粗排治理之性能优化
2022年后,被安排维护新闻推荐系统的粗排服务。通过初步摸排,发现该服务存在很大的性能问题。流量高峰期服务可用性只能到1个9,cpu使用率也只能到20%,服务内部存在很大的性能问题。
一 粗排简介
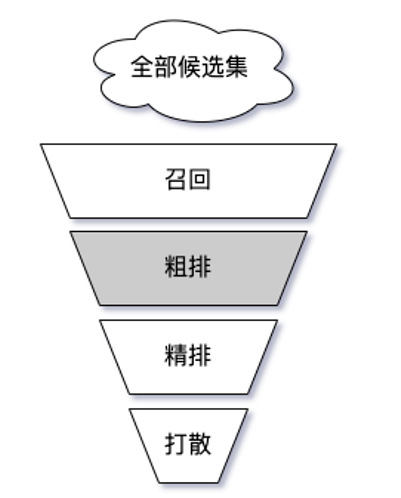
推荐架构中,粗排介于召回和精排之间,是性能和效果的折中的产物。粗排的输入为所有召回的item(万级别,我的应用场景下日常是5000左右,但是经过优化后可以支持万级别输入),输出为进入精排的item(千级别,我的应用场景下日常是600左右)。
新闻推荐系统中,粗排实现的是一个简化的精排模型,双塔结构。用户塔实时抽取特征、计算 embedding。item 塔离线计算 embedding,缓存在 redis 中。用户 embedding 和 item embedding 经过内积计算,得到 item 分数。
粗排的流程如下:
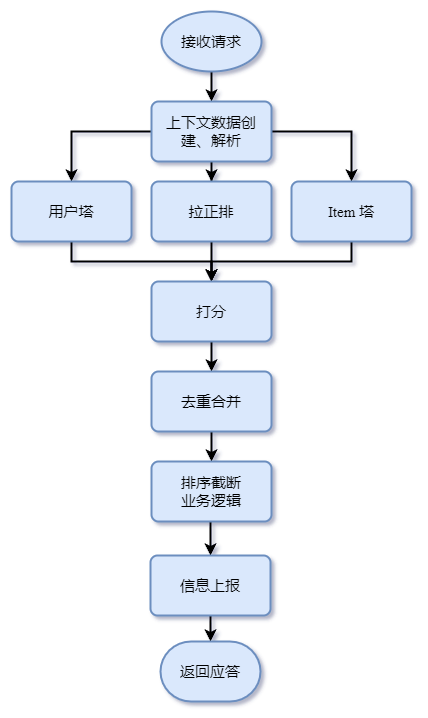
打分之后的排序截断逻辑,会做一些多样性、时效性的调整,从而避免出现信息茧房。
另外,我们的推荐系统中,存在一个中控模块,作为整个系统的出入口和调度中心,依次调用召回、粗排、精排和打散服务。
二 优化手段
1 执行路径优化
上面的流程图中存在几个问题,可以优化降低耗时。
1.1 用户塔预计算
用户塔的计算逻辑,并不依赖召回的返回结果。这一部分逻辑可以前提到与召回并行,效果如下:
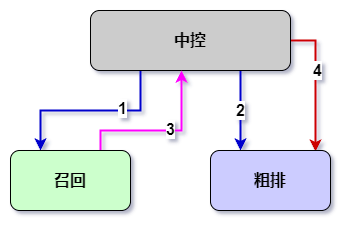
- 中控请求召回(1)的同时,异步下发用户预计算请求(2)给粗排
- 中控收到召回应答(3)后,构造粗排完整请求(4),请求粗排
- 用户预计算请求和完整粗排请求,通过 traceid 定向到同一个粗排实例
- 粗排收到用户预计算请求后,计算用户 embedding,并缓存。收到完整请求后,从缓存中读取 embedding。
1.2 去重合并前提
从性能角度考虑,召回采用了多路独立部署、并行调度的方式。这样存在一个问题,由于各路召回相互隔离,召回的内容存在重复的情况。粗排需要对召回内容进行合并去重处理。
旧的流程中,去重合并放在打分之后,导致前面 item 塔、拉取正排存在重复操作。去重合并提前到上下文数据创建、解析之后,会避免重复计算。
1.3 Debug上报解耦
推荐系统通过远端上报来收集样本以及 debug 信息,旧的实现方式是实时全量拼接样本、实时抽样上报。这样存在三个问题,一是全量拼接、抽样上报,浪费了拼接的算力;二是实时拼接和实时上报占用了会话时间;三是拼接逻辑和数据与业务逻辑耦合在一起,相互交错。
升级后的实现方式是异步抽样拼接、异步上报。简要说就是核心会话数据与上报数据解耦,在response之后,异步启动一个任务,命中抽样的情况下,对上报数据进行拼接处理,然后上报。
2 清理历史负债
在项目落地、业务发展中,总是会有些实现不能满足当前业务需求,或者当时开发时急于上线,留下“垃圾”(实际工作中碰到的更多是这种情况)。
粗排内部有一个比较重的历史负债,就是拉取正排逻辑。有两个地方需要正排数据,一个是用户塔获取用户历史正排,一个是召回 item 正排。正排经过一次大的升级,协议由 protobuf 切换到了 flexbuf。但是当时升级时,只用召回 item 正排切换到了 flexbuf,历史正排还是 protobuf 协议。这两种协议实现各有自己的缓存,造成缓存命中率低、内存浪费。
3 缓存优化
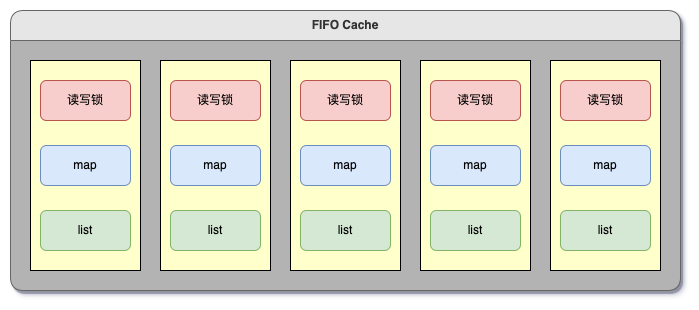
粗排内部多处用到缓存,比较重要的是 item 塔和正排。缓存组件采用的是 lru 置换策略,具体实现如下:
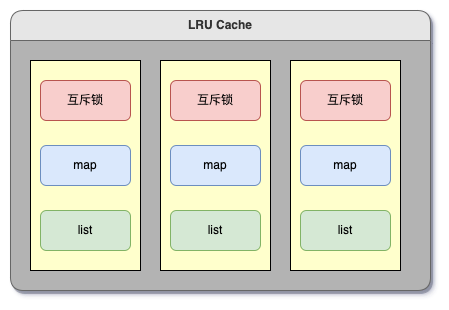
- std::unordered_map 和 std::list 组成一个槽位,每个槽位有一把互斥锁
- 多个槽位组成缓存
- 读写操作时,先对 key hash 计算映射到某一个槽位,然后加锁,读写
通过打点统计,发现粗排用到的 lru 缓存存在很大的性能问题,严重时读取 50 次耗时要到 5ms。我采取了两个变动对缓存做了优化: - 增加槽位数,降低冲突概率
- lru 置换替换为 fifo 置换,互斥锁替换为读写锁
第一个变动好理解,不再赘述。第二个变动,主要是因为粗排场景下,缓存命中率极高,尤其是新闻制定了精品路线战略后,文章减少了很多,命中率上升到了 95% 以上。在这样一个读极多、写极少的场景下,读写锁会有很大性能收益。

4 池化复用
- 对象池。对象池托管会话数据结构、新闻数据结构,能避免每次会话构造析构的开销。需要注意的是每次会话对复用数据的重置。
- 内存池。用户级的内存池在内存分配、释放上有很大的性能优势,之前在百度就是自己实现了内存池。但是新闻推荐粗排这个服务的场景,大的对象就是 protobuf 数据,arena 完全足够。另外,jemalloc 相比 tcmalloc 和 ptmalloc,速度快很多。
- 线程池。百度开源的 bthread 和腾讯内部使用的 Fiber 都是 m:n 的线程池(当然有的人说是带栈的协程,但是我个人理解更像是一个线程池)。
5 并发度优化
粗排基于fiber实现的并发调度,要处理的新闻很多,内部启动了很多 fiber 任务并行处理,尤其是流量高峰期,fiber 任务队列过长,影响了耗时。
- 提前判断,一些 fiber 任务可以提前判定不需要运行
- 在总 cpu 核数不变的情况下,增加实例核数,减少实例数,性能上也有很大收益
6 协议优化
这个简单,http 协议升级为二进制rpc协议,同时添加 snappy 压缩。
成果
平均耗时降低了 60%,可用性有1个9提升到4个9.
