
day2021_10_04
今日内容
- 完成了西瓜书第16章的学习,并回顾了之前几张内容
- TSVM(针对二分类问题):
-
试图考虑对未标记样本进行各种可能的标记指派,尝试将每个未标记样本分别作为正例反例,然后对所有这些结果中,寻求一个在所有样本(包括有标记样本和进行了标记指派的未标记样本)上间隔最大化的超平面,一旦超平面得以确定,未标记样本的最终标记指派就是其预测结果。
-
给定\(D_l=\lbrace(\bf{x}\mit_1,y_1),(\bf{x}\mit_2,y_1),...,(\bf{x}\mit_l,y_l)\rbrace\)和\(D_u=\lbrace\bf{x}\mit_{l+1},\bf{x}\mit_{l+2},...,\bf{x}\mit_{l+u}\rbrace\),其中\(y_i\in\lbrace-1,+1\rbrace,l<<u,l+u=m\).TSVM的学习目标是为\(D_u\)中的样本给出的预测标记\(\bf\hat{y}\mit=(\hat{y}_{l+1},\hat{y}_{l+1},\hat{y}_{l+2},...,\hat{y}_{l+u}),\hat{y}_i\in\lbrace-1,+1\rbrace\),使得
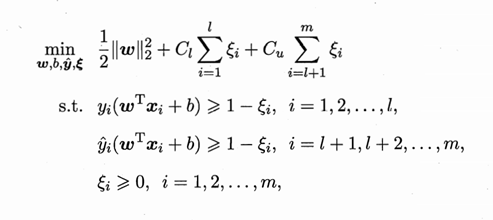
ξ为松弛因子,当\(C\)比较大时,ξ就比较小,分类要求就更严格。 -
若ξ≤1则样本落在最大间隔内部,否则分类错误
-
显然只有当未标记样本很少时才有可能直接求解。
-
TSVM先利用有标记样本学的一个SVM,利用这个SVM对未标记样本作伪标记,带入上面的公式求得新的SVM划分超平面;开始的时候伪标记样本的伪标记很可能不准确,\(C_u\)要设计的比\(C_l\)小,这样有标记的样本所起的作用更大。接下来,TSVM找到两个标记指派很可能出错的未标记样本,交换他们的标记,继续更新SVM。
-
判断标记出错:若存在一对未标记样本\(x_i\)与\(x_j\),使其标记指派的\(\hat{y}_i\)与\(\hat{y}_j\)不同,且松弛变量满足\(ξ_i+ξ_j>2\),则意味着yi与yj很有可能是错误的,需要重新交换求解公式。
-
- TSVM(针对二分类问题):
- 概率图模型中:隐马尔可夫模型、马尔科夫随机场,学习与诊断等概念的学习
- 强化学习:K-摇臂赌博机、\(\epsilon\)-贪婪、Sarsa与Q-learning算法的过程都有了解
今日难点:
- 最近几章内容牵扯的公式推导较多,很多时候我是选择略过其中的推导过程,直接看结论的,所以印象不是很深刻,我想结束这本书的第一遍阅读后,后面有时间需要对各种算法,找些例子,把代码敲出来
明日计划
- 对概率图模型以及强化学习章节的重点做个回顾
