

python轻松入门——爬取豆瓣Top250时出现403报错
关于爬虫程序的418+403报错。
1.按F12打开“开发者调试页面“
如下图所示:按步骤,选中Network,找到使用的接口,获取到浏览器访问的信息。
我们需要把自己的python程序,伪装成浏览器。
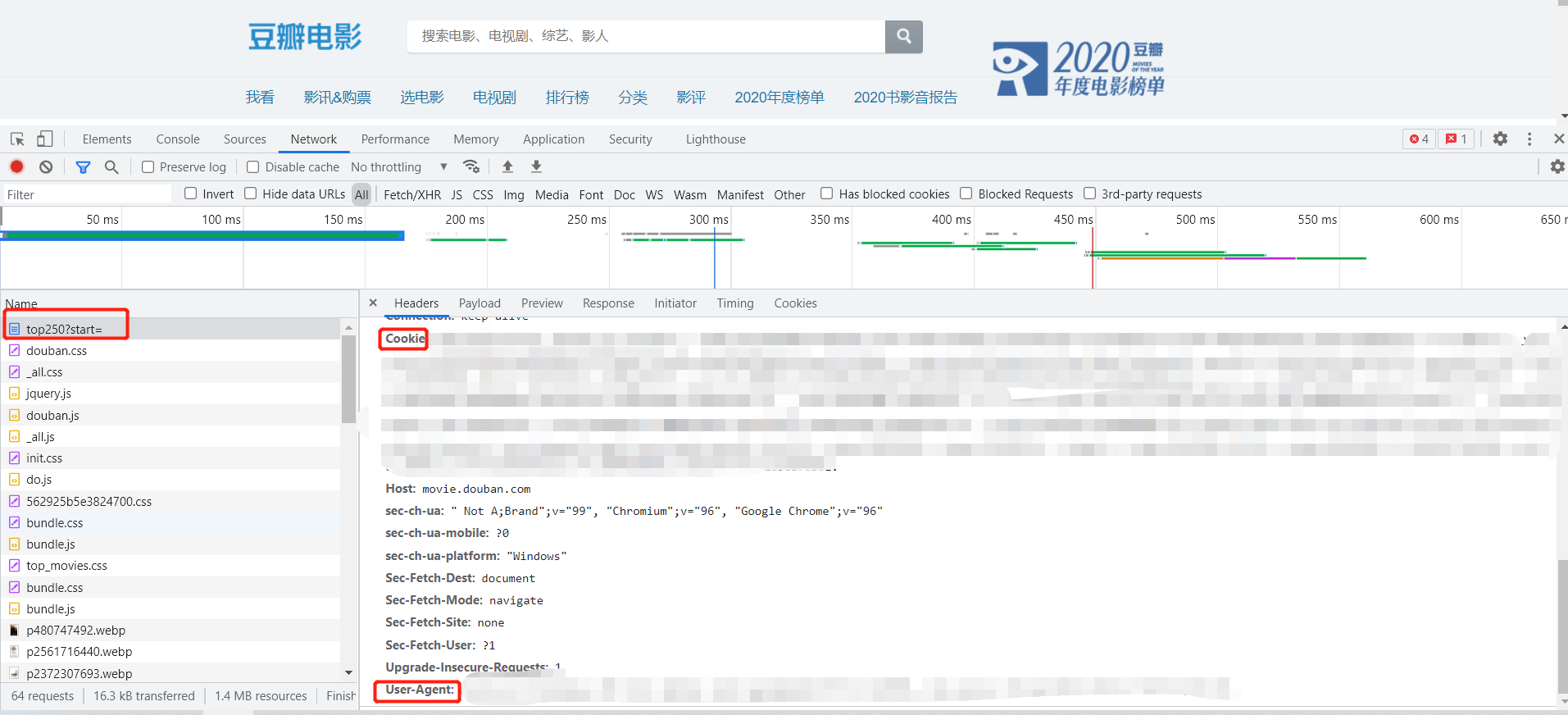
第一个user—agent
第二个就是cookie信息(简单理解就是我们的登陆信息。)
1.在head信息加入 user—agent可以模拟浏览器访问
不加此信息,会报418错误。
长期访问会有403报错。
2.在head中加入cookie信息,然后调用,(为的是模拟我们用户的登陆)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY