tensorflow逻辑回归实例笔记
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv("C:\\Users\\94823\\Desktop\\tensorflow学习需要的数据集\\credit-a.csv",header=None)
data
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 30.83 | 0.000 | 0 | 0 | 9 | 0 | 1.25 | 0 | 0 | 1 | 1 | 0 | 202 | 0.0 | -1 |
| 1 | 1 | 58.67 | 4.460 | 0 | 0 | 8 | 1 | 3.04 | 0 | 0 | 6 | 1 | 0 | 43 | 560.0 | -1 |
| 2 | 1 | 24.50 | 0.500 | 0 | 0 | 8 | 1 | 1.50 | 0 | 1 | 0 | 1 | 0 | 280 | 824.0 | -1 |
| 3 | 0 | 27.83 | 1.540 | 0 | 0 | 9 | 0 | 3.75 | 0 | 0 | 5 | 0 | 0 | 100 | 3.0 | -1 |
| 4 | 0 | 20.17 | 5.625 | 0 | 0 | 9 | 0 | 1.71 | 0 | 1 | 0 | 1 | 2 | 120 | 0.0 | -1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 648 | 0 | 21.08 | 10.085 | 1 | 1 | 11 | 1 | 1.25 | 1 | 1 | 0 | 1 | 0 | 260 | 0.0 | 1 |
| 649 | 1 | 22.67 | 0.750 | 0 | 0 | 0 | 0 | 2.00 | 1 | 0 | 2 | 0 | 0 | 200 | 394.0 | 1 |
| 650 | 1 | 25.25 | 13.500 | 1 | 1 | 13 | 7 | 2.00 | 1 | 0 | 1 | 0 | 0 | 200 | 1.0 | 1 |
| 651 | 0 | 17.92 | 0.205 | 0 | 0 | 12 | 0 | 0.04 | 1 | 1 | 0 | 1 | 0 | 280 | 750.0 | 1 |
| 652 | 0 | 35.00 | 3.375 | 0 | 0 | 0 | 1 | 8.29 | 1 | 1 | 0 | 0 | 0 | 0 | 0.0 | 1 |
653 rows × 16 columns
data.iloc[:,-1].value_counts() # 最后一列值的统计个数
1 357
-1 296
Name: 15, dtype: int64
x = data.iloc[:,:-1]
y = data.iloc[:,-1].replace(-1,0) # 把最后一列的0替换成-1
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(4,input_shape=(15,),activation='relu'))model.add(tf.keras.layers.Dense(4,activation='relu')) # input_shape他会自己推断model.add(tf.keras.layers.Dense(1,activation='sigmoid')) # 输出层
model.summary()
Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param # =================================================================dense (Dense) (None, 4) 64 _________________________________________________________________dense_1 (Dense) (None, 4) 20 _________________________________________________________________dense_2 (Dense) (None, 1) 5 =================================================================Total params: 89Trainable params: 89Non-trainable params: 0_________________________________________________________________
model.compile(optimizer='adam', loss='binary_crossentropy', # 信息熵作为损失函数 metrics=['acc']) # 正确率
-
TP:正例预测正确的个数
FP:负例预测错误的个数
TN:负例预测正确的个数
FN:正例预测错误的个数
\(acc =\frac{TP+TN}{TP+TN+FP+FN}\)是一个评价函数
history = model.fit(x,y,epochs=100)
Epoch 95/10021/21 [==============================] - 0s 1ms/step - loss: 0.5220 - acc: 0.7458Epoch 96/10021/21 [==============================] - 0s 1ms/step - loss: 0.4917 - acc: 0.7565Epoch 97/10021/21 [==============================] - 0s 2ms/step - loss: 0.4887 - acc: 0.7580Epoch 98/10021/21 [==============================] - 0s 1ms/step - loss: 0.5376 - acc: 0.7534Epoch 99/10021/21 [==============================] - 0s 1ms/step - loss: 0.5540 - acc: 0.7427Epoch 100/10021/21 [==============================] - 0s 2ms/step - loss: 0.5571 - acc: 0.7519
history.history.keys()
dict_keys(['loss', 'acc'])
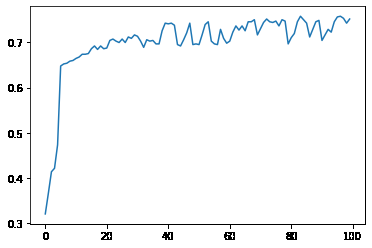
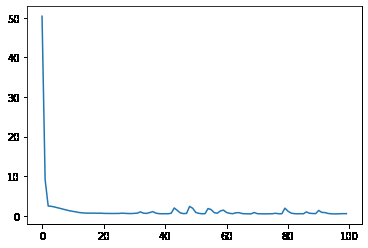
plt.plot(history.epoch,history.history.get('loss'))# 损失函数的变化
[<matplotlib.lines.Line2D at 0x2a2e4891250>]
plt.plot(history.epoch,history.history.get('acc'))# 准确率的变化
[<matplotlib.lines.Line2D at 0x2a2e4979d60>]