rust基础学习
1. 基础入门
1.1 变量绑定与解构
变量绑定
在其它语言中,我们用 var a = "hello world" 的方式给 a 赋值,也就是把等式右边的 "hello world" 字符串赋值给变量 a ,而在 Rust 中,我们这样写: let a = "hello world" ,同时给这个过程起了另一个名字:变量绑定。
变量可变性
在 rust 中,一旦为变量绑定值,就不能再修改
let x = 5
如果需要修改变量的值,也很简单,只要在变量名前加一个 mut 即可
let mut x = 5
使用下划线开头忽略未使用的变量
如果你创建了一个变量却不在任何地方使用它,rust 通常会给你一个警告,因为这可能是个 BUG。但是有时创建一个不会被使用的变量是有用的,比如你正在设计原型或刚刚开始一个项目。这时你希望告诉 Rust 不要警告未使用的变量,为此可以用下划线作为变量名的开头
fn main() {
let _x = 5;
let y = 10;
}
变量解构
let 表达式不仅仅用于变量的绑定,还能进行复杂变量的解构:从一个相对复杂的变量中,匹配出该变量的一部分内容:
fn main() {
let (a, mut b): (bool, bool) = (true, false);
println!("a = {:?}, b = {:?}", a, b);
b = true;
assert_eq!(a, b);
}
变量和常量之间的差异
-
常量不允许使用 mut。常量不仅仅默认不可变,而且自始至终不可变,因为常量在编译完成后,已经确定它的值。
-
常量使用 const 关键字而不是 let 关键字来声明,并且值的类型必须标注。
1.2 基础类型
-
数值类型: 有符号整数 (
i8,i16,i32,i64,isize)、 无符号整数 (u8,u16,u32,u64,usize) 、浮点数 (f32,f64)、以及有理数、复数 -
字符串:字符串字面量和字符串切片
&str -
布尔类型:
true和false -
字符类型: 表示单个 Unicode 字符,存储为 4 个字节
-
单元类型: 即
(),其唯一的值也是()
类型推导与标注
与 Python、JavaScript 等动态语言不同,Rust 是一门静态类型语言,也就是编译器必须在编译期知道我们所有变量的类型,但这不意味着你需要为每个变量指定类型,因为 Rust 编译器很聪明,它可以根据变量的值和上下文中的使用方式来自动推导出变量的类型,同时编译器也不够聪明,在某些情况下,它无法推导出变量类型,需要手动去给予一个类型标注。
1.2.1 数值类型
整数类型
类型定义的形式统一为:有无符号 + 类型大小(位数)。无符号数表示数字只能取正数和 0,而有符号则表示数字可以取正数、负数还有 0。就像在纸上写数字一样:当要强调符号时,数字前面可以带上正号或负号;然而,当很明显确定数字为正数时,就不需要加上正号了。有符号数字以补码形式存储。
每个有符号类型规定的数字范围是 -(2n - 1) ~ 2n - 1 - 1,其中 n 是该定义形式的位长度。因此 i8 可存储数字范围是 -(27) ~ 27 - 1,即 -128 ~ 127。无符号类型可以存储的数字范围是 0 ~ 2n - 1,所以 u8 能够存储的数字为 0 ~ 28 - 1,即 0 ~ 255。
此外,isize 和 usize 类型取决于程序运行的计算机 CPU 类型: 若 CPU 是 32 位的,则这两个类型是 32 位的,同理,若 CPU 是 64 位,那么它们则是 64 位。
整形溢出
假设有一个 u8 ,它可以存放从 0 到 255 的值。那么当你将其修改为范围之外的值,比如 256,则会发生整型溢出。关于这一行为 Rust 有一些有趣的规则:当在 debug 模式编译时,Rust 会检查整型溢出,若存在这些问题,则使程序在编译时 panic(崩溃,Rust 使用这个术语来表明程序因错误而退出)。
要显式处理可能的溢出,可以使用标准库针对原始数字类型提供的这些方法:
-
使用
wrapping_*方法在所有模式下都按照补码循环溢出规则处理,例如wrapping_add -
如果使用
checked_*方法时发生溢出,则返回None值 -
使用
overflowing_*方法返回该值和一个指示是否存在溢出的布尔值 -
使用
saturating_*方法使值达到最小值或最大值
浮点类型
浮点类型数字 是带有小数点的数字,在 Rust 中浮点类型数字也有两种基本类型: f32 和 f64,分别为 32 位和 64 位大小。默认浮点类型是 f64,在现代的 CPU 中它的速度与 f32 几乎相同,但精度更高。
NaN
对于数学上未定义的结果,例如对负数取平方根 -42.1.sqrt() ,会产生一个特殊的结果:Rust 的浮点数类型使用 NaN (not a number)来处理这些情况。
出于防御性编程的考虑,可以使用 is_nan() 等方法,可以用来判断一个数值是否是 NaN
1.2.2 字符/布尔/单元类型
字符类型(char)
可以把它理解为英文中的字母,中文中的汉字。Rust 的字符不仅仅是 ASCII,所有的 Unicode 值都可以作为 Rust 字符,包括单个的中文/韩文/emojo 表情符号等等。字符类型占用 4 个字节(Unicode 都是 4 个字节编码)
布尔(bool)
Rust 中的布尔类型有两个可能的值:true 和 false,布尔值占用内存的大小为 1 个字节。
单元类型
单元类型就是 () ,唯一的值也是 () ,fn main()函数就是返回的单元类型。
单元类型可以作为 map 的值,表示我们不关注具体的值,只关注 key。跟 go 语言中的 struct{}类似,可以作为一个值用来占位,但是完全不占用任何内存。
1.2.3 语句与表达式
fn add_with_extra(x: i32, y: i32) -> i32 {
let x = x + 1; // 语句
let y = y + 5; // 语句
x + y // 表达式
}
语句
语句会执行一些操作但是不会返回一个值。
表达式
表达式会进行求值,然后返回一个值。例如 5 + 6,在求值后,返回值 11,因此它就是一条表达式。
表达式可以成为语句的一部分,例如 let y = 6 中,6 就是一个表达式,它在求值后返回一个值 6(有些反直觉,但是确实是表达式)。
1.2.4 函数
函数要点
-
函数名和变量名使用蛇形命名法(snake case),例如
fn add_two() -> {} -
函数的位置可以随便放,Rust 不关心我们在哪里定义了函数,只要有定义即可
-
每个函数参数都需要标注类型
无返回值()
单元类型 ()是一个零长度的元组。它没啥作用,但是可以用来表达一个函数没有返回值:
-
函数没有返回值,那么返回一个
() -
通过
;结尾的表达式返回一个()
永不返回的发散函数 !
当用 ! 作函数返回类型的时候,表示该函数永不返回( diverge function ),特别的,这种语法往往用做会导致程序崩溃的函数:
fn dead_end() -> ! {
panic!("你已经到了穷途末路,崩溃吧!");
}
下面的函数创建了一个无限循环,该循环永不跳出,因此函数也永不返回:
fn forever() -> ! {
loop {
//...
};
}
1.3 所有权和借用
1.3.1 所有权
所有的程序都必须和计算机内存打交道,如何从内存中申请空间来存放程序的运行内容,如何在不需要的时候释放这些空间,成了重中之重,也是所有编程语言设计的难点之一。在计算机语言不断演变过程中,出现了三种流派:
-
垃圾回收机制(GC),在程序运行时不断寻找不再使用的内存,典型代表:Java、Go
-
手动管理内存的分配和释放, 在程序中,通过函数调用的方式来申请和释放内存,典型代表:C++
-
通过所有权来管理内存,编译器在编译时会根据一系列规则进行检查 rust
栈
栈按照顺序存储值并以相反顺序取出值,这也被称作后进先出。想象一下一叠盘子:当增加更多盘子时,把它们放在盘子堆的顶部,当需要盘子时,再从顶部拿走。不能从中间也不能从底部增加或拿走盘子!
增加数据叫做进栈,移出数据则叫做出栈。
因为上述的实现方式,栈中的所有数据都必须占用已知且固定大小的内存空间,假设数据大小是未知的,那么在取出数据时,你将无法取到你想要的数据。
堆
与栈不同,对于大小未知或者可能变化的数据,我们需要将它存储在堆上。
当向堆上放入数据时,需要请求一定大小的内存空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的指针, 该过程被称为在堆上分配内存,有时简称为 “分配”(allocating)。
接着,该指针会被推入栈中,因为指针的大小是已知且固定的,在后续使用过程中,你将通过栈中的指针,来获取数据在堆上的实际内存位置,进而访问该数据。
由上可知,堆是一种缺乏组织的数据结构。想象一下去餐馆就座吃饭: 进入餐馆,告知服务员有几个人,然后服务员找到一个够大的空桌子(堆上分配的内存空间)并领你们过去。如果有人来迟了,他们也可以通过桌号(栈上的指针)来找到你们坐在哪。
性能区别
写入方面:入栈比在堆上分配内存要快,因为入栈时操作系统无需分配新的空间,只需要将新数据放入栈顶即可。相比之下,在堆上分配内存则需要更多的工作,这是因为操作系统必须首先找到一块足够存放数据的内存空间,接着做一些记录为下一次分配做准备。
读取方面:得益于 CPU 高速缓存,使得处理器可以减少对内存的访问,高速缓存和内存的访问速度差异在 10 倍以上!栈数据往往可以直接存储在 CPU 高速缓存中,而堆数据只能存储在内存中。访问堆上的数据比访问栈上的数据慢,因为必须先访问栈再通过栈上的指针来访问内存。
所有权与堆栈
当你的代码调用一个函数时,传递给函数的参数(包括可能指向堆上数据的指针和函数的局部变量)依次被压入栈中,当函数调用结束时,这些值将被从栈中按照相反的顺序依次移除。
因为堆上的数据缺乏组织,因此跟踪这些数据何时分配和释放是非常重要的,否则堆上的数据将产生内存泄漏 —— 这些数据将永远无法被回收。这就是 Rust 所有权系统为我们提供的强大保障。
对于其他很多编程语言,你确实无需理解堆栈的原理,但是在 Rust 中,明白堆栈的原理,对于我们理解所有权的工作原理会有很大的帮助。
所有权原则
-
rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者。
-
一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者。
-
当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)。
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{} world!", s1);
}
当 s1 赋予 s2 后,Rust 认为 s1 不再有效,因此也无需在 s1 离开作用域后 drop 任何东西,这就是把所有权从 s1 转移给了 s2,s1 在被赋予 s2 后就马上失效了。
克隆(深拷贝)
首先,Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何自动的复制都不是深拷贝,可以被认为对运行时性能影响较小。
如果我们确实需要深度复制 String 中堆上的数据,而不仅仅是栈上的数据,可以使用一个叫做 clone 的方法。
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);
拷贝(浅拷贝)
浅拷贝只发生在栈上,因此性能很高,在日常编程中,浅拷贝无处不在。
Rust 有一个叫做 Copy 的特征,可以用在类似整型这样在栈中存储的类型。如果一个类型拥有 Copy 特征,一个旧的变量在被赋值给其他变量后仍然可用。
任何基本类型的组合可以 Copy ,不需要分配内存或某种形式资源的类型是可以 Copy 的。如下是一些 Copy 的类型:
-
所有整数类型,比如 u32
-
布尔类型,bool,它的值是 true 和 false
-
所有浮点数类型,比如 f64
-
字符类型,char
-
元组,当且仅当其包含的类型也都是 Copy 的时候。比如,(i32, i32) 是 Copy 的,但 (i32, String) 就不是
-
不可变引用 &T ,例如转移所有权中的最后一个例子,但是注意: 可变引用 &mut T 是不可以 Copy的
fn main() {
let s1 = gives_ownership(); // gives_ownership 将返回值
// 移给 s1
let s2 = String::from("hello"); // s2 进入作用域
let s3 = takes_and_gives_back(s2); // s2 被移动到
// takes_and_gives_back 中,
// 它也将返回值移给 s3
} // 这里, s3 移出作用域并被丢弃。s2 也移出作用域,但已被移走,
// 所以什么也不会发生。s1 移出作用域并被丢弃
fn gives_ownership() -> String { // gives_ownership 将返回值移动给
// 调用它的函数
let some_string = String::from("hello"); // some_string 进入作用域.
some_string // 返回 some_string 并移出给调用的函数
}
// takes_and_gives_back 将传入字符串并返回该值
fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域
a_string // 返回 a_string 并移出给调用的函数
}
1.3.2 引用与借用
上节中提到,如果仅仅支持通过转移所有权的方式获取一个值,那会让程序变得复杂。 Rust 能否像其它编程语言一样,使用某个变量的指针或者引用呢?答案是可以。
Rust通过 借用(Borrowing) 这个概念来达成上述目的,获取变量的引用,称之为借用(Borrowing)。
引用与解引用
常规引用是一个指针类型,指向了对象存储的内存地址。在下面代码中,我们创建一个 i32 值的引用 y,然后使用解引用运算符来解出 y 所使用的值:
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}
变量 x 存放了一个 i32 值 5。y 是 x 的一个引用。可以断言 x 等于 5。然而,如果希望对 y 的值做出断言,必须使用 *y 来解出引用所指向的值(也就是解引用)。一旦解引用了 y,就可以访问 y 所指向的整型值并可以与 5 做比较。
不可变引用
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
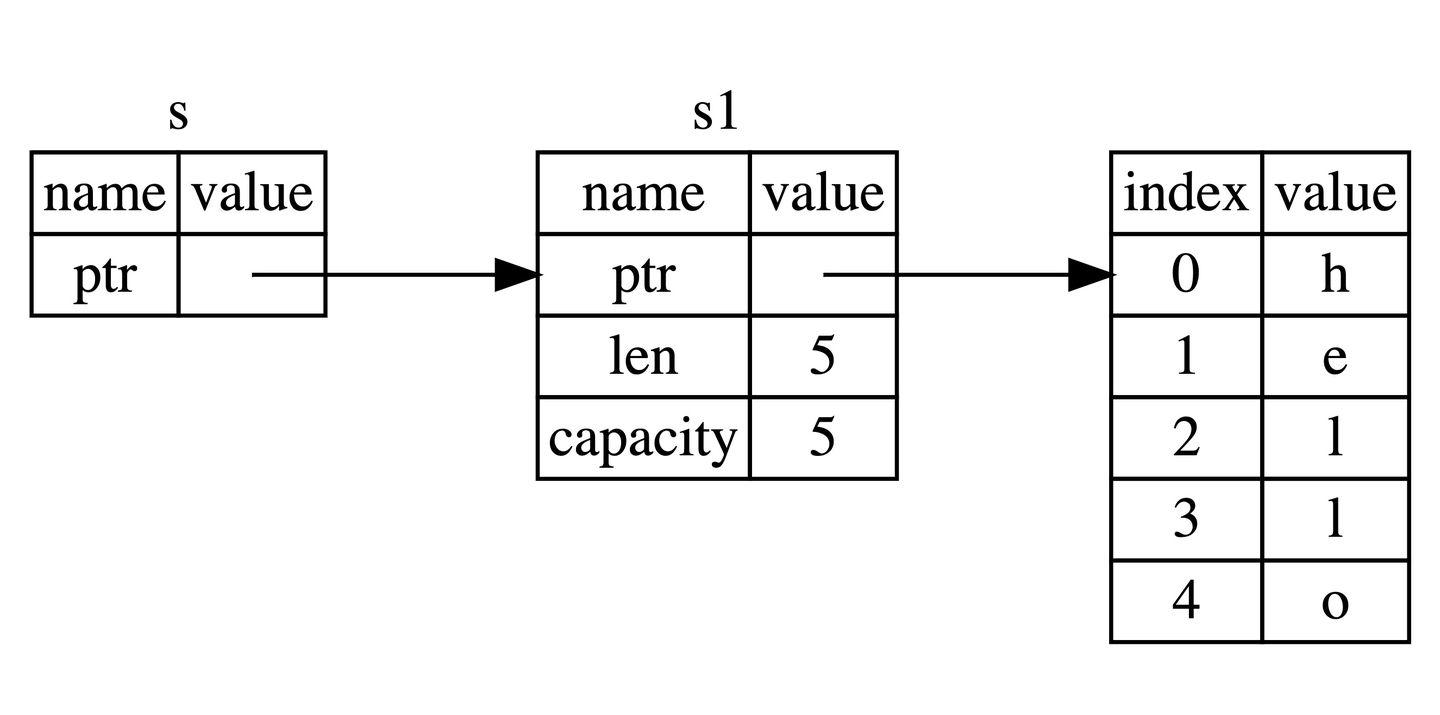
通过 &s1 语法,我们创建了一个指向 s1 的引用,但是并不拥有它。因为并不拥有这个值吗,当引用离开作用域后,其指向的值也不会被丢弃。
可变引用
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
首先,声明 s 是可变类型,其次创建一个可变的引用 &mut s 和接受可变引用参数 some_string: &mut String 的函数。
可变引用同时只能存在一个
不过可变引用并不是随心所欲、想用就用的,它有一个很大的限制: 同一作用域,特定数据只能有一个可变引用:
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
以上代码会报错:
error[E0499]: cannot borrow `s` as mutable more than once at a time 同一时间无法对 `s` 进行两次可变借用
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here 首个可变引用在这里借用
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here 第二个可变引用在这里借用
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here 第一个借用在这里使用
这段代码出错的原因在于,第一个可变借用 r1 必须要持续到最后一次使用的位置 println!,在 r1 创建和最后一次使用之间,我们又尝试创建第二个可变借用 r2。
这种限制的好处就是使 Rust 在编译期就避免数据竞争,数据竞争可由以下行为造成:
-
两个或更多的指针同时访问同一数据
-
至少有一个指针被用来写入数据
-
没有同步数据访问的机制
可变引用与不可变引用不能同时存在
正在借用不可变引用的用户,肯定不希望他借用的东西,被另外一个人莫名其妙改变了。多个不可变借用被允许是因为没有人会去试图修改数据,每个人都只读这一份数据而不做修改,因此不用担心数据被污染。
注意,引用的作用域 s 从创建开始,一直持续到它最后一次使用的地方,这个跟变量的作用域有所不同,变量的作用域从创建持续到某一个花括号 }
NLL
对于这种编译器优化行为,Rust 专门起了一个名字 —— Non-Lexical Lifetimes(NLL),专门用于找到某个引用在作用域(})结束前就不再被使用的代码位置。
悬垂引用(Dangling References)
悬垂引用也叫做悬垂指针,意思为指针指向某个值后,这个值被释放掉了,而指针仍然存在,其指向的内存可能不存在任何值或已被其它变量重新使用。在 Rust 中编译器可以确保引用永远也不会变成悬垂状态:当你获取数据的引用后,编译器可以确保数据不会在引用结束前被释放,要想释放数据,必须先停止其引用的使用。
1.4 复合类型
1.4.1 字符串与切片
Rust 中的字符是 Unicode 类型,因此每个字符占据 4 个字节内存空间,但是在字符串中不一样,字符串是 UTF-8 编码,也就是字符串中的字符所占的字节数是变化的(1 - 4),这样有助于大幅降低字符串所占用的内存空间。
Rust 在语言级别,只有一种字符串类型: str,它通常是以引用类型出现 &str,也就是字符串切片。虽然语言级别只有上述的 str 类型,但是在标准库里,还有多种不同用途的字符串类型,其中使用最广的即是 String 类型。
String与&str的转换
从 &str 类型生产 String 类型:
-
String::from("hello world")
-
"hello world".to_string()
String 转为 &str: 取引用即可
字符串索引
在其它语言中,使用索引的方式访问字符串的某个字符或者子串是很正常的行为,但是在 Rust 中就会报错
字符串切片
字符串切片是非常危险的操作,因为切片的索引是通过字节来进行,但是字符串又是 UTF-8 编码,因此你无法保证索引的字节刚好落在字符的边界上,例如:
let hello = "中国人";
let s = &hello[0..2];
中占三个字节,此时运行上面的程序,会直接造成崩溃
操作字符串
追加(Push)
在字符串尾部可以使用 push() 方法追加字符 char,也可以使用 push_str() 方法追加字符串字面量。这两个方法都是在原有的字符串上追加,并不会返回新的字符串。由于字符串追加操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
插入 (Insert)
可以使用 insert() 方法插入单个字符 char,也可以使用 insert_str() 方法插入字符串字面量,与 push() 方法不同,这俩方法需要传入两个参数,第一个参数是字符(串)插入位置的索引,第二个参数是要插入的字符(串),索引从 0 开始计数,如果越界则会发生错误。由于字符串插入操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
替换 (Replace)
- replace
该方法可适用于 String 和 &str 类型。replace() 方法接收两个参数,第一个参数是要被替换的字符串,第二个参数是新的字符串。该方法会替换所有匹配到的字符串。该方法是返回一个新的字符串,而不是操作原来的字符串。
- replacen
该方法可适用于 String 和 &str 类型。replacen() 方法接收三个参数,前两个参数与 replace() 方法一样,第三个参数则表示替换的个数。该方法是返回一个新的字符串,而不是操作原来的字符串。
- replace_range
该方法仅适用于 String 类型。replace_range 接收两个参数,第一个参数是要替换字符串的范围(Range),第二个参数是新的字符串。该方法是直接操作原来的字符串,不会返回新的字符串。该方法需要使用 mut 关键字修饰。
删除 (Delete)
- pop —— 删除并返回字符串的最后一个字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是一个 Option 类型,如果字符串为空,则返回 None
- remove —— 删除并返回字符串中指定位置的字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是删除位置的字符串,只接收一个参数,表示该字符起始索引位置。remove() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
- truncate —— 删除字符串中从指定位置开始到结尾的全部字符
该方法是直接操作原来的字符串。无返回值。该方法 truncate() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
- clear —— 清空字符串
该方法是直接操作原来的字符串。调用后,删除字符串中的所有字符,相当于 truncate() 方法参数为 0 的时候。
连接 (Concatenate)
- 使用 + 或者 += 连接字符串
使用 + 或者 += 连接字符串,要求右边的参数必须为字符串的切片引用(Slice)类型。其实当调用 + 的操作符时,相当于调用了 std::string 标准库中的 add() 方法,这里 add() 方法的第二个参数是一个引用的类型。因此我们在使用 +, 必须传递切片引用类型。不能直接传递 String 类型。+ 是返回一个新的字符串,所以变量声明可以不需要 mut 关键字修饰。
- 使用 format! 连接字符串
format! 这种方式适用于 String 和 &str 。format! 的用法与 print! 的用法类似,详见格式化输出。
1.4.2 元组
元组是由多种类型组合到一起形成的,因此它是复合类型,元组的长度是固定的,元组中元素的顺序也是固定的。
1.4.3 结构体
上一节中提到需要一个更高级的数据结构来帮助我们更好的抽象问题,结构体 struct 恰恰就是这样的复合数据结构,它是由其它数据类型组合而来。 其它语言也有类似的数据结构,不过可能有不同的名称,例如 object、 record 等。
结构体语法
一个结构体有几部分组成:
-
通过关键字 struct 定义
-
一个清晰明确的结构体名称
-
几个有名字的结构体字段
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
该结构体名称是 User,拥有 4 个字段,且每个字段都有对应的字段名及类型声明,例如 username 代表了用户名,是一个可变的 String 类型。
创建结构体实例
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
有几点值得注意:
-
初始化实例时,每个字段都需要进行初始化
-
初始化时的字段顺序不需要和结构体定义时的顺序一致
访问结构体字段
通过 . 操作符即可访问结构体实例内部的字段值
需要注意的是,必须要将结构体实例声明为可变的,才能修改其中的字段,Rust 不支持将某个结构体某个字段标记为可变。
简化结构体创建
fn build_user(email: String, username: String) -> User {
User {
email,
username,
active: true,
sign_in_count: 1,
}
}
结构体更新语法
let user2 = User {
email: String::from("another@example.com"),
..user1
};
.. 语法表明凡是我们没有显式声明的字段,全部从 user1 中自动获取。需要注意的是 ..user1 必须在结构体的尾部使用。
元组结构体(Tuple Struct)
结构体必须要有名称,但是结构体的字段可以没有名称,这种结构体长得很像元组,因此被称为元组结构体,例如:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
单元结构体(Unit-like Struct)
如果你定义一个类型,但是不关心该类型的内容, 只关心它的行为时,就可以使用 单元结构体:
struct AlwaysEqual;
let subject = AlwaysEqual;
// 我们不关心 AlwaysEqual 的字段数据,只关心它的行为,因此将它声明为单元结构体,然后再为它实现某个特征
impl SomeTrait for AlwaysEqual {
}
1.4.4 枚举
枚举(enum 或 enumeration)允许你通过列举可能的成员来定义一个枚举类型,例如扑克牌花色:
enum PokerSuit {
Clubs,
Spades,
Diamonds,
Hearts,
}
枚举类型,它会包含所有可能的枚举成员,而枚举值是该类型中的具体某个成员的实例。
通过结构体 PokerCard 来代表一张牌,结构体的 suit 字段表示牌的花色,类型是 PokerSuit 枚举类型,value 字段代表扑克牌的数值。
enum PokerCard {
Clubs(u8),
Spades(u8),
Diamonds(char),
Hearts(char),
}
fn main() {
let c1 = PokerCard::Spades(5);
let c2 = PokerCard::Diamonds(13);
}
从这些例子可以看出,任何类型的数据都可以放入枚举成员中: 例如字符串、数值、结构体甚至另一个枚举。
Option 枚举用于处理空值
在其它编程语言中,往往都有一个 null 关键字,该关键字用于表明一个变量当前的值为空(不是零值,例如整型的零值是 0),也就是不存在值。当你对这些 null 进行操作时,例如调用一个方法,就会直接抛出null 异常,导致程序的崩溃,因此我们在编程时需要格外的小心去处理这些 null 空值。
尽管如此,空值的表达依然非常有意义,因为空值表示当前时刻变量的值是缺失的。有鉴于此,Rust 吸取了众多教训,决定抛弃 null,而改为使用 Option 枚举变量来表述这种结果。
Option 枚举包含两个成员,一个成员表示含有值:Some(T), 另一个表示没有值:None,定义如下:
enum Option<T> {
Some(T),
None,
}
其中 T 是泛型参数,Some(T)表示该枚举成员的数据类型是 T,换句话说,Some 可以包含任何类型的数据。
Option
let some_number = Some(5);
let some_string = Some("a string");
let absent_number: Option<i32> = None;
如果使用 None 而不是 Some,需要告诉 Rust Option
1.4.5数组
在日常开发中,使用最广的数据结构之一就是数组,在 Rust 中,最常用的数组有两种,第一种是速度很快但是长度固定的 array,第二种是可动态增长的但是有性能损耗的 Vector,在本书中,我们称 array 为数组,Vector 为动态数组。
对于本章节,我们的重点还是放在数组 array 上。数组的具体定义很简单:将多个类型相同的元素依次组合在一起,就是一个数组。结合上面的内容,可以得出数组的三要素:
-
长度固定
-
元素必须有相同的类型
-
依次线性排列
创建数组
let a = [1, 2, 3, 4, 5];
let a: [i32; 5] = [1, 2, 3, 4, 5];
let a = [3; 5]; // 某个值重复出现 N 次的数组
数组元素为非基础类型
let array = [String::from("rust is good!"),String::from("rust is good!"),String::from("rust is good!")];
println!("{:#?}", array);
let array: [String; 8] = std::array::from_fn(|_i| String::from("rust is good!"));
println!("{:#?}", array);
数组切片
let a: [i32; 5] = [1, 2, 3, 4, 5];
let slice: &[i32] = &a[1..3];
上面的数组切片 slice 的类型是&[i32],与之对比,数组的类型是[i32;5],简单总结下切片的特点:
-
切片的长度可以与数组不同,并不是固定的,而是取决于你使用时指定的起始和结束位置
-
创建切片的代价非常小,因为切片只是针对底层数组的一个引用
-
切片类型[T]拥有不固定的大小,而切片引用类型&[T]则具有固定的大小,因为 Rust 很多时候都需要固定大小数据类型,因此&[T]更有用,&str字符串切片也同理
1.5 控制流程
使用 if 来做分支控制
fn main() {
let condition = true;
let number = if condition {
5
} else {
6
};
println!("The value of number is: {}", number);
}
-
if 语句块是表达式,这里我们使用 if 表达式的返回值来给 number 进行赋值:number 的值是 5
-
用 if 来赋值时,要保证每个分支返回的类型一样,此处返回的 5 和 6 就是同一个类型,如果返回类型不一致就会报错
循环控制
在 Rust 语言中有三种循环方式:for、while 和 loop,其中 for 循环是 Rust 循环王冠上的明珠。
for 循环
for 元素 in 集合 {
// 使用元素干一些你懂我不懂的事情
}
for item in &container {
// 注意,使用 for 时我们往往使用集合的引用形式,除非你不想在后面的代码中继续使用该集合(比如我们这里使用了 container 的引用)。如果不使用引用的话,所有权会被转移(move)到 for 语句块中,后面就无法再使用这个集合了):
// 对于实现了 copy 特征的数组(例如 [i32; 10] )而言, for item in arr 并不会把 arr 的所有权转移,而是直接对其进行了拷贝,因此循环之后仍然可以使用 arr 。
}
// 如果想在循环中,修改该元素,可以使用 mut 关键字:
for item in &mut collection {
// ...
}
loop 循环
对于循环而言,loop 循环毋庸置疑,是适用面最高的,它可以适用于所有循环场景(虽然能用,但是在很多场景下, for 和 while 才是最优选择),因为 loop 就是一个简单的无限循环,你可以在内部实现逻辑通过 break 关键字来控制循环何时结束。
这里有几点值得注意:
-
break 可以单独使用,也可以带一个返回值,有些类似 return
-
loop 是一个表达式,因此可以返回一个值
1.6 模式匹配
1.6.1 match 和 if let
match 匹配
enum Direction {
East,
West,
North,
South,
}
fn main() {
let dire = Direction::South;
match dire {
Direction::East => println!("East"),
Direction::North | Direction::South => {
println!("South or North");
},
_ => println!("West"),
};
}
这里我们想去匹配 dire 对应的枚举类型,因此在 match 中用三个匹配分支来完全覆盖枚举变量 Direction 的所有成员类型,有以下几点值得注意:
-
match 的匹配必须要穷举出所有可能,因此这里用 _ 来代表未列出的所有可能性
-
match 的每一个分支都必须是一个表达式,且所有分支的表达式最终返回值的类型必须相同
-
X | Y,类似逻辑运算符 或,代表该分支可以匹配 X 也可以匹配 Y,只要满足一个即可
其实 match 跟其他语言中的 switch 非常像,_ 类似于 switch 中的 default。
match 的通用形式:
match target {
模式1 => 表达式1,
模式2 => {
语句1;
语句2;
表达式2
},
_ => 表达式3
}
match 本身也是一个表达式,因此可以用它来赋值:
enum IpAddr {
Ipv4,
Ipv6
}
fn main() {
let ip1 = IpAddr::Ipv6;
let ip_str = match ip1 {
IpAddr::Ipv4 => "127.0.0.1",
_ => "::1",
};
println!("{}", ip_str);
}
模式绑定
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState), // 25美分硬币
}
其中 Coin::Quarter 成员还存放了一个值:美国的某个州(因为在 1999 年到 2008 年间,美国在 25 美分(Quarter)硬币的背后为 50 个州印刷了不同的标记,其它硬币都没有这样的设计)。
接下来,我们希望在模式匹配中,获取到 25 美分硬币上刻印的州的名称:
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter(state) => {
println!("State quarter from {:?}!", state);
25
},
}
}
上面代码中,在匹配 Coin::Quarter(state) 模式时,我们把它内部存储的值绑定到了 state 变量上,因此 state 变量就是对应的 UsState 枚举类型。
例如有一个印了阿拉斯加州标记的 25 分硬币:Coin::Quarter(UsState::Alaska), 它在匹配时,state 变量将被绑定 UsState::Alaska 的枚举值。
if let 匹配
if let Some(3) = v {
println!("three");
}
这两种匹配对于新手来说,可能有些难以抉择,但是只要记住一点就好:当你只要匹配一个条件,且忽略其他条件时就用 if let ,否则都用 match。
matches!宏
Rust 标准库中提供了一个非常实用的宏:matches!,它可以将一个表达式跟模式进行匹配,然后返回匹配的结果 true or false。
let foo = 'f';
assert!(matches!(foo, 'A'..='Z' | 'a'..='z'));
let bar = Some(4);
assert!(matches!(bar, Some(x) if x > 2));
变量遮蔽
无论是 match 还是 if let,这里都是一个新的代码块,而且这里的绑定相当于新变量,如果你使用同名变量,会发生变量遮蔽:
fn main() {
let age = Some(30);
println!("在匹配前,age是{:?}",age);
if let Some(age) = age {
println!("匹配出来的age是{}",age);
}
println!("在匹配后,age是{:?}",age);
}
cargo run 运行后输出如下:
在匹配前,age是Some(30)
匹配出来的age是30
在匹配后,age是Some(30)
可以看出在 if let 中,= 右边 Some(i32) 类型的 age 被左边 i32 类型的新 age 遮蔽了,该遮蔽一直持续到 if let 语句块的结束。因此第三个 println! 输出的 age 依然是 Some(i32) 类型。
1.7 方法 Method
定义方法
Rust 使用 impl 来定义方法,例如以下代码:
struct Circle {
x: f64,
y: f64,
radius: f64,
}
impl Circle {
// new是Circle的关联函数,因为它的第一个参数不是self,且new并不是关键字
// 这种方法往往用于初始化当前结构体的实例
fn new(x: f64, y: f64, radius: f64) -> Circle {
Circle {
x: x,
y: y,
radius: radius,
}
}
// Circle的方法,&self表示借用当前的Circle结构体
fn area(&self) -> f64 {
std::f64::consts::PI * (self.radius * self.radius)
}
}
self、&self 和 &mut self
&self 其实是 self: &Self 的简写(注意大小写)。在一个 impl 块内,Self 指代被实现方法的结构体类型,self 指代此类型的实例,这样的写法会让我们的代码简洁很多,而且非常便于理解:我们为哪个结构体实现方法,那么 self 就是指代哪个结构体的实例。
需要注意的是,self 依然有所有权的概念:
-
self 表示 Rectangle 的所有权转移到该方法中,这种形式用的较少
-
&self 表示该方法对 Rectangle 的不可变借用
-
&mut self 表示可变借用
简单总结下,使用方法代替函数有以下好处:
-
不用在函数签名中重复书写 self 对应的类型
-
代码的组织性和内聚性更强,对于代码维护和阅读来说,好处巨大
关联函数
现在大家可以思考一个问题,如何为一个结构体定义一个构造器方法?也就是接受几个参数,然后构造并返回该结构体的实例。其实答案在开头的代码片段中就给出了,很简单,参数中不包含 self 即可。
这种定义在 impl 中且没有 self 的函数被称之为关联函数: 因为它没有 self,不能用 f.read() 的形式调用,因此它是一个函数而不是方法,它又在 impl 中,与结构体紧密关联,因此称为关联函数。
Rust 中有一个约定俗成的规则,使用 new 来作为构造器的名称,出于设计上的考虑,Rust 特地没有用 new 作为关键字。
多个 impl 定义
Rust 允许我们为一个结构体定义多个 impl 块,目的是提供更多的灵活性和代码组织性,例如当方法多了后,可以把相关的方法组织在同一个 impl 块中,那么就可以形成多个 impl 块,各自完成一块儿目标
为枚举实现方法
枚举类型之所以强大,不仅仅在于它好用、可以同一化类型,还在于,我们可以像结构体一样,为枚举实现方法:
#![allow(unused)]
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
impl Message {
fn call(&self) {
// 在这里定义方法体
}
}
fn main() {
let m = Message::Write(String::from("hello"));
m.call();
}
1.8 泛型和特征
1.8.1 泛型(Generics)
实际上,泛型就是一种多态。泛型主要目的是为程序员提供编程的便利,减少代码的臃肿,同时可以极大地丰富语言本身的表达能力,为程序员提供了一个合适的炮管。想想,一个函数,可以代替几十个,甚至数百个函数,是一件多么让人兴奋的事情:
fn add<T>(a:T, b:T) -> T {
a + b
}
fn main() {
println!("add i8: {}", add(2i8, 3i8));
println!("add i32: {}", add(20, 30));
println!("add f64: {}", add(1.23, 1.23));
}
泛型详解
上面代码的 T 就是泛型参数,实际上在 Rust 中,泛型参数的名称你可以任意起,但是出于惯例,我们都用 T ( T 是 type 的首字母)来作为首选,这个名称越短越好,除非需要表达含义,否则一个字母是最完美的。
使用泛型参数,有一个先决条件,必需在使用前对其进行声明:
fn largest<T>(list: &[T]) -> T {
该泛型函数的作用是从列表中找出最大的值,其中列表中的元素类型为 T。首先 largest
总之,我们可以这样理解这个函数定义:函数 largest 有泛型类型 T,它有个参数 list,其类型是元素为 T 的数组切片,最后,该函数返回值的类型也是 T。
结构体中使用泛型
结构体中的字段类型也可以用泛型来定义,下面代码定义了一个坐标点 Point,它可以存放任何类型的坐标值:
struct Point<T> {
x: T,
y: T,
}
fn main() {
let integer = Point { x: 5, y: 10 };
let float = Point { x: 1.0, y: 4.0 };
}
这里有两点需要特别的注意:
-
提前声明,跟泛型函数定义类似,首先我们在使用泛型参数之前必需要进行声明 Point
,接着就可以在结构体的字段类型中使用 T 来替代具体的类型 -
x 和 y 是相同的类型
枚举中使用泛型
提到枚举类型,Option 永远是第一个应该被想起来的,在之前的章节中,它也多次出现:
enum Option<T> {
Some(T),
None,
}
Option
对于枚举而言,卧龙凤雏永远是绕不过去的存在:如果是 Option 是卧龙,那么 Result 就一定是凤雏,得两者可得天下:
enum Result<T, E> {
Ok(T),
Err(E),
}
这个枚举和 Option 一样,主要用于函数返回值,与 Option 用于值的存在与否不同,Result 关注的主要是值的正确性。
如果函数正常运行,则最后返回一个 Ok(T),T 是函数具体的返回值类型,如果函数异常运行,则返回一个 Err(E),E 是错误类型。例如打开一个文件:如果成功打开文件,则返回 Ok(std::fs::File),因此 T 对应的是 std::fs::File 类型;而当打开文件时出现问题时,返回 Err(std::io::Error),E 对应的就是 std::io::Error 类型。
方法中使用泛型
使用泛型参数前,依然需要提前声明:impl
struct Point<T, U> {
x: T,
y: U,
}
impl<T, U> Point<T, U> {
fn mixup<V, W>(self, other: Point<V, W>) -> Point<T, W> {
Point {
x: self.x,
y: other.y,
}
}
}
fn main() {
let p1 = Point { x: 5, y: 10.4 };
let p2 = Point { x: "Hello", y: 'c'};
let p3 = p1.mixup(p2);
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}
这个例子中,T,U 是定义在结构体 Point 上的泛型参数,V,W 是单独定义在方法 mixup 上的泛型参数,它们并不冲突,说白了,你可以理解为,一个是结构体泛型,一个是函数泛型。
const 泛型(Rust 1.51 版本引入的重要特性)
在之前的泛型中,可以抽象为一句话:针对类型实现的泛型,所有的泛型都是为了抽象不同的类型,那有没有针对值的泛型?
fn display_array<T: std::fmt::Debug, const N: usize>(arr: [T; N]) {
println!("{:?}", arr);
}
fn main() {
let arr: [i32; 3] = [1, 2, 3];
display_array(arr);
let arr: [i32; 2] = [1, 2];
display_array(arr);
}
如上所示,我们定义了一个类型为 [T; N] 的数组,其中 T 是一个基于类型的泛型参数,这个和之前讲的泛型没有区别,而重点在于 N 这个泛型参数,它是一个基于值的泛型参数!因为它用来替代的是数组的长度。
N 就是 const 泛型,定义的语法是 const N: usize,表示 const 泛型 N ,它基于的值类型是 usize。
在泛型参数之前,Rust 完全不适合复杂矩阵的运算,自从有了 const 泛型,一切即将改变。
1.8.2 特征 Trait
定义特征
pub trait Summary {
fn summarize(&self) -> String;
}
这里使用 trait 关键字来声明一个特征,Summary 是特征名。在大括号中定义了该特征的所有方法,在这个例子中是: fn summarize(&self) -> String。
特征只定义行为看起来是什么样的,而不定义行为具体是怎么样的。因此,我们只定义特征方法的签名,而不进行实现,此时方法签名结尾是 ;,而不是一个 {}。
为类型实现特征
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct Post {
pub title: String, // 标题
pub author: String, // 作者
pub content: String, // 内容
}
impl Summary for Post {
fn summarize(&self) -> String {
format!("文章{}, 作者是{}", self.title, self.author)
}
}
pub struct Weibo {
pub username: String,
pub content: String
}
impl Summary for Weibo {
fn summarize(&self) -> String {
format!("{}发表了微博{}", self.username, self.content)
}
}
实现特征的语法与为结构体、枚举实现方法很像:impl Summary for Post,读作“为 Post 类型实现 Summary 特征”,然后在 impl 的花括号中实现该特征的具体方法。
特征定义与实现的位置(孤儿规则)
关于特征实现与定义的位置,有一条非常重要的原则:如果你想要为类型 A 实现特征 T,那么 A 或者 T 至少有一个是在当前作用域中定义的! 例如我们可以为上面的 Post 类型实现标准库中的 Display 特征,这是因为 Post 类型定义在当前的作用域中。同时,我们也可以在当前包中为 String 类型实现 Summary 特征,因为 Summary 定义在当前作用域中。
但是你无法在当前作用域中,为 String 类型实现 Display 特征,因为它们俩都定义在标准库中,其定义所在的位置都不在当前作用域,跟你半毛钱关系都没有,看看就行了。
该规则被称为孤儿规则,可以确保其它人编写的代码不会破坏你的代码,也确保了你不会莫名其妙就破坏了风马牛不相及的代码。
默认实现
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
特征约束(trait bound)
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}
真正的完整书写形式如上所述,形如 T: Summary 被称为特征约束。
在简单的场景下 impl Trait 这种语法糖就足够使用,但是对于复杂的场景,特征约束可以让我们拥有更大的灵活性和语法表现能力,例如一个函数接受两个 impl Summary 的参数:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {}
如果函数两个参数是不同的类型,那么上面的方法很好,只要这两个类型都实现了 Summary 特征即可。但是如果我们想要强制函数的两个参数是同一类型呢?上面的语法就无法做到这种限制,此时我们只能
使特征约束来实现:
pub fn notify<T: Summary>(item1: &T, item2: &T) {}
泛型类型 T 说明了 item1 和 item2 必须拥有同样的类型,同时 T: Summary 说明了 T 必须实现 Summary 特征。
多重约束
除了单个约束条件,我们还可以指定多个约束条件,例如除了让参数实现 Summary 特征外,还可以让参数实现 Display 特征以控制它的格式化输出:
pub fn notify<T: Summary + Display>(item: &T) {}
Where 约束
fn some_function<T, U>(t: &T, u: &U) -> i32
where T: Display + Clone,
U: Clone + Debug
{}
函数返回中的 impl Trait
fn returns_summarizable() -> impl Summary {
Weibo {
username: String::from("sunface"),
content: String::from(
"m1 max太厉害了,电脑再也不会卡",
)
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号