
时序分析(6):时序分析违例和优化
布局布线没有满足我们要求的时序情况下,该如何去解决呢?
一、时序分析的优化流程

二、查看时序报告
1.ILA相关约束可以忽略
2.Report timing summary可以打印所有路径报告,方便查看哪些违例了。
三、解决跨时钟域违例
1、set false path
(1)复位信号,选择point到point,否则所有信号都 false了
(2)跨时钟域信号,可以选择clock到clock。
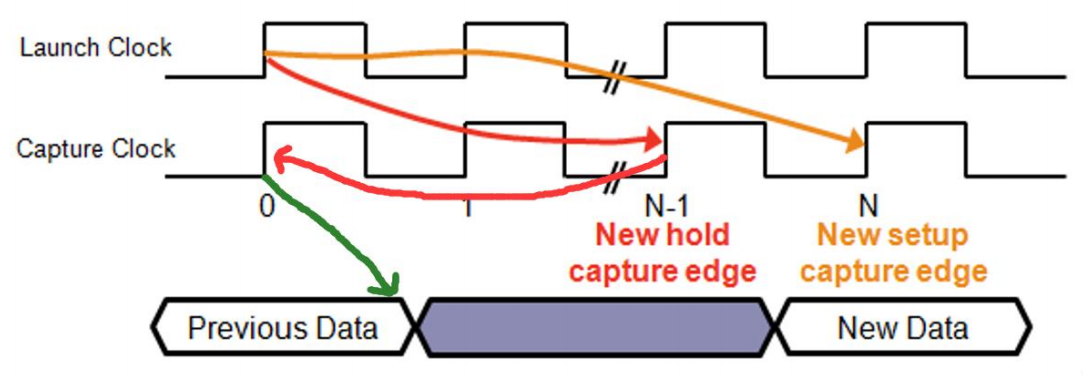
2、Set multicycle
两级寄存器之间有复杂的组合逻辑,导致延迟可能超过1个时钟周期。
(1)修改建立时间:set_multicycle_path -from $from_list -to $to_list <N>,建立时间采样沿在N处,建立时间OK了
(2)保持时间采样沿在N-1处,要求上一个数据的结束位置要在这,太难了,很可能报告时序违例,因此要把保持时间推回原先的采样沿0时刻位置:set_multicycle_path -from $from_list -to $to_list-hold <N-1>,还不行就<N-2>、<N-3>
四、解决同时钟域违例
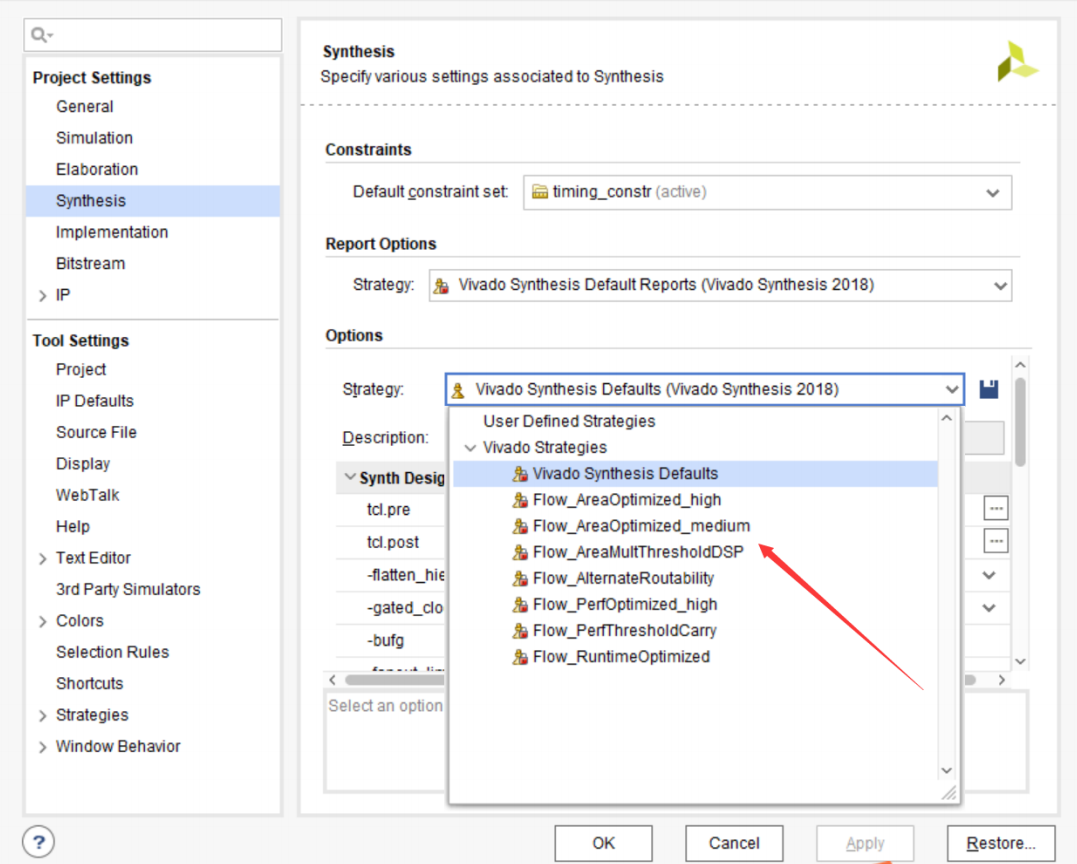
1、synthesis策略
点击 SYNTHESIS --- Synthesis,在Options界面可以选择不同的综合策略,时序改善余地不大。
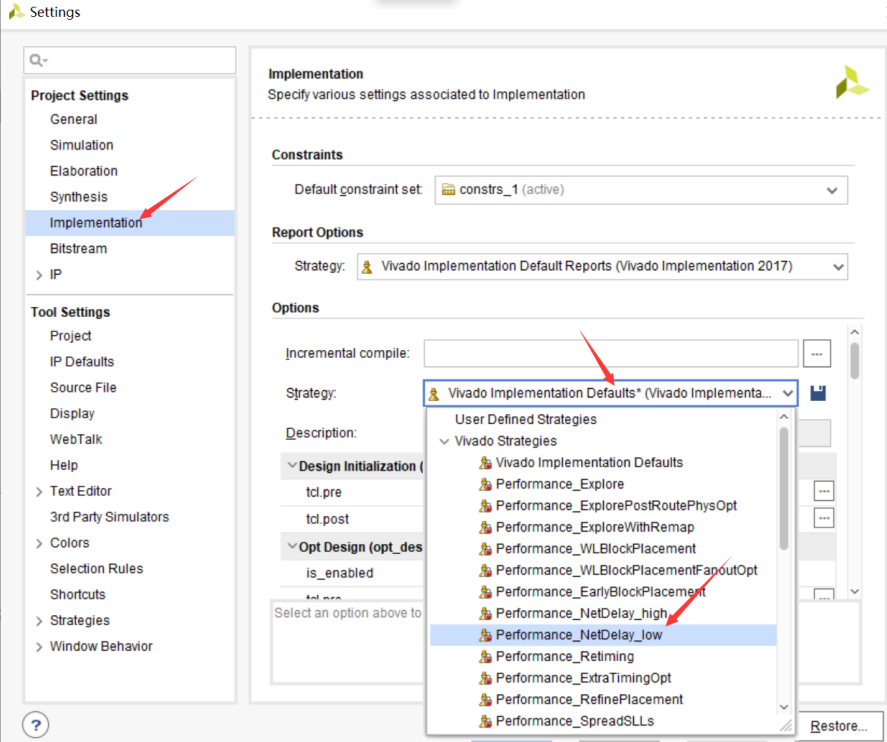
2、Implementation策略
点击 IMPLEMENTTION --- Synthesis,在Options界面可以选择不同的综合策略,进行时序改善。
3、布局布线物理优化(div_timing)
例如乘法器除法器常常出现问题,可以用此方法解决。
(1)设置方法
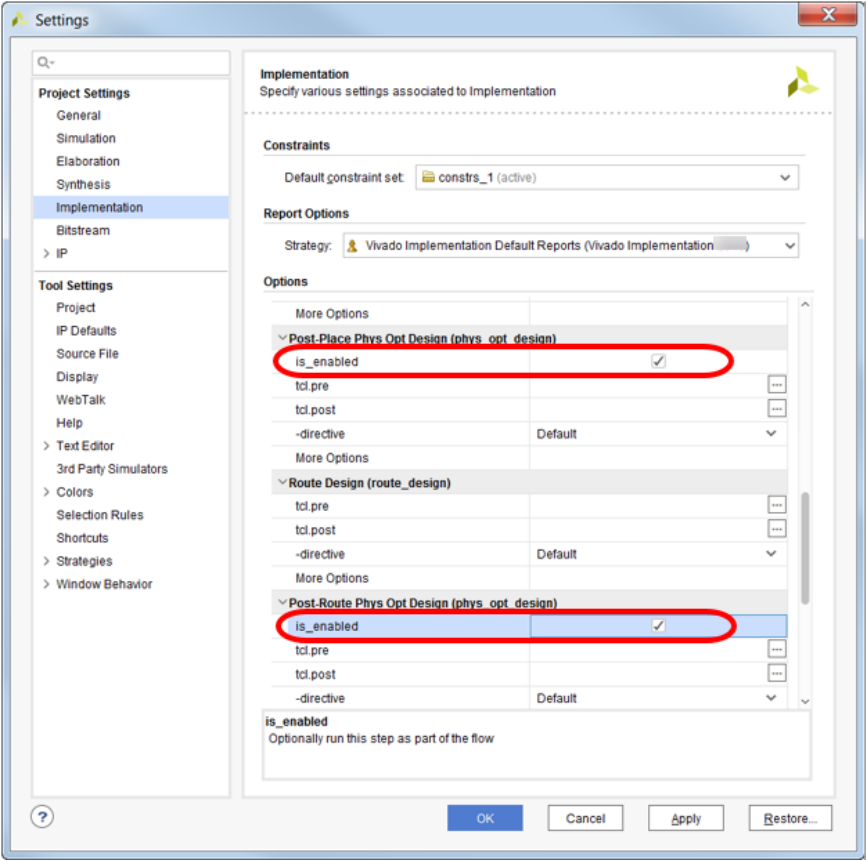
(2)参考依据
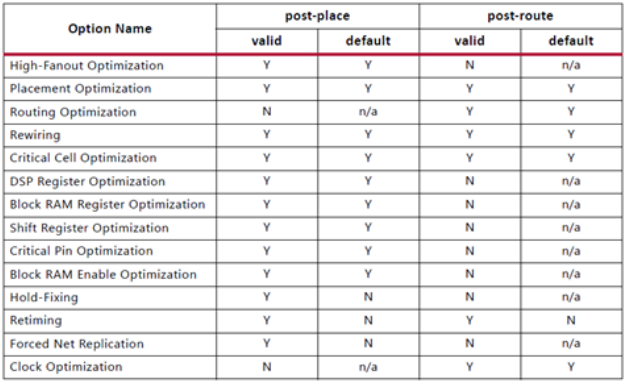
(3)效果展示
①扇出优化(设置post_place phy_opt)
和左侧相比,右边的白线被分割为多个起点扇出,减少了扇出延时。蓝线为优化前的效果。

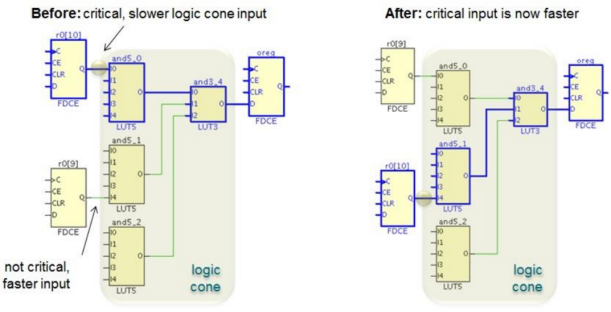
②布局优化
如果一些较长的关键路径存在,布局工具会自动的进行从新规划布局方案使得路径变短,从而优化时序。

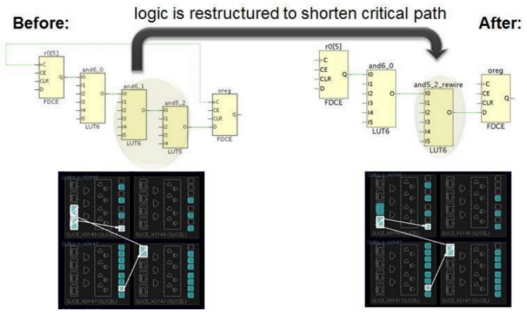
③布线优化
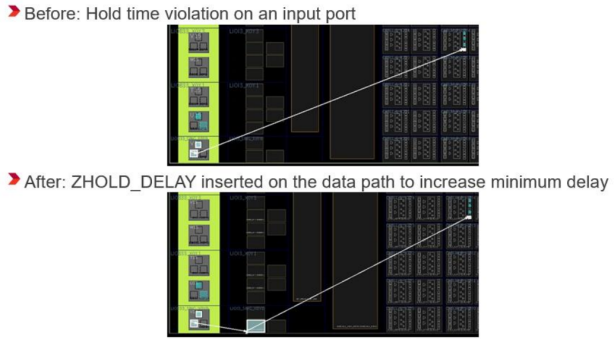
④HOLD FIX优化
⑤Retiming优化
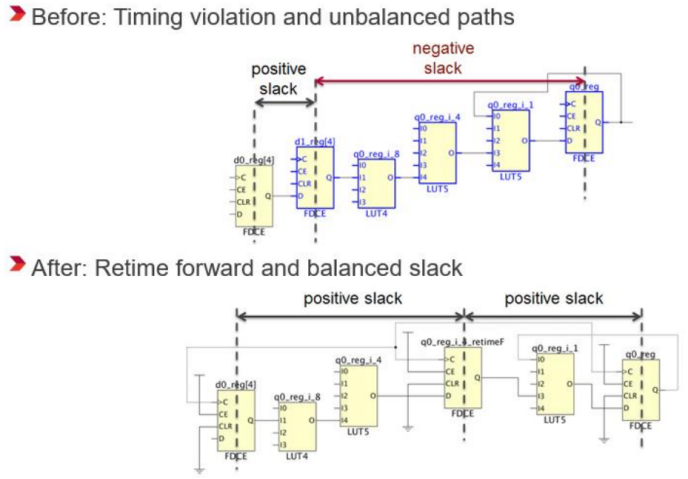
4、插入流水线寄存器(实实在在的办法)
(1)除法器IP核里增大latency,会给第一个计算结果带来延迟,但是增加了时序余量,改善了时序。
(2)组合逻辑带来延时,采用流水线打拍来改变代码,增大了latency,改善了时序。
`timescale 1ns / 1ps //************************************************************************** // *** 名称 : top_encode.v // *** 作者 : xianyu_FPGA // *** 博客 : https://www.cnblogs.com/xianyufpga/ // *** 日期 : 2020-04-12 // *** 描述 : 流水线案例,流水线优化后 //************************************************************************** module top_encode //========================< 端口 >========================================== ( //input ----------------------------------------- input wire sysclk_in , input wire pkg_valid , input wire [15:0] in_data0 , input wire [15:0] in_data1 , input wire [15:0] in_data2 , input wire [15:0] in_data3 , input wire [15:0] in_data4 , input wire [15:0] in_data5 , input wire [15:0] in_data6 , input wire [15:0] in_data7 , //output ---------------------------------------- output reg o_encode_valid , output reg [31:0] o_encode ); //========================< 信号 >========================================== //reg ------------------------------------------- reg pkg_valid_r ; reg [15:0] in_data0_r ; reg [15:0] in_data1_r ; reg [15:0] in_data2_r ; reg [15:0] in_data3_r ; reg [15:0] in_data4_r ; reg [15:0] in_data5_r ; reg [15:0] in_data6_r ; reg [15:0] in_data7_r ; //pll ------------------------------------------- wire sclk ; wire clk150 ; wire clk300 ; //no pipelined ---------------------------------- wire [15:0] code_0 ; wire [15:0] code_1 ; wire [15:0] code_2 ; wire [15:0] code_3 ; wire [15:0] code_4 ; wire [15:0] code_5 ; wire [15:0] code_6 ; wire [15:0] code_7 ; wire [31:0] code_sum ; //pipelined ------------------------------------- reg [15:0] code_0_r ; reg [15:0] code_1_r ; reg [15:0] code_2_r ; reg [15:0] code_3_r ; reg [15:0] code_4_r ; reg [15:0] code_5_r ; reg [15:0] code_6_r ; reg [15:0] code_7_r ; reg [31:0] code_sum_r ; reg pkg_valid_rr ; reg pkg_valid_rrr ; //========================================================================== //== pll //========================================================================== clk_gen clk_gen ( .clk_out1 (clk150 ), .clk_out2 (clk300 ), .clk_in1 (sysclk_in ) ); assign sclk = clk150; //========================================================================== //== no pipelined //========================================================================== always @(posedge sclk) begin pkg_valid_r <= pkg_valid; in_data0_r <= in_data0; in_data1_r <= in_data1; in_data2_r <= in_data2; in_data3_r <= in_data3; in_data4_r <= in_data4; in_data5_r <= in_data5; in_data6_r <= in_data6; in_data7_r <= in_data7; end assign code_0 = in_data0_r | in_data7_r; assign code_1 = in_data1_r | in_data6_r; assign code_2 = in_data2_r | in_data5_r; assign code_3 = in_data3_r | in_data4_r; assign code_4 = in_data0_r + in_data1_r + in_data2_r + in_data3_r; assign code_5 = in_data1_r + in_data2_r + in_data3_r + in_data4_r; assign code_6 = in_data2_r + in_data3_r + in_data4_r + in_data5_r; assign code_7 = in_data3_r + in_data4_r + in_data5_r + in_data6_r; assign code_sum = code_0 + code_1 + code_2 + code_3 + code_4 + code_5 + code_6 + code_7; always @(posedge sclk) begin o_encode_valid <= pkg_valid_r; o_encode <= code_sum; end /* //========================================================================== //== pipelined //========================================================================== //一级寄存器 always @(posedge sclk) begin code_0_r <= code_0; code_1_r <= code_1; code_2_r <= code_2; code_3_r <= code_3; code_4_r <= code_4; code_5_r <= code_5; code_6_r <= code_6; code_7_r <= code_7; end //二级寄存器 always @(posedge sclk ) begin code_sum_r <= code_0_r + code_1_r + code_2_r + code_3_r + code_4_r + code_5_r + code_6_r + code_7_r; end //========================================================================== //== 信号对齐 //========================================================================== always @(posedge sclk ) begin pkg_valid_rr <= pkg_valid_r; pkg_valid_rrr <= pkg_valid_rr; end //========================================================================== //== 输出端口 //========================================================================== always @(posedge sclk) begin o_encode_valid <= pkg_valid_rrr; o_encode <= code_sum_r; end */ endmodule
多说一点,平常写代码时:case别写太深、if else里不要嵌套 case、if 条件的条件位宽尽量窄(减少不同位之间的扇出差异)......
参考资料:V3学院FPGA教程

