bbs02之登录 首页导航条 主页面搭建 侧边栏
登录功能
pillow模块生成验证码
创建画笔对象:

用pillow模块写字还需要ttf字体文件。
去网上下载ttf字体文件:
https://www.fonts.net.cn/font-41698350290.html
https://font.chinaz.com/
确定字体样式:

truetype函数:

编写随机验证码相关代码:

将随机验证码写到图片上:

text第一个参数表示的是写字的位置(以左上角为标准):
(x, y)
后端保存验证码,便于后续比对:
验证码数据要在不同的函数使用,等会要在login函数使用。所以需要找一个所有人都能访问的地方。

1.全局变量
2.session表
实现验证码点击之后刷新:
原理:img标签的src属性的服务器路由发生变化时(使用?加参数),img标签会重新发送get请求。
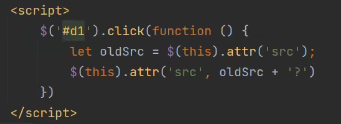
前端发送ajax请求
form标签序列化功能:

但是这个功能这种情况不适用,还是依次获取输入框的数据:

后端auth模块校验

比对验证码、比对用户名和密码。
注意:忽略验证码的大小写
auth模块自动加密,然后拿密文进行比对:

登录成功后跳转到首页。
前端回调函数:

sweetalert弹窗提示登录失败

可以使用sweetalert美化弹窗。
官网:https://sweetalert.js.org/
使用参考:www.cnblogs.com/Dominic-Ji/p/9234099.html
后端保存用户登录状态:

首页导航条搭建
网站首页路由:

修改bootstrap导航条:

添加注释:

反向解析:

判断当前用户是具体用户还是匿名用户,返回true或者false:

根据是否登录展示不同的功能:

修改密码
点击修改密码,触发模态框:

研究模态框:

发现按钮的data-toggle属性和data-target属性跟模态框有关。
修改模态框文本内容:

在模态框内部使用ajax:

设置disable仅仅展示用户名,不让用户修改。
给按钮绑定点击事件:

添加修改密码的路由:
修改密码的视图层:
校验用户是否登录装饰器
导入auth模块:


settings配置:

前端获取数据:

后端修改密码逻辑:

校验原密码是否正确:

避免新密码和二次输入密码是空:

注意保存:

正确情况逻辑编写完成,补上错误情况的后端逻辑:

前端在模态框加一个标签提示修改成功:

前端回调函数:

效果:

注意:修改密码之后,登录状态会消失,需要重新登录。
退出登录
开启新路由:

前端绑定路由:
添加装饰器:

使用auth模块的退出功能,退出登录后跳转到首页。
首页主体部分
首页前端框架搭建
模仿博客园:

前端282布局:

广告样式编写:
使用面板(样式为panel-primary):

首页左侧右侧广告位:

首页中间区域展示文章内容。此时需要先往数据库录入一些数据。
此时不建议用django连接数据库录入数据,因为表之间的外键关系复杂,数据录入错误(或者外键关系绑定错误)会导致用户信息错乱(用户A的站点显示用户B站点的文章)
此时数据录入工具使用:django admin后台管理
admin后台管理使用
需要使用到超级管理员。所以先要创建一个管理员账号
需要修改admin.py:
 注册想操作的模型表。
注册想操作的模型表。
 注意:admin.py 每个app都有一个。
注意:admin.py 每个app都有一个。
注册完成之后,django针对你注册的表,会自动生成增删改查功能(图形化界面):
注册所有模型表:

查看后台管理:

模型表的名字 尾部都会自动添加s。
修改admin后台为中文:
去模型类添加代码:

这个代码和数据库没有联系,无需迁移数据库。
查看admin后台:

数据录入
表直接关系复杂,直接录入容易错误,所以使用admin后台进行添加。
绑定错误会导致用户信息错乱。
我登录,访问的是别人的站点。
入手 --- 文章表:

父子页面通信:

先录入站点 和 分类:
站点:

显示问题:

这里就需要加双下str:

查看效果:

添加分类:

添加文章:

查看文章:

绑定用户表:
用户绑站点别忘了
会报错,报错原因:
报错是因为admin后台有字段没填写。
这是数据库层面的约束。
所以可以也让后台管理不写:

分类:
文章和标签:
创建标签:

文章标签绑定:
注意用户1的文章 要和 用户1的标签绑定:

这里不同人的文章是放一起的,别弄错。
首页查询数据库文章
添加分页器:

导第三方py文件:

分页器产生页面对象:

对页面对象进行切片。
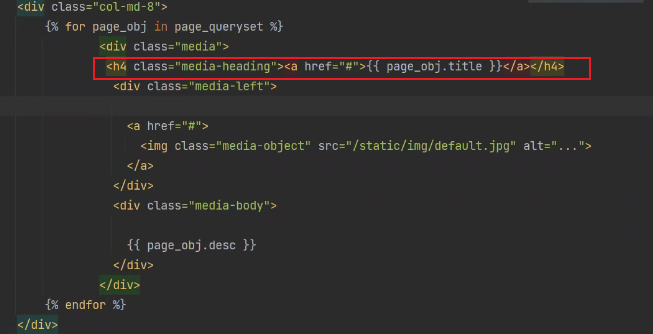
前端渲染文章:

bootstrap媒体对象:

修改媒体对象:


文章标题应该a标签 头像位置调整
头像下面展示用户名 文章发布时间 点赞点踩
修改媒体对象:
分割线:

渲染用户名 文章发布时间 点赞点踩:

整体样式调整:

上下分页器添加:

media自定义暴露资源
不只是静态文件,可以暴露后端的任意资源供访问。
修改src为数据库存放的avatar路径:

浏览器查看:

查看原因:

是因为没有开启avatar路径的访问权限!
media 配置:
用户写博客穿插图片,这些图片属于静态资源。
需要给用户存放,用户上传的静态文件资源。
查看博客园:

希望用户上传的东西,都存放在同一个目录下,然后再进行具体划分。
修改settings文件:

这个目录会自动创建。
注册新用户:

用户上传的文件会 存到media
然后根据模型表字段的限制,会自动在media生成相应的目录:

暴露后端的任意资源供访问:
不是静态文件暴露,需要路由层写接口:
还要导入模块。

使用re_path:

第三个参数写配置文件的Media路径(导入settings)。
需要字典,否则会报错:

浏览器访问示例:

此时media目录就已经暴露出来了。
修改前端页面:
此时media目录下的所有文件都可以访问了。
还可以暴露其他的目录:

意味着用户可以访问你写的代码:

访问示例:

不要暴露不该用的东西,会有安全风险。
作业:
用户登录成功之后 显示用户头像。
个人站点页面搭建
路由动态匹配 后端简单逻辑
实现点击用户名 跳转到个人站点。
查看博客园如何实现需求:

发现路由里面包含用户的名字。
先开路由,需要使用动态匹配:

注意:别忘了加斜杠。
后端编写:

判断个人站点是否存在,如果不存在跳转到404页面。
404页面

后端逻辑:

复制博客园404页面:

图片防盗链技术
从别的网站复制过来的页面,经常会出现图片无法加载的现象。这是因为使用了图片防盗链技术。

禁止通过拷贝图片地址 就直接拿到网站的图片。
服务器先问你是从哪里来的,如果是从别的地方来的就不给你图片。
referer键值对 存放你是从哪来的信息:

我们网站的请求头referer参数:

来自博客园的请求头referer:

解决方案:
- 编写图片下载脚本,将图片下载到本地使用。
- 在请求头加referer参数。(写爬虫程序的时候添加)
页面主体初搭建
基于个人站点查询站点下的文章:

站点页示例:(使用2、10布局)

后端逻辑编写:

前端使用模板继承:
-
母板区域划分

-
子板继承:

子板代码编写(布局2):

子板代码编写(布局10)主体内容区:

前端样式修改:
将用户名移动到右边去:

效果展示:

主体部分细节补充
分页器添加:
分页器添加和首页操作一致,不再赘述。后端导入第三方代码,生成页面对象,切片传入前端,在前端使用模板语法for循环渲染即可。
首页用户名a标签路由添加:(实现点击用户名跳转到个人站点的功能)

模拟用户上传css js的代码:

前端根据用户上传的css文件动态加载css样式:

个人站点侧边栏功能完善
需求:

文章分类
拿到当前个人站点下所有分类名称:

统计每个分类下的文章:
使用分组查询。
annotate左边没有values 就按照文章分组。
value后面加annotate可以按照字段分组。
导入聚合函数:

分类查文章(反向查询):
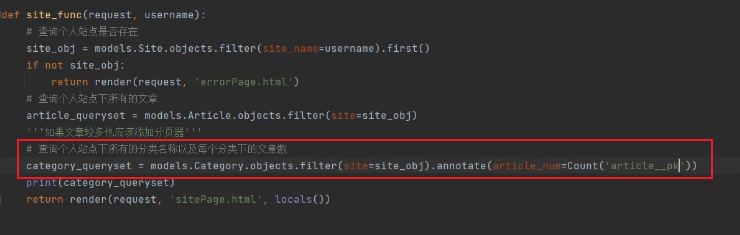
ORM:

查看结果:

前端页面编写(使用category_queryset后端传来的名字):

分类的筛选功能:通过点击文章分类获取该分类下的所有文章。(未实现)
文章标签
查询个人站点下所有的标签名称,以及标签的文章数:

标签前端渲染(使用tag_queryset后端传来的名字):

日期归档
按照年月给文章分组。
我们存储的是年月日时分秒:

orm关于按照字段分组的额外操作:
官网提供查询代码 annotate
由于分组之后再使用聚合函数已经无法满足我们的需求,所以可以使用官网提供的查询代码。
官网提供了针对日期字段的切割处理
id content create_time month
1 111 2020-11-11 2020-11
2 222 2020-11-12 2020-11
3 333 2020-11-13 2020-11
4 444 2020-11-14 2020-11
5 555 2020-11-15 2020-11
"""
django官网提供的一个orm语法
from django.db.models.functions import TruncMonth
-官方提供
from django.db.models.functions import TruncMonth
Sales.objects
.annotate(month=TruncMonth('timestamp')) # Truncate to month and add to select list
.values('month') # Group By month
.annotate(c=Count('id')) # Select the count of the grouping
.values('month', 'c') # (might be redundant, haven't tested) select month and count
时区问题报错
TIME_ZONE = 'Asia/Shanghai'
USE_TZ = False
"""
节选年月:
表中会凭空多一个虚拟字段。也就是按照年月分组的新字段。
annotate 分组 、处理字段
相同的单词放在不同的位置,有不同的意思:

导模块:

不仅可以创建年月字段 还可以创建更多不同类型的虚拟字段
创建虚拟字段:

查看查询结果:

可能会报错:

时区问题
报错信息里面有time zone,往往是时区问题
修改时区为自己本地:

上面的ORM漏了一个查询:

查看ORM查询结果:

前端页面展示年月数据:

