k8s——了解kubernetes机理
1.了解架构
K8S分为两部分:
Kubernetes控制平面
(工作)节点
控制平面组件:
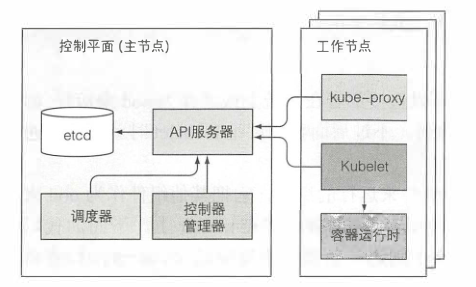
控制平面负责控制并使得整个集群正常运转,其中包括:etcd分布式持久化存储、API服务器、调度器、控制器管理器。
工作节点上运行的组件:
运行容器的任务依赖于每个工作节点上运行的组件:Kubelet、Kubelet服务代理(kube-proxy)、容器运行时(docker、rkt或其他)
附加组件:
Kubernetes DNS服务器、仪表板、Ingress控制器、Heapster、容器网络接口插件
1.1 k8s组件的分布式特性
显示每个控制平面组件的健康状态:kubectl get componentstatuses
组件间如何通信
k8s系统组件间只能通过API服务器通信,它们之间不会直接通信。API服务器是和etcd通信的唯一组件。其他组件不会直接和etcd通信,而是通过API服务器来修改集群状态。API服务器和其他组件的连接基本都是由组件发起的。
单组件运行多实例
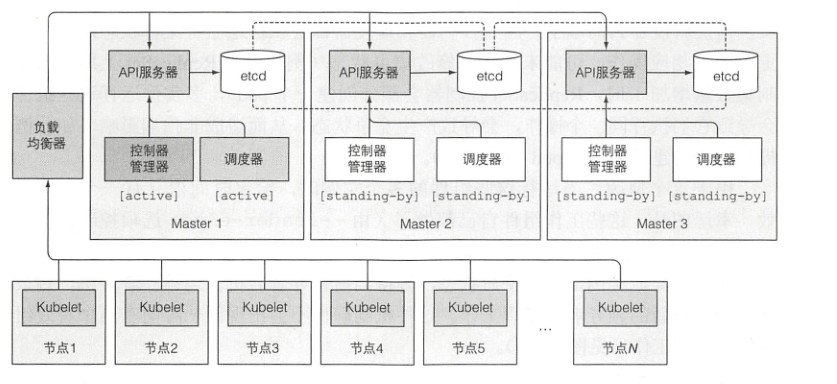
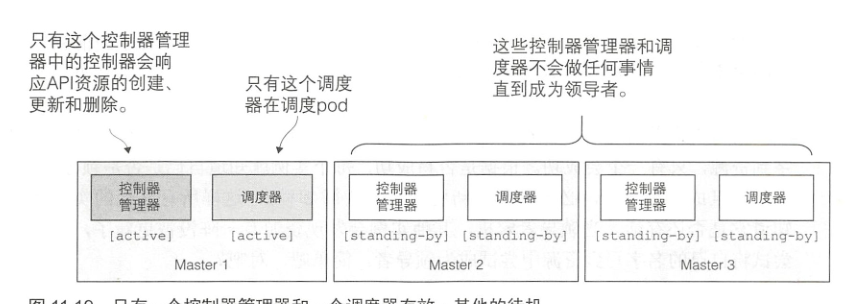
尽管工作节点上的组件都需要运行在同一个节点上,控制平面的组件可以被简单地分割在多台服务器上。为了保证高可用性,控制平面的每个组件可以有多个实例。etcd和API服务器的多个实例可以同时并行工作,但是,调度器和控制器管理器在给定时间内只能有一个实例起作用,其他实例处于待命模式。
组件是如何运行的
控制平面的组件以及kube-proxy可以直接部署在系统上或者作为pod来运行。kebulet是唯一一个作为常规系统组件来运行的组件,它把其他组件作为pod来运行。
1.2 Kubernetes如何使用etcd
资源如何存储在etcd中

1.3 API服务器做了什么
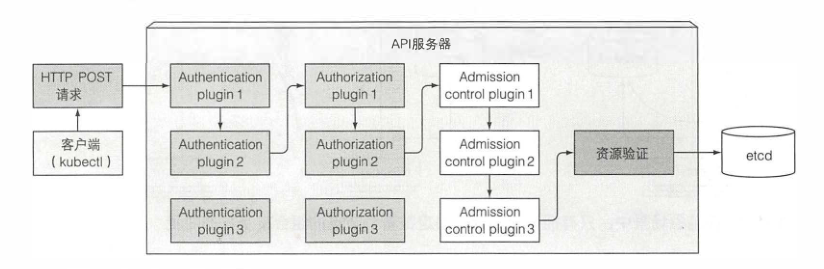
通过认证插件认证客户端
首先,API服务器需要认证发送请求的客户端。这是通过配置在API服务器上的一个或多个认证插件来实现的。API服务器会轮流调用这些插件,直到有一个能确认是谁发送了请求。这是通过检查HTTP请求实现的。
通过授权插件授权客户端
除了认证插件,API服务器还可以配置使用一个或多个授权插件。它们的作用是决定认证的用户是否可以对请求资源执行请求操作。
准入控制器插件验证AND/OR修改资源请求
如果请求尝试创建、修改或者删除一个资源,请求需要经过准入控制插件的验证。同理,服务器会配置多个准入控制插件。这些插件会因为各种原因修改资源,可能会初始化资源定义中漏配的字段为默认值甚至重写它们。
验证资源以及持久化存储
请求通过了所有的准入控制插件后,API服务器会验证存储到etcd的对象,然后返回一个响应给客户端
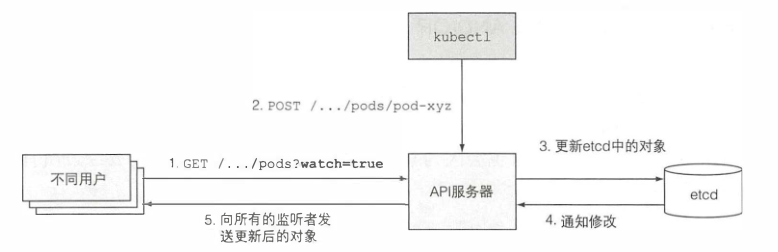
1.4 API服务器如何通知客户端资源变更
API服务器要做的是启动这些控制器,以及其他一些组件来监控已部署资源的变更。控制平面可以请求订阅资源被创建、修改或删除的通知。这使得组件可卡因在集群元数据变化时执行任何需要做的任务。
客户端通过创建到API服务器的HTTP连接来监听变更。通过此连接,客户端会接收到监听对象的一系列变更通知。每当更新对象,服务器把新版本对象发送至所有监听该对象的客户端。
1.5 了解调度器
调度器的操作比较简单,就是利用API服务器的监听机制等待新创建的pod,然后给每个新的、没有节点集的pod分配节点。
调度器不会命令选中的节点(或者节点上运行的kubelet)去运行pod。调度器做的就是通过API服务器更新pod的定义。然后API服务器再去通知kubelet(同样通过之前描述的监听机制)该pod已经被调度过。当目标节点上的kubelet发现该pod被调度到本节点,它就会创建并且运行pod的容器。
1.6 介绍控制器管理器中运行的控制器
控制器做了许多不同的事情,但是它们都通过API服务器监听资源(部署、服务等)变更,并且不论是创建新对象还是更新、删除已有对象,都对变更执行相应操作。
总的来说,控制器执行一个“调和”循环,将实际状态调整为期望状态,然后将新的实际状态写入资源的status部分。控制器利用监听机制来订阅变更,但是由于使用监听机制并不保证控制器不会漏掉时间,所以仍然需要定期执行重列举操作来确保不会丢掉什么。
控制器之间不会直接通信,它们甚至不知道其他控制器的存在。每个控制器都连接到API服务器,请求订阅该控制器负责的一些列资源的变更。
1.7 Kubelet做了什么
简单地说,kubelet就是负责所有运行在工作节点上内容的组件。它第一个任务就是在API服务中创建一个Node资源来注册该节点。然后需要持续监控API服务器是否把该节点分配给pod,然后启动pod容器。具体实现方式是告知配置好的容器运行时来从特定容器镜像运行容器。kubelet然后持续监控运行的容器,向API服务器报告它们的状态、事件和资源消耗。
kubelet也是运行容器存活探针的组件,当探针报错时它会重启容器。最后一点,当pod从API服务器删除时,kubelet终止容器,并通知服务器pod已经被终止了。
1.8 kubernetes service proxy的作用
除了kubelet,每个工作节点还会运行kube-proxy,用于确保客户端可以通过k8s API连接到你定义的服务。kube-proxy确保对服务IP和端口的连接最终能到达支持服务的某个pod处。如果有多个pod支撑一个服务,那么代理会发挥对pod的负载均衡作用。
2. 控制器如何协作
2.1 了解涉及哪些组件
在启动整个流程之前,控制器、调度器、kubelet就已经通过API服务器监听它们各自资源类型的变化了。如下图,描画了每个组件在即将触发的流程中都起到一定的作用。图中不包含etcd,因为它被隐藏在API服务器之后,可以想象成API服务器就是对象存储的地方。
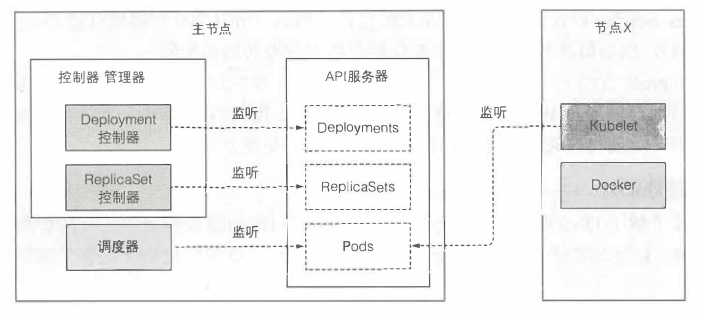
2.2 事件链
准备包含deployment清单的YAML文件,通过kubectl 提交到kubernetes。kubectl通过HTTP POST请求发送清单到kubernetes API服务器。API服务器检查deployment定义,存储到etcd,返回响应给kubectl。现在事件链开始被揭示出来
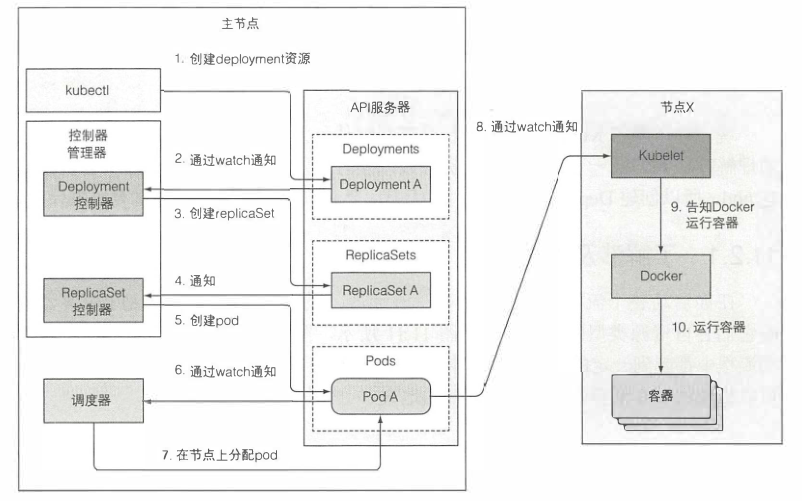
Deployment控制器生成ReplicaSet
当新创建Deployment资源时,所有通过API服务器监听机制监听Deployment列表的客户端马上会收到通知。其中有个客户端叫Deployment控制器,该控制器是一个负责处理部署事务的活动组件。
一个Deployment由一个或多个ReplicaSet支持,ReplicaSet后面会创建实际的Pod。当Deployment控制器检查到有一个新的Deployment对象时,会按照Deployment当前定义创建ReplicaSet。这包括通过k8s API创建一个新的ReplicaSet资源。Deployment控制器完全不会去处理单个pod。
ReplicaSet控制器创建pod资源
新创建的ReplicaSet由ReplicaSet控制器(通过API服务器创建、修改、删除ReplicaSet资源)接收。控制器会考虑replica数量、ReplicaSet中定义的pod选择器,然后检查是否有足够的满足选择器的pod。
然后控制器会基于ReplicaSet的pod模板创建pod资源。
调度器分配节点给新创建的pod
新创建的pod目前保存在etcd中,但是它们每个都缺少一个重要的东西——它们还没有任何关联节点。它们的nodeName属性还未被设置。调度器会监控像这样的pod,发现一个,就会为pod选择最佳节点,并将节点分配给pod。pod的定义现在就会包含它应该运行在哪个节点。
目前,所有个一切都发送在k8s控制平面中。参与这个全过程的控制器没有其他具体的事情,除了通过API服务器更新资源。
Kubelet运行pod容器
随着pod目前分配给了特定的节点,节点上的kubelet终于可以工作了。kubelet通过API服务器监听pod变更,发现有新的pod分配到本节点后,会去检查pod定义,然后命令docker或者任何使用的容器运行时来启动pod容器,容器运行时就会去运行容器。
2.3 了解运行中的pod是什么
在容器启动时,会启动一个基础容器,它的母的是保存所有的命名空间,所有pod的其他用户定义容器使用pod的该基础容器的命名空间。
实际的应用容器可能会挂掉并重启,当容器重启,容器需要处于与之前相同的Linux命名空间中。基础容器使这成为可能,因为它的生命周期和pod绑定,基础容器pod被调度直到被删除一直会运行。如果基础pod在这期间被关闭,kubelet会重新创建它,以及pod的所有容器。
2.4 跨pod网络
k8s中每个pod有自己唯一的IP地址,可以通过一个扁平的、非NAT网络和其他Pod通信。
2.4.1 网络应该是什么样的
当podA连接(发送网络包)到podB时,podB获取到的源IP地址必须和podA自己认为的IP地址一致。其间应该没有网络地址转换(NAT)操作——podA发送到podB的包必须保持源和目的地址不变。
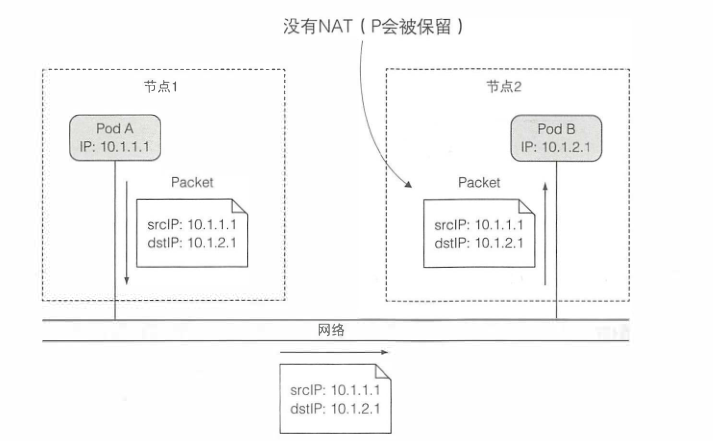
2.4.2 深入了解网络工作原理
在2.3可以看到创建pod的IP地址以及网络命名空间,由基础设施容器来保存这些信息,然后pod容器就可以使用网络命名空间了。pod网络接口就是生成基础设施容器的一些东西。
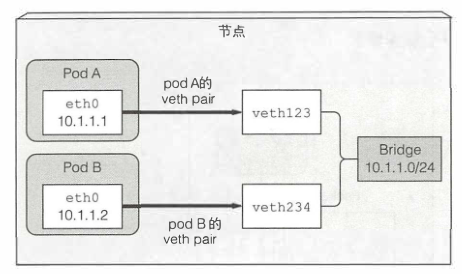
同节点pod通信
基础容器启动之前,会为容器创建一个虚拟Ethernet接口对(一个veth pair),其中一个对的接口保留在主机的命名空间中,而其他的对被移入容器网络命名空间,并重命名为eth0。两个虚拟接口就像管道的两端——从一端进入,另一端出来。
主机网络命名空间的接口会绑定到容器运行时配置使用的网络桥接上。从网桥的地址段中取IP地址赋值给容器内的eth0接口。应用的任何运行在容器内部的程序都会发送数据到eth0网络接口,数据从主机命名空间的另一个veth接口出来,然后发送给网桥。这意味着任何连接到网桥的网络接口都可以接收该数据。
如果podA发送网络包到podB,报文首先会经过podA的veth对到网桥然后经过podB的veth对。所有节点上的容器都会连接到同一个网桥,意味着它们都能够互相通信。但是要让运行在不同节点上的容器之间能够通信,这些节点的网桥需要以某种方式连接起来。
不同节点上的pod通信
有多种连接不同节点上的网桥的方式。可以通过overlay或underlay网络,或者常规的三层路由。
跨整个集群的pod的IP地址必须是唯一的,所以跨节点的网桥必须使用非重叠地址段,防止不同节点上的pod拿到同一个IP。
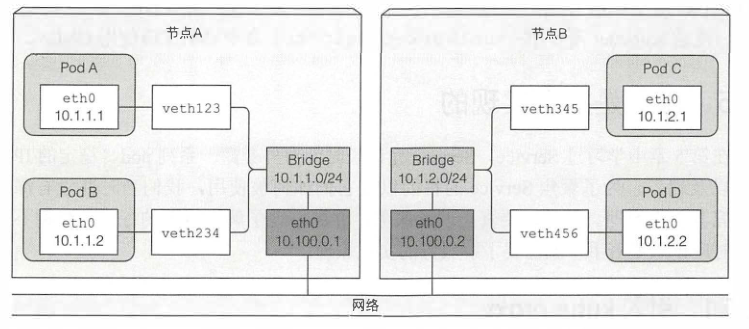
按照该配置,当报文从一个节点上容器发送到其他节点上的容器,报文先通过veth pair,通过网桥到节点物理适配器,然后通过网线传到其他节点的物理适配器,再通过其他节点的网桥,最终经过veth pair到达目标容器。
2.5 kube-proxy如何使用iptables
当在API服务器中创建一个服务时,虚拟IP地址立刻就会分配给它。之后很短时间内,API服务器会通知所有运行在工作节点上的kube-proxy客户端有一个新服务已经被创建了。然后每个kube-proxy都会让该服务在自己的运行节点上可寻址。原理是通过建立一些iptables规则,确保每个目的地为服务的IP/端口对的数据包被解析,目的地址被修改,这样数据包就会被重定向到支持服务的一个Pod。
3.运行高可用集群
为了使得k8s高可用,需要运行多个主节点,即运行下述组件的多个实例:
etct分布式数据存储,所有API对性存于此处
API服务器
控制器管理器,所有控制器运行的进程
调度器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号