为这个节点存在的话它的 \(fail(trans(u, c))\) 也是存在的,不用再算一遍了);否则建立一个新节点 \(v\) 并让 \(trans(u, c) = v\),考虑计算出 \(fail(v)\),我们继续从 \(u\) 出发沿着 fail 边找,直到某个回文子串的前一位字符等于 \(c\) 时,将 \(u\) 赋值成那个节点,那么 \(fail(v) = trans(u, c)\)(为什么这时 \(trans(u, c)\) 一定存在?因为由于回文的性质,后缀总等于前缀,而前面已经有一个字符 \(c\),故 \(trans(u, c)\) 一定存在),注意如果 \(v\) 这个节点代表的子串就是字符 \(c\) 本身就直接令 \(fail(v) = 空串对应的节点\)。
还有一些细节,我们需要建立两个空串对应的节点,一个长度为 \(0\),一个长度为 \(-1\),这样可以直接做到当前面找不到字符 \(c\) 时它最终能和自己比较从而跳出循环。
于是自动机构造完了!
这道题呢,就先离线把最终的串处理出来(由于没有删除所以可以这么干),然后我们把回文树构造出来,于是 fail 树和自动机的形态都固定下来了。然后我们需要处理出以每个点为左、右端点时最长的回文子串所对应的节点是谁,这个在顺序扫描字符串构造自动机的时候可以顺便处理出以每个点为右端点的信息,以每个点为左端点的信息还需要逆序扫一下这个字符串再在自动机上找一遍。
回文树的节点 \(i\) 上需要再记两个信息:\(Cnt(i)\) 表示这个节点代表的子串在当前字符串中出现的次数,\(Len(i)\) 表示这个几点代表的子串的长度。初始时 \(\forall i, Cnt(i) = 0\)。
于是修改操作变成了 fail 树上一条链整体让 \(Cnt(i)\) 加 \(1\)(进行任何操作前的串我们也可以看成是 \(n\) 次 \(addr\) 操作把初始的 \(Cnt(i)\) 都计算出来);查询操作就是询问一条链上 \(\sum_{i \in chain} { Cnt(i) \cdot Len(i) }\) 的值。我们直接上树链剖分 + 线段树好了(用 LCT 也是可以的)。
注意修改和询问操作时需要保证访问到的节点所代表的子串长度不能超过当前串长,这个我们可以借助树链剖分(跨重链的话直接跳到链顶的父亲上,没跨重链就在重链上二分一下)跳一下,跳到长度小于等于当前串长的节点再进行操作。
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <cctype>
#include <algorithm>
#include <string>
using namespace std;
#define rep(i, s, t) for(int i = (s), mi = (t); i <= mi; i++)
#define dwn(i, s, t) for(int i = (s), mi = (t); i >= mi; i--)
int read() {
int x = 0, f = 1; char c = getchar();
while(!isdigit(c)){ if(c == '-') f = -1; c = getchar(); }
while(isdigit(c)){ x = x * 10 + c - '0'; c = getchar(); }
return x * f;
}
#define maxn 200010
#define maxm 400010
#define maxa 26
#define oo 2147483647
#define LL long long
string str;
char inS[maxn], getS[maxn];
int n, q;
struct Cmd {
int tp, l1, r1, l2, r2;
char c;
Cmd() {}
} cs[maxn];
int ToT, len[maxn], fail[maxn], to[maxn][maxa], lst, rnod[maxn], lnod[maxn];
void extend(int i) {
int u = lst, x = str[i] - '0';
while(i - len[u] - 1 < 0 || str[i] != str[i-len[u]-1]) u = fail[u];
if(to[u][x]) return (void)(lst = rnod[i] = to[u][x]);
len[lst = rnod[i] = to[u][x] = ++ToT] = len[u] + 2;
if(!fail[u]) return (void)(fail[lst] = 2);
u = fail[u]; while(i - len[u] - 1 < 0 || str[i] != str[i-len[u]-1]) u = fail[u];
fail[lst] = to[u][x];
return ;
}
void extend2(int i) {
int u = lst, x = str[i] - '0';
while(i + len[u] + 1 >= n || str[i] != str[i+len[u]+1]) u = fail[u];
lst = lnod[i] = to[u][x];
return ;
}
struct Graph {
int m, head[maxn], nxt[maxm], to[maxm];
Graph(): m(0) { memset(head, 0, sizeof(head)); }
void AddEdge(int a, int b) {
to[++m] = b; nxt[m] = head[a]; head[a] = m;
swap(a, b);
to[++m] = b; nxt[m] = head[a]; head[a] = m;
return ;
}
} G;
int son[maxn], siz[maxn], dfn[maxn], uid[maxn], clo, top[maxn], dep[maxn];
void build(int u) {
siz[u] = 1;
for(int e = G.head[u]; e; e = G.nxt[e]) if(G.to[e] != fail[u]) {
dep[G.to[e]] = dep[u] + 1;
build(G.to[e]);
siz[u] += siz[G.to[e]];
if(!son[u] || siz[son[u]] < siz[G.to[e]]) son[u] = G.to[e];
}
return ;
}
void gett(int u, int tp) {
uid[dfn[u] = ++clo] = u; top[u] = tp;
if(son[u]) gett(son[u], tp);
for(int e = G.head[u]; e; e = G.nxt[e]) if(G.to[e] != fail[u] && G.to[e] != son[u]) gett(G.to[e], G.to[e]);
return ;
}
LL sumv[maxn<<2], sumlen[maxn<<2];
int addv[maxn<<2];
void build(int o, int l, int r) {
if(l == r) sumlen[o] = len[uid[l]];
else {
int mid = l + r >> 1, lc = o << 1, rc = lc | 1;
build(lc, l, mid); build(rc, mid + 1, r);
sumlen[o] = sumlen[lc] + sumlen[rc];
}
return ;
}
void pushdown(int o, int l, int r) {
if(l == r || !addv[o]) return (void)(addv[o] = 0);
int lc = o << 1, rc = lc | 1;
addv[lc] += addv[o]; sumv[lc] += (LL)addv[o] * sumlen[lc];
addv[rc] += addv[o]; sumv[rc] += (LL)addv[o] * sumlen[rc];
addv[o] = 0;
return ;
}
void update(int o, int l, int r, int ql, int qr) {
pushdown(o, l, r);
if(ql <= l && r <= qr) {
addv[o]++;
sumv[o] += sumlen[o];
return ;
}
int mid = l + r >> 1, lc = o << 1, rc = lc | 1;
if(ql <= mid) update(lc, l, mid, ql, qr);
if(qr > mid) update(rc, mid + 1, r, ql, qr);
sumv[o] = sumv[lc] + sumv[rc];
return ;
}
LL query(int o, int l, int r, int ql, int qr) {
pushdown(o, l, r);
if(ql <= l && r <= qr) return sumv[o];
int mid = l + r >> 1, lc = o << 1, rc = lc | 1;
LL ans = 0;
if(ql <= mid) ans += query(lc, l, mid, ql, qr);
if(qr > mid) ans += query(rc, mid + 1, r, ql, qr);
return ans;
}
void modify(int u, int L) {
while(len[top[u]] > L) u = fail[top[u]];
int l = dfn[top[u]], r = dfn[u] + 1;
while(r - l > 1) {
int mid = l + r >> 1;
if(len[uid[mid]] <= L) l = mid; else r = mid;
}
u = uid[l];
// printf("modify %d to root %d %d\n", u, L, len[u]);
while(u) {
update(1, 1, clo, dfn[top[u]], dfn[u]);
u = fail[top[u]];
}
return ;
}
int lca;
LL query(int a, int b) {
int ta = top[a], tb = top[b];
LL ans = 0;
while(ta != tb) {
if(dep[ta] < dep[tb]) swap(ta, tb), swap(a, b);
ans += query(1, 1, clo, dfn[ta], dfn[a]);
a = fail[ta]; ta = top[a];
}
/*printf("here %d %d %lld\n", a, b, ans);
printf("%lld %lld\n", query(1, 1, clo, dfn[4], dfn[4]), query(1, 1, clo, dfn[6], dfn[6])); // */
ans += query(1, 1, clo, min(dfn[a], dfn[b]), max(dfn[a], dfn[b]));
lca = dep[a] < dep[b] ? a : b;
return ans;
}
LL ask(int tp, int l1, int r1, int l2, int r2) { // tp = 1 means left fixed, otherwise means right fixed.
int a = tp == 1 ? lnod[l1] : rnod[r1], b = tp == 1 ? lnod[l2] : rnod[r2], l, r;
while(len[top[a]] > r1 - l1 + 1) a = fail[top[a]];
l = dfn[top[a]]; r = dfn[a] + 1;
while(r - l > 1) {
int mid = l + r >> 1;
if(len[uid[mid]] <= r1 - l1 + 1) l = mid; else r = mid;
}
a = uid[l];
while(len[top[b]] > r2 - l2 + 1) b = fail[top[b]];
l = dfn[top[b]]; r = dfn[b] + 1;
while(r - l > 1) {
int mid = l + r >> 1;
if(len[uid[mid]] <= r2 - l2 + 1) l = mid; else r = mid;
}
b = uid[l];
LL ans = query(a, b);
// printf("query(%d, %d) %lld\n", a, b, ans);
if(tp == 1) {
if(l1 + len[lca] > r1 && l2 + len[lca] > r2 && (l1 != l2 || r1 != r2)) ans -= query(1, 1, clo, dfn[lca], dfn[lca]);
else if(l1 + len[lca] > r1 || l2 + len[lca] > r2) ;
else if(str[l1+len[lca]] == str[l2+len[lca]]) ans -= query(1, 1, clo, dfn[lca], dfn[lca]);
}
else {
if(r1 - len[lca] < l1 && r2 - len[lca] < l2 && (l1 != l2 || r1 != r2)) ans -= query(1, 1, clo, dfn[lca], dfn[lca]);
else if(r1 - len[lca] < l1 || r2 - len[lca] < l2) ;
else if(str[r1-len[lca]] == str[r2-len[lca]]) ans -= query(1, 1, clo, dfn[lca], dfn[lca]);
}
return ans;
}
int main() {
n = read(); q = read();
rep(i, 0, n - 1) inS[i] = read() + '0'; strcpy(getS, inS);
int addl = 0, addr = 0;
rep(i, 1, q) {
scanf("%s", inS);
if(!strcmp(inS, "addl")) {
cs[i].tp = 1; cs[i].c = read() + '0';
addl++;
}
else if(!strcmp(inS, "addr")) {
cs[i].tp = 2; cs[i].c = read() + '0';
}
else if(!strcmp(inS, "transl"))
cs[i].tp = 3, cs[i].l1 = read() - 1, cs[i].r1 = read() - 1, cs[i].l2 = read() - 1, cs[i].r2 = read() - 1;
else cs[i].tp = 4, cs[i].l1 = read() - 1, cs[i].r1 = read() - 1, cs[i].l2 = read() - 1, cs[i].r2 = read() - 1;
}
dwn(i, n - 1, 0) getS[i+addl] = getS[i];
addr = addl + n;
rep(i, 1, q)
if(cs[i].tp == 1) getS[--addl] = cs[i].c;
else if(cs[i].tp == 2) getS[addr++] = cs[i].c;
getS[addr] = 0;
str = (string)getS;
n = str.length();
ToT = lst = 2;
fail[2] = 1; len[2] = 0; len[1] = -1;
rep(i, 0, n - 1) extend(i);
lst = 2;
dwn(i, n - 1, 0) extend2(i);
addl = addr = 0;
dwn(i, q, 1) {
if(cs[i].tp >= 3) cs[i].l1 += addl, cs[i].r1 += addl, cs[i].l2 += addl, cs[i].r2 += addl;
if(cs[i].tp == 1) addl++;
if(cs[i].tp == 2) addr++;
}
/*rep(i, 1, q) printf("%d [%d, %d] [%d, %d]\n", cs[i].tp, cs[i].l1, cs[i].r1, cs[i].l2, cs[i].r2);
rep(i, 1, ToT) {
printf("[%d] fail: %d, len: %d\n", i, fail[i], len[i]);
printf("\ttrans:");
rep(c, 0, maxa - 1) if(to[i][c]) printf(" [%d]%d", c, to[i][c]); putchar('\n');
}
rep(i, 0, n - 1) printf("lrnod[%d]: %d %d\n", i, lnod[i], rnod[i]); // */
rep(i, 1, ToT) if(fail[i]) G.AddEdge(i, fail[i]);
build(1); gett(1, 1);
build(1, 1, clo);
int nowl = addl, nowr = n - addr;
rep(i, nowl, nowr - 1) modify(rnod[i], i - nowl + 1);
rep(i, 1, q) {
if(cs[i].tp == 1) modify(lnod[nowl-1], nowr - nowl + 1), nowl--;
if(cs[i].tp == 2) modify(rnod[nowr], nowr - nowl + 1), nowr++;
if(cs[i].tp == 3) printf("%lld\n", ask(2, cs[i].l1, cs[i].r1, cs[i].l2, cs[i].r2));
if(cs[i].tp == 4) printf("%lld\n", ask(1, cs[i].l1, cs[i].r1, cs[i].l2, cs[i].r2));
}
return 0;
}
[Problem C]营养餐
试题描述

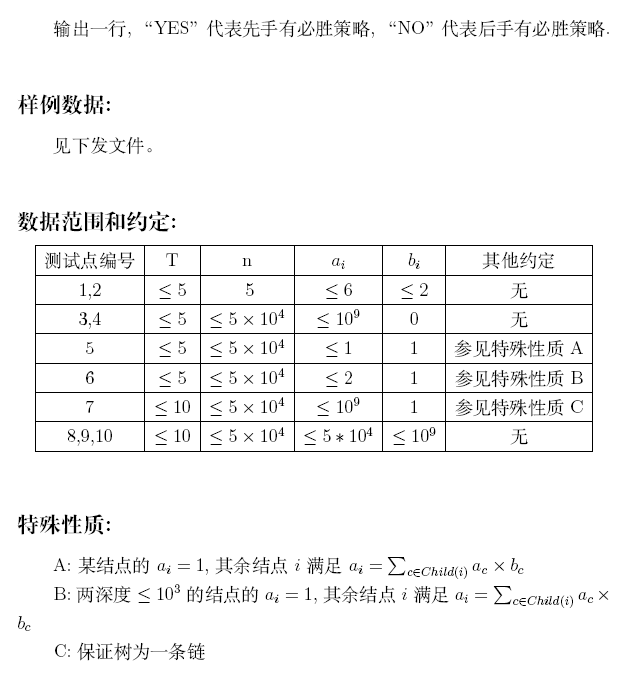
输入
见“试题描述”
输出
见“试题描述”
输入示例
见“试题描述”
输出示例
见“试题描述”
数据规模及约定
见“试题描述”
题解
经典的阶梯博弈模型,估计网上一搜一大把,但我还是讲讲……
对于 \(b_i \ne 0\) 的非根节点,拿走上面的 \(x\) 个水果就要在它的父亲那儿放 \(b_ix\) 个水果。考虑深度为奇数和偶数节点(根节点深度为 \(1\),对于 \(b_j = 0\) 的节点 \(j\) 深度为 \(1\),其余节点深度等与父亲深度 \(+1\)),若拿了偶数节点的水果,不论对应的 \(b_i\) 是多少,它跑到了奇数节点去,那么另一方就可以把奇数节点刚刚多出来的部分再移回偶数节点。所以游戏变成了双方都从奇数节点里面拿水果,拿不了者为输。
那么就变成更经典的 Nim 问题了,把所有奇数节点的 \(a_i - \sum_{c \in Child(i)} a_cb_c\) 异或起来,若不为 \(0\) 则先手必胜,否则先手必败。
好像我之前也有这么一道阶梯博弈的题:戳我!
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <cctype>
#include <algorithm>
using namespace std;
#define rep(i, s, t) for(int i = (s); i <= (t); i++)
#define dwn(i, s, t) for(int i = (s); i >= (t); i--)
int read() {
int x = 0, f = 1; char c = getchar();
while(!isdigit(c)){ if(c == '-') f = -1; c = getchar(); }
while(isdigit(c)){ x = x * 10 + c - '0'; c = getchar(); }
return x * f;
}
#define maxn 50010
#define maxm 100010
int n, m, head[maxn], nxt[maxm], to[maxm], A[maxn], B[maxn];
void AddEdge(int a, int b) {
to[++m] = b; nxt[m] = head[a]; head[a] = m;
swap(a, b);
to[++m] = b; nxt[m] = head[a]; head[a] = m;
return ;
}
int Xor, dep[maxn];
void build(int u, int fa) {
if(!fa || !B[u]) dep[u] = 1;
else dep[u] = dep[fa] + 1;
int rest = A[u];
for(int e = head[u]; e; e = nxt[e]) if(to[e] != fa)
build(to[e], u), rest -= A[to[e]] * B[to[e]];
if(dep[u] & 1) Xor ^= rest;
return ;
}
void work() {
n = read();
rep(i, 1, n) A[i] = read();
rep(i, 1, n) B[i] = read();
m = 0; memset(head, 0, sizeof(head));
rep(i, 1, n - 1) {
int a = read(), b = read();
AddEdge(a, b);
}
Xor = 0;
build(1, 0);
puts(Xor ? "YES" : "NO");
return ;
}
int main() {
int T = read();
while(T--) work();
return 0;
}
