
机器学习:样本集、验证集(开发集)、测试集
样本集、验证集(开发集)、测试集。
Ripley, B.D(1996)在他的经典专著Pattern Recognition and Neural Networks中给出了这三个词的定义。
Training set: A set of examples used for learning, which is to fit the parameters [i.e., weights] of the classifier.
Validation set: A set of examples used to tune the parameters [i.e., architecture, not weights] of a classifier, for example to choose the number of hidden units in a neural network.
Test set: A set of examples used only to assess the performance [generalization] of a fully specified classifier.
训练集:学习样本数据集,通过匹配一些参数来建立一个分类器。建立一种分类的方式,主要是用来训练模型的。
验证集:对学习出来的模型,微调分类器的参数,如在神经网络中选择隐藏单元数。验证集还用来确定网络结构或者控制模型复杂程度的参数。
测试集:主要用于测试训练好的模型的分类能力(识别率等)
在有监督(supervise learning)机器学习中,数据集常被分成2~3个部分:
训练集(train set):用来估计模型;
验证集(validation set):确定网络结构或者控制模型复杂程度的参数;
测试集(test set):检验最终选择最优的模型的性能如何。
一个典型的划分是训练集占总样本的50%,而其它各占25%,三部分都是从样本中随机抽取。样本少的时候,上面的划分就不合适了。常用的是留少部分做测试集。然后对其余N个样本采用K折交叉验证法。就是将样本打乱,然后均匀分成K份,轮流选择其中K-1份训练,剩余的一份做验证,计算预测误差平方和,最后把K次的预测误差平方和再做平均作为选择最优模型结构的依据。特别的K取N,就是留一法(leave one out)。
training set是用来训练模型或确定模型参数的,如ANN中权值等; validation set是用来做模型选择(model selection),即做模型的最终优化及确定的,如ANN的结构;而 test set则纯粹是为了测试已经训练好的模型的推广能力。当然,test set这并不能保证模型的正确性,他只是说相似的数据用此模型会得出相似的结果。但实际应用中,一般只将数据集分成两类,即training set 和test set。
1.传统的机器学习领域中,由于收集到的数据量往往不多,比较小,所以需要将收集到的数据分为三类:训练集、验证集、测试集。也有人分为两类,就是不需要测试集。
比例根据经验不同而不同,这里给出一个例子,如果是三类,可能是训练集:验证集:测试集=6:2:2;如果是两类,可能是训练集:验证集=7:3。因为数据量不多,所以验证集和测试集需要占的数据比例比较多。
2.在大数据时代的机器学习或者深度学习领域中,如果还是按照传统的数据划分方式不是十分合理,因为测试集和验证集用于评估模型和选择模型,所需要的数据量和传统的数据量差不多,但是由于收集到的数据远远大于传统机器学习时代的数据量,所以占的比例也就要缩小。比如我们拥有1000000,这么多的数据,训练集:验证集:测试集=98:1:1。如果是两类,也就是相同的道理。
小数据时代: 70%(训练集)/30%(测试集)或者60%(训练集)/20%(验证集)/20%(测试集)
大数据时代: 验证集和测试集的比例要逐渐减小,比如: 980000/10000/10000
验证集和测试集的作用
深度学习需要大量的数据,我们可能会采用网上爬取的方式获得训练集,容易出现训练集和验证集、测试集分布不一致的情况,由于验证集的目的就是为了验证不同的算法,选取效果好的。所以确保验证集和测试集的数据来自同一分布可以加快训练速度,模型在测试集上也会获得较好的效果。
测试集的目的是对最终选定的神经网络系统做出无偏评估。(测试集可以不要)
没有测试集时,验证集也会被称为测试集,但是人们是把这里的测试集当成简单交叉验证集使用。
搭建训练验证集和测试集能够加速神经网络的集成,也可以更有效地衡量算法的偏差和方差。从而帮助我们更高效地选择合适的方法来优化算法。
| 训练集误差 | 1% | 15% | 15% | 0.5% |
|---|---|---|---|---|
| 验证集误差 | 11% | 16% | 30% | 1% |
| High variance | high bias | high bias & high variance | low bias & low variance |
上述表格基于假设:最优误差(基础误差)≈0%,训练集和验证集数据来自相同分布。
训练集和测试集
机器学习模型需要训练去更新模型中的各个参数,因此需要提供训练集(Training Set)作为训练样本,假设此训练集由数据生成分布PdataPdata生成。同时为了描述这个模型的泛化能力,需要一个同样由PdataPdata生成的测试集(Test Set)进行测试,得出其泛化误差。可以得知,训练集和测试集是独立同分布的,在训练阶段,模型观测不到测试集。
检验集
超参数
在讨论检验集之前,有必要先提到超参数(hyperparameter)这个概念。超参数不能或者难以通过机器学习算法学习得出,一般由专家经过经验或者实验选定,如广义线性回归中的多项式次数,控制权值衰减的λλ等。容易想象到,不同的超参数选定控制了模型的容量和泛化能力,决定了模型的性能,事实上,超参数的调试(Tuning of the hyperparameter)是机器学习中很关键的一部分。
这里我们假想一个场景:
我们有多个待选的权值衰减因子λλ,分别是λ1,⋯,λnλ1,⋯,λn,这些λλ的不同选择代表了一个模型的不同超参数状态,其中有一个可能性能比较优的超参数,为了得到这个较为优的超参数,我们需要在多个[训练集,测试集]元组上训练测试,寻找最小的泛化误差,直到找到合适的超参数为止。
由于监督数据的获取困难,一般来说没有那么多数据用来划分这个元组,因此一般的做法是:
将数据集按一定比例划分为训练集(大类)和测试集(Test set),其中测试集只在最后的测试泛化误差的时候才能被模型观察到,而在训练集(大类)中又将其按一定比例划分为训练集(Training Set)和检验集(validation set),其中训练集用于模型训练,检验集用于寻找最佳的超参数。一般模型会在训练集上训练多次,在检验集上检验多次,直到得到满意的检验误差,然后才能交给测试集得出泛化误差。

交叉检验(Cross Validation)
在实际应用中,因为数据集的数量限制,常常采用交叉检验作为检验手段1,其中k折交叉检验(k-folds cross validation)最为常用,其中k=10k=10最为常见。其方法十分简单,就是将训练集(大类)均分为KK份,然后分别取出其中的第ii个作为检验集,其余的i−1i−1作为训练集训练,然后再检验集上检验。进行了KK次该操作之后,采用平均值作为最终的交叉验证误差(CV Error),用于选择模型。
其中LiLi是第ii检验集的平均误差
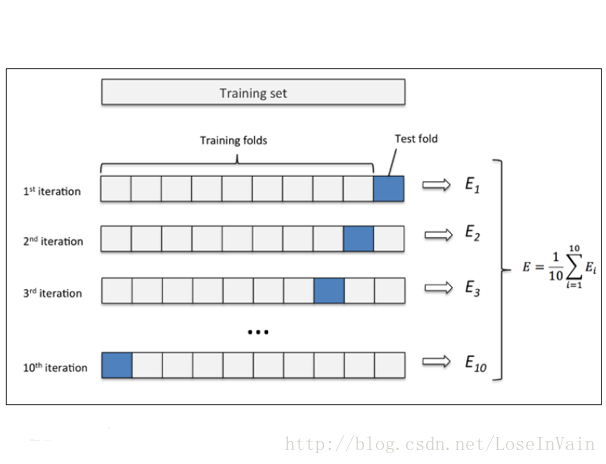
以上主要介绍了训练集,检验集,测试集之间的关系,以及引进检验集的目的:就是为了多次比较,得出较好的超参数,进行模型选择。
开发集和测试集的概念
继续分析我们之前提到的猫咪图片的案例:现在你负责运营着一个移动端 app,用户会向这个 app 上传许多不同内容的图片。而你希望这个 app 能够从图片中自动地找到有猫的图片。
你的团队已经在不同的网站下载了含有猫的图片(正样本,又译作正例),以及不含有猫的图片(负样本,又译作反例),从而得到了一个巨型的数据集。他们将数据集按照 70% / 30% 的比例划分为训练集(training set)和测试集(test set),并且使用这些数据构建出了一个在训练集和测试集上均表现良好的猫咪检测器。
可当你将这个分类器(classifier)部署到移动应用中时,却发现它的性能相当之差!
究竟是什么原因导致的呢?
你会发现,从网站上下载作为训练集的图片与用户上传的图片有较大的区别——用户上传的图片大部分是用手机拍摄的,此类型的图片往往分辨率较低,且模糊不清,采光也不够理想。由于用来进行训练和测试的数据集图片均取自网站,这就导致了算法没能够很好地泛化(generalize)到我们所关心的手机图片的实际分布(actual distribution)情况上。
在大数据时代来临前,机器学习中的普遍做法是使用 70% / 30% 的比例来随机划分出训练集和测试集。这种做法的确可行,但在越来越多的实际应用中,训练数据集的分布(例如上述案例中的网站图片)与人们最终所关心的分布情况(例如上述案例中的手机图片)往往不同,此时执意要采取这样的划分则是一个坏主意。
我们通常认为:
-
训练集(training set)用于运行你的学习算法。
-
开发集(development set)用于调整参数,选择特征,以及对学习算法作出其它决定。有时也称为留出交叉验证集(hold-out cross validation set)。
-
测试集(test set)用于评估算法的性能,但不会据此决定使用什么学习算法或参数。
在定义了开发集(development set)和测试集(test set)后,你的团队将可以尝试许多的想法,比如调整学习算法的参数来探索出哪些参数的效果最好。开发集和测试集能够帮助你的团队快速检测算法性能。
换而言之,开发集和测试集的使命就是引导你的团队对机器学习系统做出最重要的改变。
所以你应当这样处理:
合理地设置开发集和测试集,使之近似模拟可能的实际数据情况,并处理得到一个好的结果。
也就是说你的测试集不应该仅是简单地将可用的数据划分出 30%,尤其是将来获取的数据(移动端图片)在性质上可能会与训练集(网站图片)不同时。
如果你尚未推出移动端 app,那么可能还没有任何的用户,因此也无法获取一些准确的反馈数据来作为后续行动的依据。但你仍然能够尝试去模拟这种情况,例如邀请你的朋友用手机拍下照片并发送给你。当你的 app 上线后,就能够使用实际的用户数据对开发集和测试集进行更新。
如果你实在没有途径获取近似将来实际情况的数据,也可以从使用已有的网站图片开始进行尝试。但你应该意识到其中的风险,它将导致系统不能够很好地泛化(generalize)。
这就要求你主观地进行判断,应该投入多少来确定一个理想的开发集和测试集,但请不要假定你的训练集分布和测试集分布是一致的。尽可能地选出能够反映你对最终性能期望的测试样本,而不是使用那些在训练阶段已有的数据,这将避免不必要的麻烦。

