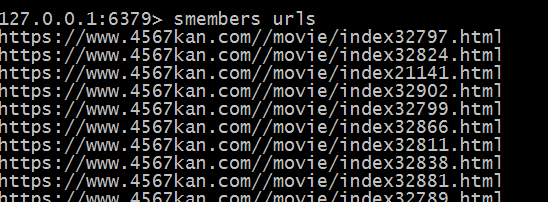
scrapy使用redis实现增量式爬取
监测网站数据更新的情况,只会爬取网站最新更新出来的数据。
实现思路
指定一个起始url
基于CrawISpider获取其他页码链接
基于Rule将其他页码链接进行请求
从每一个页码对应的页面源码中解析出每一个电影详情页的URL,然后解析出电影的名称和简介进行持久化存储
实现增量式核心内容:
使用redis sets检测电影详情页的url之前有没有请求过
将未爬取过的url页的 详情页的url发起请求,
实现代码
创建工程
scrapy startproject moviePro
cd moviePro
scrapy genspider -t crawl movie www.xxx.com
spider文件
# -*- coding: utf-8 -*- import scrapy from redis import Redis from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from moviePro.items import MovieproItem import sys class MovieSpider(CrawlSpider): name = 'movie' # allowed_domains = ['www.xxx.com'] start_urls = ['https://www.4567kan.com/frim/index1.html'] # 得到默认编码 print(sys.getdefaultencoding()) # 连接redis conn = Redis(host='127.0.0.1', encoding='utf-8', port=6379) print(conn) rules = ( Rule(LinkExtractor(allow=r'/frim/index1-\d+\.html'), callback='parse_item', follow=True), # 获取页码对应的url ) def parse_item(self, response): print(response) li_list = response.xpath('//ul[@class="stui-vodlist clearfix"]/li') for li_item in li_list: title = li_item.xpath('./div[@class="stui-vodlist__box"]/div[1]/h4/a/text()').extract_first() # 标题 new_url = 'https://www.4567kan.com/'+li_item.xpath('./div[@class="stui-vodlist__box"]/div[1]/h4/a/@href').extract_first() # url # 将url存入redis的set集合中 item = MovieproItem() item['name'] = title ex = self.conn.sadd('urls',new_url) # print(title) # print(new_url) if ex==1: print("该url没有被爬取过,可以进行数据爬取") yield scrapy.http.Request(url=new_url, callback=self.parse_detail, meta={'item':item}) else: print("数据没有进行更新,没有数据爬取") def parse_detail(self, response): # 简介 desc = response.xpath('//div[@class="stui-content__detail"]/p[5]/span[2]/text()').extract() item = response.meta['item'] item['desc']=''.join(desc).strip() # print(desc) yield item
Pipeline文件
from redis import Redis class MovieproPipeline(object): conn = None def open_spider(self,spider): self.conn = spider.conn def process_item(self, item, spider): dic = { 'name':item['name'], 'desc':item['desc'] } print(dic) self.conn.lpush('movieData',dic) return item
items文件
import scrapy class MovieproItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() name = scrapy.Field() desc = scrapy.Field() pass
运行
scrapy crawl movie 该url没有被爬取过,可以进行数据爬取 …… {'name': '游戏改变者2015', 'desc': '丹尼尔·雷德克里夫有望加盟一部关于《侠盗猎车手》创始人的BBC电视电影,双方正在谈判中丹尼尔将出演山姆·豪泽是Rockstar公司的总裁,他一手推出了《侠盗猎车手》、《马克·佩恩 》等热门游戏,影片将围'} ['象人(约翰•赫特 John Hurt 饰)是一个天生的畸形症患者,他的脸长得就像大象的脸,因此而得名象人一直被利欲昏心的马戏团老板利用,带到世界各地去巡回演出,受尽了非人的虐待。象人所经受的遭遇社会名'] {'name': '象人', 'desc': '象人(约翰•赫特 John Hurt 饰)是一个天生的畸形症患者,他的脸长得就像大象的脸,因此而得名象人一直被利欲昏心的马戏团老板利用,带到世界各地去巡回演出,受尽了非人的虐待。象人所经受 的遭遇社会名'} ……

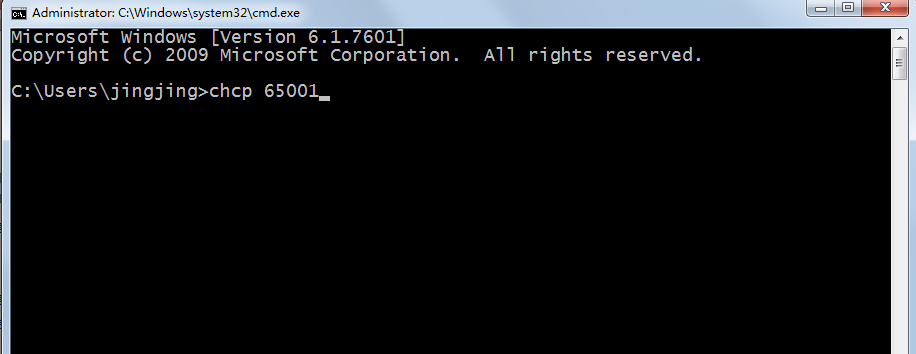
解决redis中文显示乱码
第一步,打开命令窗口,如果我们要修改成UTF8编码,输入命令
CHCP 65001
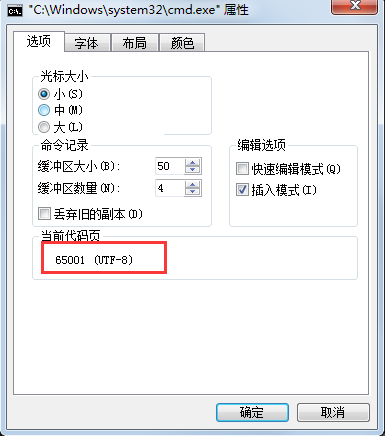
查看验证
设置字体
登录redis客户端
C:\redis64>redis-cli --raw 127.0.0.1:6379> keys * fbs:items age names urls fbs:requests movieData fbs:dupefilter name 127.0.0.1:6379> lrange movieData 0 2 {'name': '飞虎', 'desc': '米妮(梁咏琪 饰)是海关督察,近日里,她获得消息,得知大量毒品即将抵达香港,于是决心调查此案,然而却遭到了毒贩 冰后”强大的火力抵抗,败下阵来飞虎队队长王东(王敏德 饰)带领队员们进驻海关,王东更是坦'} {'name': '恶魔湾', 'desc': 'An interracial lesbian couple commit a murder and have to flee for their lives.'} {'name': '象人', 'desc': '象人(约翰•赫特 John Hurt 饰)是一个天生的畸形症患者,他的脸长得就像大象的脸,因此而得名象人一直被 欲昏心的马戏团老板利用,带到世界各地去巡回演出,受尽了非人的虐待。象人所经受的遭遇社会名'} 127.0.0.1:6379>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号