
Paimon数据湖
1.数据湖三足鼎立
https://cloud.tencent.com/developer/article/2397256
什么是数据湖?
集中的存储 多种格式的数据源无需结构化处理 不同类型的分析加工
为什么需要?
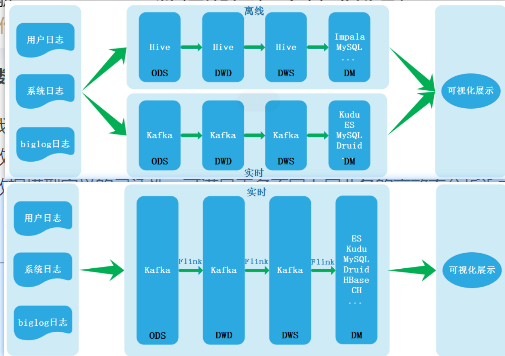
- lambda架构 基于hive的离线+基于kafka的实时
- 两条链路数据不一致
- 批导入数据schemabu不规范,每个作业都要过滤数据
- ACID语义不保证
- 无法高效upsert/delete历史数据
- Kappa架构 基于kafka+Flink(实时数仓)
- 无法海量存储
- 不支持OALP
- 不支持update
- 数据质量管理困难
- Lakehouse架构 解决存储层面的流批一体的问题 支持数据管理和高效访问
数据湖与数据仓库的不同?
- 存储数据类型
建模,结构化数据 VS 原始数据 - 数据处理模式
写时模式 VS 读时模式
数据湖技术比较
https://cloud.tencent.com/developer/news/596887
-
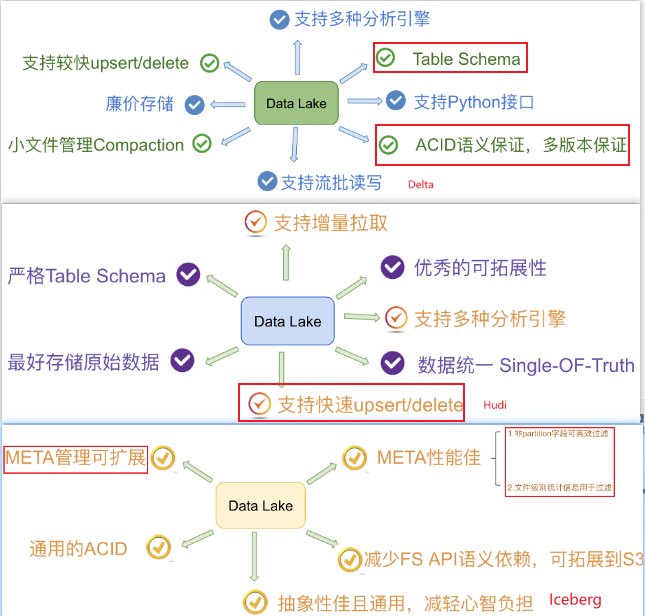
Delta:
- 解决lambda架构实现流批一体 想看时间轴上的点击事件,只能得到实时的聚合结果
- 没有主键,upserts是通过两条流操作;
- Delta 在数据 merge 方面性能不如 Hudi,在查询方面性能不如 Iceberg;
- 查询依赖spark
-
Hudi:
- 解决增量更新历史数据和下游的流式增量消费
- fast upsert每次将增量更新的数据写一个独立的文件集,定期compaction
- compaction是基于 HoodieKey + BloomFilter,效率较高
-
iceberg:高性能的分析与可靠的数据管理
- 解决时间分区,hdfs分区和数据文件多,元数据在Mysql,分区裁剪耗时严重
- 没有主键,upserts是通过两条流操作;小文件合并没有解决
- 查询性能高:对列做了信息收集,查询时用来过滤,隐藏分区
-
Pamion vs Hudi:
https://zhuanlan.zhihu.com/p/681073391- 读写耗时,append和upsert场景,开启和关闭compaction,hudi COW都是比paimon耗时长3倍,且占内存更多,文件数据多一倍,查询场景更明显有7倍的差距。MOR表相反。
2.Paimon
2.1 概念
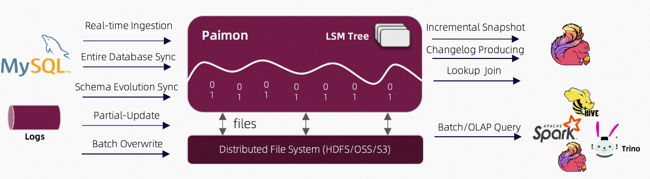
- 读:支持从历史快照读(批模式)、最新的offset(流模式)
- 写:支持离线的批量插入和覆盖、数据库变更日志(CDC)的流式同步
- 存储:表数据和元数据存储在文件系统 / Hive Catalog
- 引擎:支持Flink、Hive、Spark
Compaction
paimon是采用LSM(日志结构合并树)作为文件存储的数据结构。将数据分为多个sorted run,多个sorted run主键会重复。
合并策略:默认sorted run个数为5会触发合并。合并时开销变大,paimon write单独创建一个线程异步执行压缩。当数据达到阈值,writer暂停写入,提高写入性能。

2.2 使用
2.2.1 环境
1.jar放在flink/lib下
https://repository.apache.org/snapshots/org/apache/paimon/paimon-flink-1.17/0.5-SNAPSHOT/
2.创建Paimon Catalog(Catalog.database.table)
vim sql-client-init-paimon.sql
CREATE CATALOG fs_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs://172.31.15.13:4007/paimon/fs'
);
USE CATALOG fs_catalog;
SET 'sql-client.execution.result-mode' = 'tableau';
2.2.2 启动flink sql客户端
sql-client.sh -s yarn-session -i conf/sql-client-init-paimon.sql
show catalogs;
show current catalog;
CREATE TABLE test1(
user_id BIGINT,
item_id BIGINT
);
CREATE TABLE test2 AS SELECT * FROM test1;
-- 指定分区
CREATE TABLE test2_p WITH ('partition' = 'dt') AS SELECT * FROM test_p;
-- 指定配置
CREATE TABLE test3(
user_id BIGINT,
item_id BIGINT
) WITH ('file.format' = 'orc');
CREATE TABLE test3_op WITH ('file.format' = 'parquet') AS SELECT * FROM test3;
-- 指定主键
CREATE TABLE test_pk WITH ('primary-key' = 'dt,hh') AS SELECT * FROM test;
-- 指定主键和分区
CREATE TABLE test_all WITH ('primary-key' = 'dt,hh', 'partition' = 'dt') AS SELECT * FROM test_p;
CREATE TABLE test_ctl LIKE test;
① 管理表(内部表) 在 Paimon Catalog中创建的表就是Paimon的管理表,由Catalog管理
CREATE TABLE test_p (
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh);
② 外部表 由Catalog管理但不记录
CREATE TABLE ex (
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) WITH (
'connector' = 'paimon',
'path' = 'hdfs://hadoop102:8020/paimon/external/ex',
'auto-create' = 'true'
);
③ 临时表
CREATE TEMPORARY TABLE temp (
k INT,
v STRING
) WITH (
'connector' = 'filesystem',
'path' = 'hdfs://hadoop102:8020/temp.csv',
'format' = 'csv'
);
2.2.3 DML
INSERT INTO / INSERT OVERWRITE(batch) / UPDATE(batch主键表) / DELETE / Merge Into(主键表实)行级更新相当于upsert
Merge Into
准备两张表
CREATE TABLE ws1 (
id INT,
ts BIGINT,
vc INT,
PRIMARY KEY (id) NOT ENFORCED
);
INSERT INTO ws1 VALUES(1,1,1),(2,2,2),(3,3,3);
CREATE TABLE ws_t (
id INT,
ts BIGINT,
vc INT,
PRIMARY KEY (id) NOT ENFORCED
);
INSERT INTO ws_t VALUES(2,2,2),(3,3,3),(4,4,4),(5,5,5);
需求:将ws_t中ts>2的vc改为10,ts<=2的删除
flink run \
paimon-flink-action-0.8-20240426.002031-71.jar \
merge-into \
--warehouse hdfs://172.31.15.13:4007/paimon/fs \
--database default \
--table ws_t \
--source-table default.ws1 \
--on "ws_t.id = ws1.id" \
--merge-actions matched-upsert,matched-delete \
--matched-upsert-condition "ws_t.ts > 2" \
--matched-upsert-set "vc = 10" \
--matched-delete-condition "ws_t.ts <= 2";
2.2.4 DQL查询
RESET 'execution.checkpointing.interval';
SET 'execution.runtime-mode' = 'batch';
--时间旅行
SELECT * FROM ws_t /*+ OPTIONS('scan.snapshot-id' = '1') */;
SET 'execution.runtime-mode' = 'streaming';
--时间旅行
SELECT * FROM ws_t /*+ OPTIONS('scan.mode' = 'latest') */;
SELECT * FROM test_p WHERE dt > '2023-07-01';
2.2.5 维表Join
2.2.6 集成CDC
1.添加Flink CDC 连接器
将flink-sql-connector-mysql-cdc-2.4.2.jar放入flink/lib
2.同步表
flink run \
paimon-flink-action-0.8-20240426.002031-71.jar \
mysql-sync-table \
--warehouse hdfs://172.31.15.13:4007/paimon/fs \
--database default \
--table order_info_cdc \
--primary-keys id \
--mysql-conf hostname=172.31.15.7 \
--mysql-conf username=root \
--mysql-conf password=Xnetworks@c0M \
--mysql-conf database-name=bigdata \
--mysql-conf table-name='oatuth_role' \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=4;
3.同步库
flink run \
paimon-flink-action-0.8-20240426.002031-71.jar \
mysql-sync-database \
--warehouse hdfs://172.31.15.13:4007/paimon/fs \
--database default \
--table-prefix "ods_" \
--table-suffix "_cdc" \
--primary-keys id \
--mysql-conf hostname=172.31.15.7 \
--mysql-conf username=root \
--mysql-conf password=Xnetworks@c0M \
--mysql-conf database-name=bigdata \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=4;
4.同步kafka
flink run \
paimon-flink-action-0.8-20240426.002031-71.jar \
kafka-sync-table \
--warehouse hdfs://172.31.15.13:4007/paimon/fs \
--database default \
--table kafka_waf_ip \
--primary-keys id \
--kafka-conf properties.bootstrap.servers=172.31.15.21:9092 \
--kafka-conf topic=waf_ip \
--kafka-conf properties.group.id=wsl \
--kafka-conf scan.startup.mode=earliest-offset \
--kafka-conf value.format=canal-json \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=4;
2.2.7 集成Doris
1.在doris中创建catalog查询paimon表
CREATE CATALOG `paimon_hdfs` PROPERTIES (
"type" = "paimon",
"warehouse" = "hdfs://172.31.15.13:4007/paimon/fs",
"dfs.nameservices" = "HDFS8000871",
"dfs.ha.namenodes.HDFS8000871" = "nn1,nn2",
"dfs.namenode.rpc-address.HDFS8000871.nn1" = "172.31.15.13:4007",
"dfs.namenode.rpc-address.HDFS8000871.nn2" = "172.31.15.13:4007",
"dfs.client.failover.proxy.provider.HDFS8000871" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",
"hadoop.username" = "hadoop"
);
use CATALOG paimon_hdfs;
select * from table;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号