
浏览器的运行原理
一、什么是浏览器
要想了解浏览器的运行原理,首先必须要先了解什么是浏览器。
浏览器是指可以显示网页服务器或者文件系统的HTML文件(标准通用标记语言的一个应用)内容,并让用户与这些文件交互的一种软件。
浏览器的主要功能就是向服务器发出请求,在浏览器窗口中展示您选择的网络资源。这里所说的资源一般是指 HTML 文档,也可以是 PDF、 图片或其他的类型。资源的位置由用户使用URI(统一资源标符)指定。
目前使用的主流浏览器有五个:Internet Explorer、 Firefox、 Safari、 Chrome 和 Opera。
1. 浏览器按照引擎分类
Trident引擎:Internet Explorer
Webkit引擎:Chrome(28版本后基于blink,blink是webkit的一个分支)和Safar
Gecko引擎:Firefox
Presto引擎:早期Opera采用,后用webkit引擎
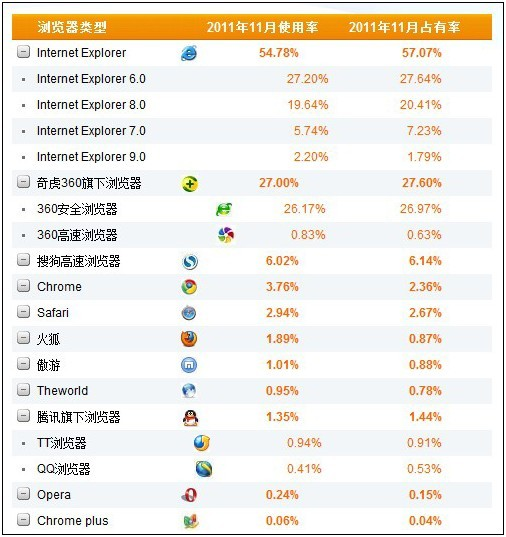
下面是各大浏览器的用户占有率
二、浏览器的主要构成
浏览器的主要组件包括:
- 用户界面:包括地址栏、后退/前进按钮、书签目录等,也就是你所看到的除了用来显示你所请求页面的主窗口之外的其他部分。
- 浏览器引擎:用来查询及操作渲染引擎的接口。
- 渲染引擎:用来显示请求的内容,例如,如果请求内容为html,它负责解析html及css,并将解析后的结果显示出来。
- 网络:用来完成网络调用,例如http请求,它具有平台无关的接口,可以在不同平台上工作。
- UI后端:用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口。
- JS解释器:用来解释执行JS代码。
- 数据存储:属于持久层,浏览器需要在硬盘中保存类似cookie的各种数据,HTML5定义了web database技术,这是一种轻量级完整的客户端存储技术。
浏览器组成部分如图所示:

三、浏览器内核工作原理简介
浏览器包含很多个模块,有网络、资源管理、网页浏览、页面管理、插件、账户、开发者工具等等。其中,网页浏览功能模块是浏览器的核心,它主要完成从HTML文档到可视化的图像转换工作,这是浏览器内核的主要功能。
通常浏览器内核也被称为渲染引擎,它的输入是网络和存储模块获得的HTML文档(包括CSS,JavaScript),渲染引擎的输出就是这些HTML元素描述的图像和JS描述的控制动作。
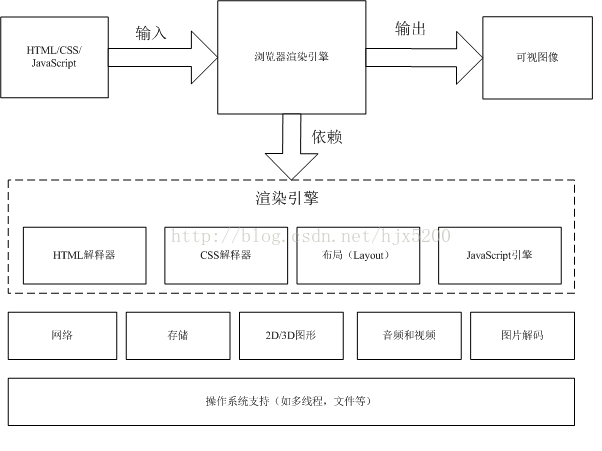
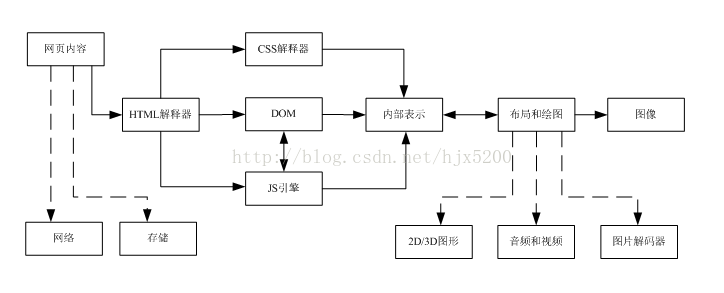
渲染引擎主要分为HTML解释器、CSS解释器、布局以及JavaScript引擎。大体的流程如下:网页内容经过HTML解释器后,构建一颗DOM树,并且将文档中包含的JavaScript脚本交由JS引擎处理,将CSS样式表交由CSS解释器处理;最终DOM树接收CSS解释器解析的样式信息来构建中间模型——绘图模型。该模型再经过布局模块计算内部各元素的位置和大小信息,最后由绘图模块完成从该模型到图像的绘制。
四、前端处理流程简介
1、输入url
2、查看浏览器缓存,看是否有缓存,如果有缓存,继续查看缓存是否过期,如果没有过期,直接返回缓存页面,如果没有缓存或者缓存过期,发送一个请求。
3、浏览器解析url地址,获取协议、主机名、端口号和路径。
4、获取主机ip地址过程
(1)浏览器缓存
(2)主机缓存
(3)hosts文件
(4)路由器缓存
(5)DNS缓存
(6)DNS递归查询
5、浏览器发起和服务器的TCP连接,执行三次握手
6、三次握手连接后,浏览器发送一个http请求
7、服务器收到请求,转到相关的服务程序,期间可能需要连接并操作数据库
8、服务器看是否需要缓存,服务器处理完请求,发出一个响应
9、服务器并根据请求头包含信息决定是否需要关闭TCP连接
10、浏览器对接收到的响应进行解码
11、浏览器解析收到的响应并根据响应的内容进行构建DOM树,构建render树,渲染render树等过程
12、处理嵌入的其他资源如css文件、js文件、图片文件、音视频等文件。
