数仓知识
一、 离线数仓
应用:大屏、驾驶舱、商品分析、销售订单分析、BI平台、供应链仓储运单分析、门店经营分析、用户画像。
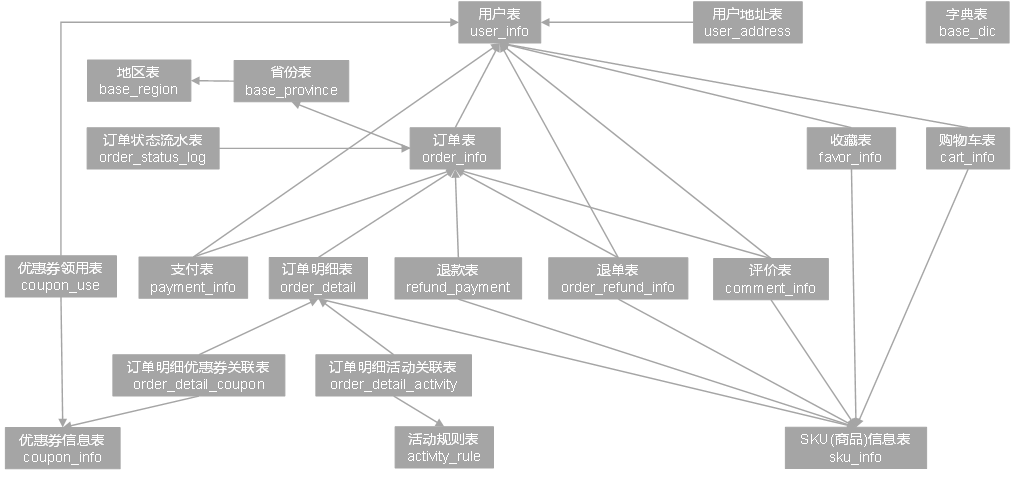
电商业务表
1. 建模理论
ER模型 :实体关系 3NF 数据冗余低 保障数据一致性 面向对象设计 主外键 不适合统计分析 ODS层
维度模型 :星型模型 建表&SQL
- 数据统计:汇总的数据(行为产生的结果)
- 数据分析:维度(角度)
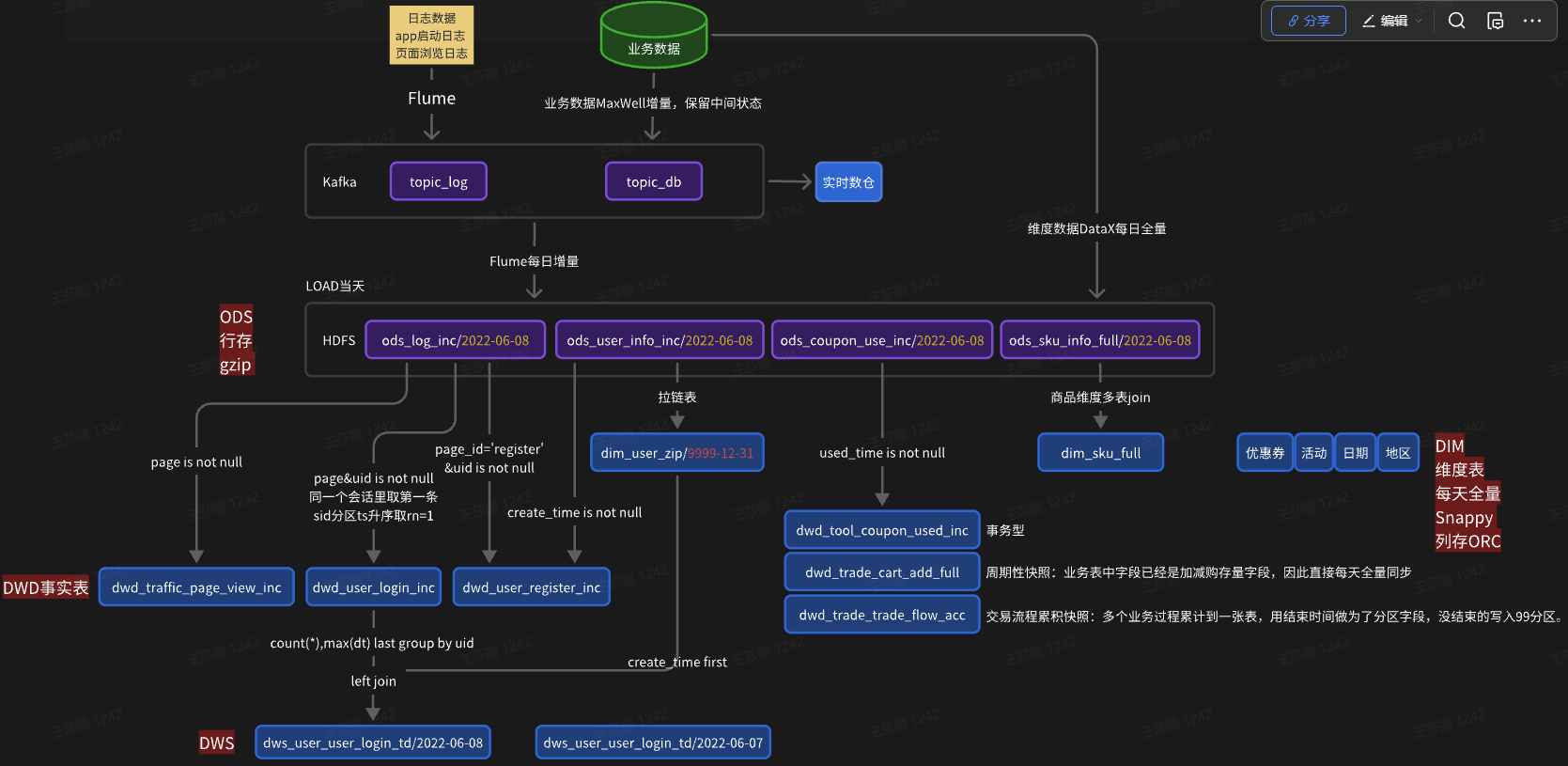
数仓分层
ODS: 列存 gzip(压缩率高)默认支持 每天采集到的数据存入当天分区
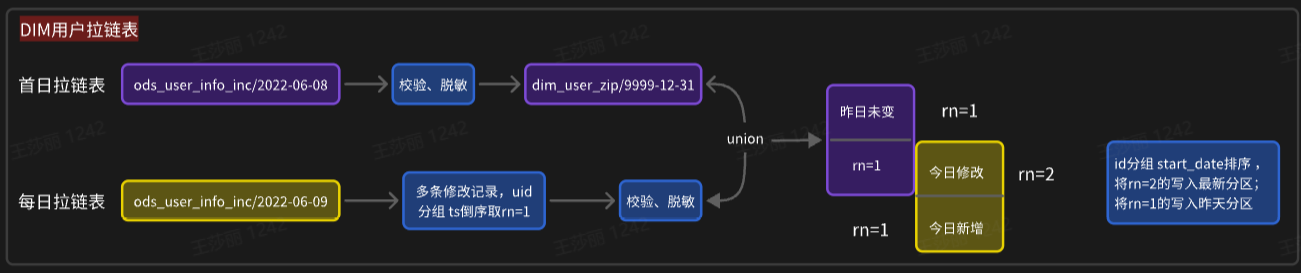
DIM: 全量表:每天一份全量数据存入当天分区;拉链表:结束时间作为分区字段,正常就存9999-12-31中
DWD: 事务型:每天一份增量数据存当天分区; 周期型:每天全量;累积:业务流程中最后的时间作为分区字段,如果没结束就写入9999-12-31分区。
DWS: 预聚合 分区
ADS: 存Mysql 不分区 行式存储 tsv格式 gizp
2. DIM维度表
列存ORC+snapp压缩(效率快) 分区
维度退化:理论一个维度一张表,但是从效率上相关的属性设置为一张表,特别独立字段直接退化到事实表
主维表 相关维表 尽可能多的能分析的字段 编码和文字共存
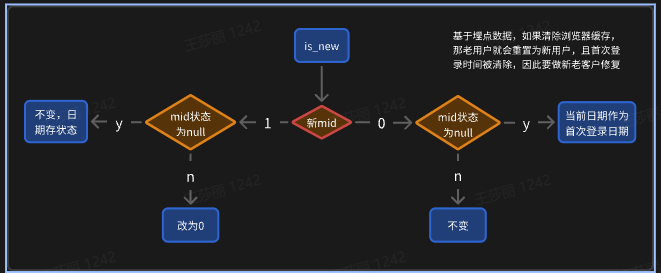
维度变化:实时不考虑,离线要考虑每天保留全量 → 全量快照表 / 拉链表(缓慢变化维)
多值维度:事实表的一条记录对应维度表的多条记录 → 降低事实表的粒度(order_info维度一个订单降为一个sku)
多值属性:维度表某个属性有多个值 key1:value1,key2:value2
dim_sku_full
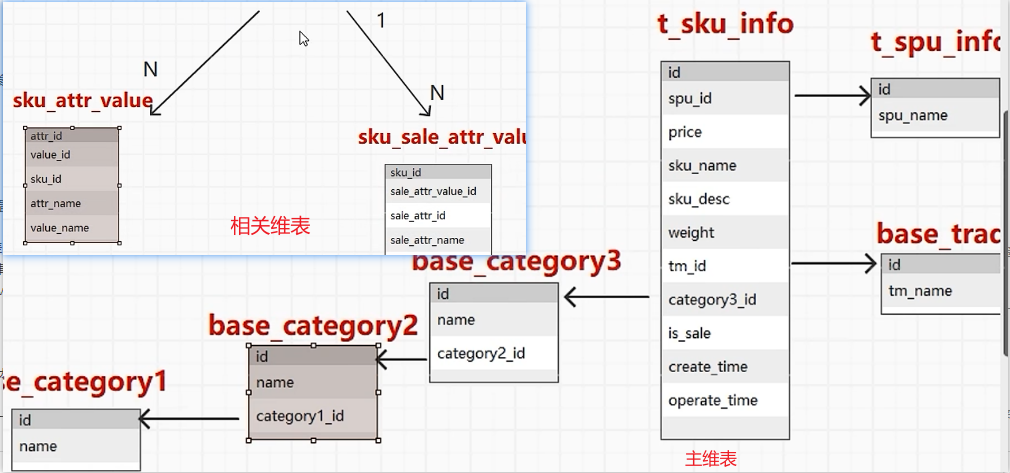
dim_user_zip
3. DWD事实表
维度 + 度量值 将行为描述清楚

建表步骤
- 选择业务过程 → 表 → dwd_trade_cart_add_inc
- 声明粒度 → 行 → 用户 + 时间 + 商品 + 数量
- 确认维度 → 列 → user + date + sku + num
- 确认事实 → 度量值 → num + count
表分类
- 事务型 → 原子操作(login_success login_fail) 粒度越细(维度越多) → 增量同步
- 周期快照 → 用加减表求存量,但是要join效率太差,而业务表中sku_num本来就是存量字段,直接全量同步
- 累积快照 → 多个同一个流程中的业务行为累积到一张表,有多个日期 →
dwd_user_register_inc
dwd_user_login_inc
用户登录和注册都跟页面浏览有关,当离开页面的时候产生日志。页面访问是跟会话相关的,clien连通server端后才是一个会话uuid,超时重连是新的会话,也要重新登陆。
用户注册:一定是在注册页面,成功后携带uid,注册时间取自业务表。
用户登录:同一个会话中uid不为null的时间最早的一条数据即为一次登录。
dwd_trade_trade_flow_acc交易域交易流程累积快照事实表
下单-支付-收货 的平均时间间隔
理论上用uid关联下单表join支付表,求diff,然后直接avg就可以,但是在用户的基础上大表join大表效率差,所以用累计快照表。
4. DWS 预聚合
参考ADS表 指标体系
1d:1天的数据,来自DIM,DWD
nd:N天的数据,来自1d表
td:所有数据,来自DIM,DWD,1d表,每日数据装载避免重复计算可以用历史旧表+今天的新表聚合汇总
5. ADS指标体系
数据域
用户域 → 用户注册、登陆
互动域 → 收藏 评论
工具域 → 优惠券领取、使用
交易域 → 加购、下单、支付、退款
流量域 → UV 跳出会话数 浏览时长
统计指标
原子指标:业务过程 + 度量值 + 聚合逻辑 订单总和
派生指标:原子指标 + 统计周期 + 限定条件 + 统计粒度 最近一天各省份手机品类订单总和
衍生指标:多个派生指标运算 比率
商品主题
最近1/7/30日各品牌下单次数和金额统计
①筛选最近1/7/30的数据union.
②order要joinsku表,sku是全量的,筛选最近几日就会出现几次,join就就有几条,sku因此sku用最近1天的最新的数据即可.
③ads不分区,sql脚本可能会失败重试,所以用overwrite,但是历史数据就会被替代,因此要先查出来再union.
insert overwrite table ads_order_stats_by_cate
select * from ads_order_stats_by_cate
union
SELECT * from(
select ...from[od1] --最近1天
union all
select ...from[od7] --最近7天
union all
select ...from[od30] --最近30天
)t
--1天
SELECT
'2022-06-8',
1,
count(DISTINCT order_id) order_count, --按照order_id统计次数
count(DISTINCT user_id) order_user_count,
tm_id,
tm_name
FROM
(SELECT order_id,
user_id,
sku_id
FROM dwd_trade_order_detail_inc
WHERE dt='2020-06-08')od --1
--WHERE dt>=date_sub('2020-06-08',6) and dt<=’2020-06-08’)od7 --7
--WHERE dt>=date_sub('2020-06-08',29) and dt<=’2020-06-08’)od7 --30
LEFT JOIN
(SELECT id,
tm_id
FROM dim_sku_full
WHERE dt='2020-06-8')sku ON od.sku_id=sku.id
GROUP BY tm_id,tm_name;
④避免重复计算,因此提前把一天的数据计算好,7/30的数据从1d的表中取.
--封装一天的表dws_order_status_by_tm_1d 再union
tm_name,
tm_name,
order_count_1d,
ordrr_user_count_1d
partition by('dt' String)
--装载数据
Insert overwrite table dws_order_status_by_tm_1d partition (dt=’2020-06-08’)
SELECT
tm_id,
tm_name,
count(DISTINCT order_id) order_count_1d,
count(DISTINCT user_id) order_user_count_1d,
FROM
(SELECT order_id,
user_id,
sku_id
FROM dwd_trade_order_detail_inc
WHERE dt='2020-06-08')od --1
LEFT JOIN
(SELECT id,
tm_id
FROM dim_sku_full
WHERE dt='2020-06-8')sku ON od.sku_id=sku.id
GROUP BY tm_id,tm_name;
⑤避免重复读取:读取次数 io次数,大量小文件,同时打开文件的数量是有限制的,所以读一次,获取时间范围最大的数据集,在内存中炸裂出3份数据,标记,将炸裂后的数据筛选过滤保留有效时间数据,然后根据标记分组统计。
--test
SELECT*
FROM
(SELECT 'a'
FROM)t LATERAL VIEW explode(array(1,7,30)) tmp AS tag
WHERE tag!=7;
a 1
a 7
a 30
--最终sql
SELECT
'2020-06-08',
days,
tm_id,
tm_name,
sum(order_count_1d),
sum(ordrr_user_count_1d)
FROM dws_order_status_by_tm_1d LATERAL VIEW explode(array(1,7,30)) tmp AS days
WHERE dt>=date_sub('2020-06-08',days-1) AND dt<='2020-06-08'
GROUP BY days,tm_id,tm_name;
⑥同理如果有用到7天/30天的数据,也可以将其封装为一张表,只要在这个时间范围内的指定时间的需要都可以查询。
--封装7天的数据表
Insert overwrite table dws_order_status_by_tm_7d partition (dt=’2020-06-08’)
SELECT
tm_id,
tm_name,
sum(order_count_1d) order_count_7d,
sum(ordrr_user_count_1d) order_user_count_1d
FROM dws_order_status_by_tm_1d
WHERE dt>=date_sub('2020-06-08',6) AND dt<='2020-06-08'
GROUP BY tm_id, tm_name;
--封装30天的数据表 这里可以直接获取7天的数据,因为重复计算了。
Insert overwrite table dws_order_status_by_tm_30d partition (dt=’2020-06-08’)
SELECT
tm_id,
tm_name,
sum(order_count_1d) order_count_30d,
sum(ordrr_user_count_1d) order_user_count_30d
FROM dws_order_status_by_tm_1d
WHERE dt>=date_sub('2020-06-08',29) AND dt<='2020-06-08'
GROUP BY tm_id, tm_name;
SELECT
tm_id,
tm_name,
sum(if(dt>=date_sub('20220-06-08',6),order_count_7d,0) order_count_7d,
sum(if(dt>=date_sub('20220-06-08',6),order_user_count_7d,0) order_count_7d,
sum(ordrr_user_count_1d) order_user_count_7d,
sum(order_count_1d) order_count_30d,
sum(ordrr_user_count_1d) order_user_count_30d
FROM dws_order_status_by_tm_1d
WHERE dt>=date_sub('2020-06-08',29) AND dt<='2020-06-08'
GROUP BY tm_id, tm_name;
二、ADS指标
流量主题
渠道流量统计 跳出率=页数浏览数=1的会话/总会话数量 浏览时长
路径分析 桑基图(有向无环) 从哪个页面来 跳到哪个页面 次数
商品主题
复购率
购物车topN
收藏topN
交易主题
下单到支付时间间隔
省份交易统计
用户主题
留存率
行为漏斗分析
连续下单用户
日活、新增活跃
留存率
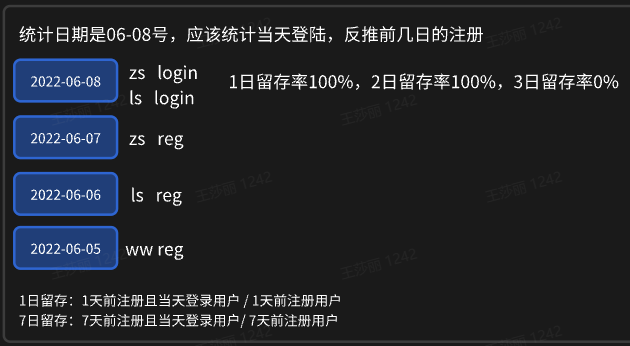
--1日留存率
SELECT
'2022-06-08', --统计日期
date_sub('2022-06-08',1), --用户新增日期
1, --留存天数
sum(if(login_date_last='2020-06-08'),1,0) ,--留存用户数据 1天前注册且当天登陆的用户
count(*), --新增用户数
sum(if(login_date_last='2020-06-08'),1,0) / count(*) --留存率
FROM dws_user_user_login_td --历史至今表
WHERE dt = '2022-06-08'
AND login_date_first = date_sub('2022-06-08', -1) --首次登陆
--2日留存率
SELECT
'2022-06-08', --统计日期
date_sub('2022-06-08',2), --用户新增日期
2, --留存天数
sum(if(login_date_last='2020-06-08'),1,0) ,--留存用户数据 2天前注册且当天登陆的用户
count(*), --新增用户数
sum(if(login_date_last='2020-06-08'),1,0) / count(*) --留存率
FROM dws_user_user_login_td --历史至今表
WHERE dt = '2022-06-08'
AND login_date_first <= date_sub('2022-06-08', -2) --首次登陆
--1-7日留存
insert overwrite table ads_user_retention
select * from ads_user_retention
union
select '2022-06-08' dt,
login_date_first ,
datediff('2022-06-08', login_date_first) retention_day,
sum(if(login_date_last = '2022-06-08', 1, 0)) retention_count,
count(*) new_user_count,
cast(sum(if(login_date_last = '2022-06-08', 1, 0)) / count(*) * 100 as decimal(16, 2)) retention_rate
from (
select user_id,
login_date_last,
login_date_first
from dws_user_user_login_td
where dt = '2022-06-08'
and login_date_first >= date_add('2022-06-08', -7)
and login_date_first < '2022-06-08'
) t1
group by login_date_first; --按照日期分组
用户变动统计

insert overwrite table ads_user_change
select * from ads_user_change
union
select
churn.dt,
user_churn_count,
user_back_count
from
(
select
'2022-06-08' dt,
count(*) user_churn_count
from dws_user_user_login_td
where dt='2022-06-08'
and login_date_last=date_add('2022-06-08',-7) --末次登陆是7天前
)churn
join
(
select
'2022-06-08' dt,
count(*) user_back_count
from
(
select
user_id,
login_date_last
from dws_user_user_login_td
where dt='2022-06-08'
and login_date_last = '2022-06-08' --当天登陆
)t1
join
(
select
user_id,
login_date_last login_date_previous
from dws_user_user_login_td
where dt=date_add('2022-06-08',-1)
)t2
on t1.user_id=t2.user_id
where datediff(login_date_last,login_date_previous)>=8 --且昨天末次登陆是7天前
)back
on churn.dt=back.dt;
7连3
select
count(distinct(user_id))
from
(
select
user_id,
datediff(lead(dt,2,'9999-12-31') over(partition by user_id order by dt),dt) diff
from dws_trade_user_order_1d
where dt>=date_add('2022-06-08',-6)
)t1
where diff<=3;
三、 实时数仓
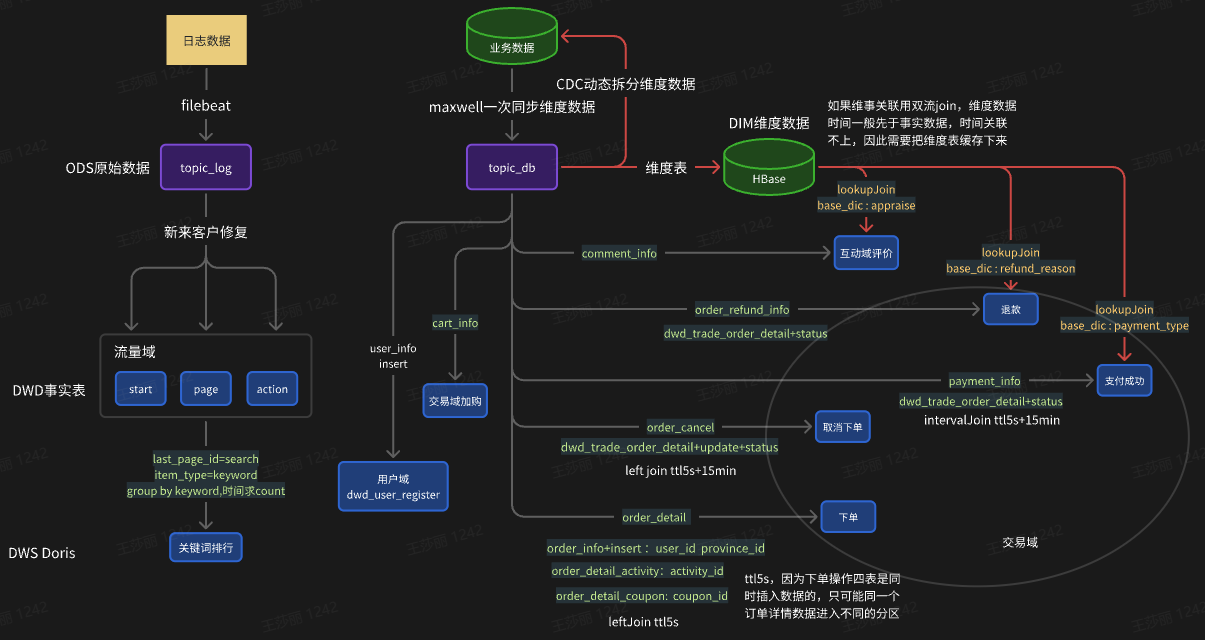
维表的处理:
离线:主维表和相关维表join每天全量同步一次。
实时:不需要同步历史维表数据。
ADS用户域 :回流/新增/活跃 sum
DWS用户域 :backCt register_ct uuCt
用户登录 - 7日回流 & 当日活跃用户
dwd_traffic_page keyby uid
backCt :lastLoginDt != null && diff >=8天
uuCt :if (lastLoginDt == null || !lastLoginDt.equals(curDt)) 则1,更新dt状态;或者用mid
用户注册
dwd_user_register
register_ct:if (createTime != null && id != null) 则1
windowAll reduce
ADS流量域 :各渠道流量统计 独立访问数/会话总数/会话浏览页面数/会话停留时长 group by ch sum
DWS流量域 : uvCt/svCt/pvPerSession/durPerSession
各渠道页面浏览
dwd_traffic_page keyby mid
uvCt:if (lastLoginDt == null || !lastLoginDt.equals(curDt)) 则1,更新dt状态;或者用mid
svCt: last_page_id=null 则1
pvPerSession:来一条数据则1
durPerSession```
首页、详情页页面浏览汇总
page keyby mid
detailUvCt:1
homeUvCt:if (lastLoginDt == null || !lastLoginDt.equals(curDt)) 则1,更新dt状态;或者用mid
ADS交易域 :
DWS交易域 :
加购独立用户
dwd_trade_cart_add keyby user_id
if (ts != null && userId != null)
lastLoginDt状态是独立用户则1
windowAll reduce
支付成功独立用户 支付成功新用户
dwd_trade_order_payment_success
keyby user_id
SKU粒度下单汇总 / 省份下单次数 金额
order_detail涉及left join回撤流,如果要聚合度量值会重复计算,因为需要按照detail_id去重,只保留最后一条数据,注意回撤流最多只有3条数据
dwd_trade_order_detail key by order_detail_id