

数据库分为:关系型数据库和非关系型数据库
1、关系型数据库有:
关系模型就是指二维表格模型,因而一个关系型数据库就是由二维表及其之间的联系组成的一个数据组织。
常见的有:Oracle、DB2、PostgreSQL、Microsoft SQL Server、Microsoft Access、MySQL、浪潮K-DB 等
2、非关系型数据库
常见的有:NoSql、Cloudant、MongoDB、redis、HBase
两种数据库之间的区别:
对于关系型数据库
关系型数据库的特性
1、关系型数据库,是指采用了关系模型来组织数据的数据库;
2、关系型数据库的最大特点就是事务的一致性;
3、简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
关系型数据库的优点
1、容易理解:二维表结构是非常贴近逻辑世界一个概念,关系模型相对网状、层次等其他模型来说更容易理解;
2、使用方便:通用的SQL语言使得操作关系型数据库非常方便;
3、易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率;
4、支持SQL(结构化查询语言),可用于复杂的查询。
关系型数据库的缺点
1、为了维护一致性所付出的巨大代价就是其读写性能比较差;
2、固定的表结构;
3、高并发读写需求;
4、海量数据的高效率读写;
对于非关系型数据库
非关系型数据库的特性
1、使用键值对存储数据;
2、分布式;
3、一般不支持ACID特性;
4、非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
非关系型数据库的优点
1、无需经过sql层的解析,读写性能很高;
2、基于键值对,数据没有耦合性,容易扩展;
3、存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,而关系型数据库则只支持基础类型。
非关系型数据库的缺点
1、不提供sql支持,学习和使用成本较高;
2、无事务处理,附加功能bi和报表等支持也不好;
==========================================================
拓展知识
ACID特性
数据库中的事务(Transaction)有四个特性,分别是:原子性(Atomicity),一致性(Consistency),隔离性(lsolation),持久性(Durability)
所谓事务,它是一系列操作的序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。(执行逻辑功能的一组指令或者操作称之为事务)
详解
1. 原子性
原子性是指一个事务是一个不可再分割的工作单位,事务中的操作要么都执行,要么都不执行
例如:
A给B转账,如果B的账户操作失败,则本次交易失败,A和B的账户都不会进行修改。
2. 一致性
一致性是指在执行一个事务前和后,数据库的完整性约束没有没有被破坏。也就是说事务不能破坏数据库的完整性以及业务逻辑的一致性。
例如:
业务逻辑一致性:A给B转账,无论是否操作成功,两者的账户余额之和应该是不变的。
数据库完整性:数据库的约束关系应该是正确的,例如唯一索引,主键等。
3. 隔离性
隔离性是指多个事务并发时,每个事务应该是隔离的,一个事务不应影响其他事务的运行效果
在并发环境当中,当不同的事务访问相同的数据时,每个事务都有各自的完整的数据空间,由于并发事务所做的修改必须与并发的其他事务的修改隔离,所以事务查看数据更新时,数据所处的状态要么是另一个事务开始前的状态,要么就是另一个事务结束后的状态,不会查看到中间状态数据。
事务最复杂的问题都是由隔离性引起的,但是完全的隔离是不现实的,完全的隔离要求数据库同一时间只能执行一个事务,这样会严重影响性能。
事务并发问题
要了解事务的隔离级别,那么就要先了解事务并发会面临的问题
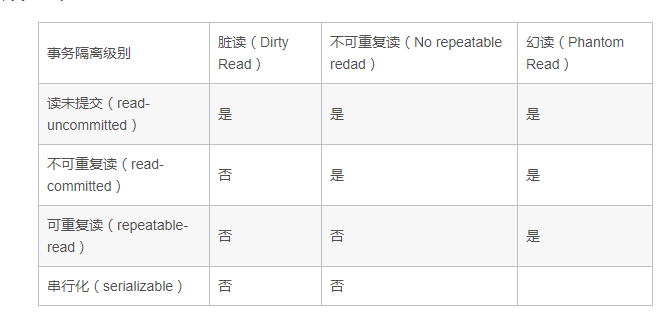
1. 脏读:事务A读取了事务B的更新的数据,但是事务B回滚了,导致A读取的为脏数据。
2. 不可重复读:事务A读取同一数据两次,但是在两次之间事务B对该数据进行了修改并提交,导致事务A读取两次读取不一致
3. 幻读:事务A修改全表的数据,在未提交时,事务B向表中插入或删除数据,导致事务A读取的数据与需要修改的数据不一致,就和幻觉一样。
注意:不可重复读和幻读很容易混淆,不可重复读针对的时数据的修改,幻读针对的时数据的新增和删除。解决不可重复读问题只需要给对应记录上行锁,而解决幻读需要对表加锁。
隔离级别
1. 未提交读(read uncommitted),就是不做隔离控制,可以读到“脏数据”,比如A和B转账,当A账户修改后,在执行B账户修改时,事务还未提交,其他事务同样需要读取A账户的数据,那么这个时候是可以读到A账户修改后数据的。但是这个时候如果处理失败,则会导致其他事务读取的A账户的数据是错误的,这个问题就叫做脏读。显然这个隔离级别没有太大意义,现实中没有人会用,除非这个应用只有读取,没有任何写入。
2. 提交读(read committed),提交读就是不允许读取事务没有提交的数据。显然这种级别可以避免了脏读问题。例如A和B转账,当A账户修改后,在执行B账户修改时,事务还未提交,其他事务同样读取A账户的数据,那么这个时候读取的应该是事务开始前的数据(也就是A账户修改前的数据)。但是当其他事务在事务开始前读取,同时在事务结束后读取,这样会造成两次读取数据不一致的情况(因为两次查询到的数据是不一样,所以这个问题叫做不可重复读)。这个隔离级别是大多数数据库(除了mysql)的默认隔离级别。
3. 可重复读(repeatable read),与提交读(不可重复读)相对应,为了避免提交读级别不可重复读的问题,在事务中对符合条件的记录上排他锁,这样其他事务不能对该事务操作的数据进行修改,可避免不可重复读的问题产生。由于只对操作数据进行上锁的操作,所以当其他事务插入或删除数据时,会出现幻读的问题,此种隔离级别为Mysql默认的隔离级别。
4. 序列化(Serializable),在事务中对表上锁,这样在事务结束前,其他事务都不能够对表数据进行操作(包括新增,删除和修改),这样避免了脏读,不可重复读和幻读,是最安全的隔离级别。但是由于该操作是堵塞的,不能够让其他事务进行操作,因此此种隔离级别性能会受到影响。
隔离级别解决事务并发问题表
4. 持久性
持久性意味着事务执行完成后,该事务对数据库的更改便持久到了数据库中,这个更改是永久的。

