
Python数据类型
数据类型介绍
-
什么是数据
-
为何要数据分不同的类型
-
数据有哪些类型
-
五大数据类型基本划分
一、什么是数据
在计算机科学中,数据是指所有能输入到计算机并被计算机程序处理的符号的介质的总称,是用于输入电子计算机进行处理,具有一定意义的数字字母、符号和模拟量等的统称。现在计算机存储和处理对象十分广泛,表示这些对象的数据也随之变得越来越复杂。
二、为何要数据分不同的类型
数据是用来表示状态的,不同的状态就应该用不同的类型的数据去表示
举个例子:
在游戏当中你会有你的自己的人物、装备、等级、金钱等等、这些都是数据,在Python中这些数据都有自己各自的类型。
例如用cs来说
名字:帝皇侠传说------------------------>字符串
金钱:88888888 --------------------------------->数字
装备:毁灭,闪光弹,防弹衣 --------->列表
击杀数:999999 --------------------------------->数字
等等,还有很多其他类型的数据,处理不同类型的数据就需要定义不同的数据类型
数据结构的意义:
数据结构的意义:将上述五大数据类型整合到一起。但是掺到一起不是目的。目的是能够组合成一个好的结构,方便自己或者他人进行数据存储或者读取。
三、数据有哪些类型
数字(整型,长整型,浮点,布尔,复数)
1.整数:根据字面的意思俩理解就没有小数点的数
2.长整数:就是很长的整数
3.浮点型:就是带小数点的数字
4.布尔型:True与False(1和0)
5.复数: 复数有实数部分和虚数部分组成,一般形式为x+yj,其中x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数
注意,虚数的大小写字部分的字母j不分大小写
字符串
在python如何定义一串字符为字符串呢?
用 " " 、' ' 、''' '''或者""" """。中间包含的部分称之为字符串
注意:即使里面写入的是数字,那么他的数据类型也是字符串;字符串是不可改变的
常见的字符串操作有:
移除空白、分隔、长度、索引、切片等等;
列表
定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素
常见的操作有:
增加、插入、删除、查询、切片、索引、长度等
元组
以'()'圆括号进行定义,与列表极其相似。也是序列类型 可以进行索引,切片,查询,也可以进行遍历
元组与列表的唯一区别则是不可改变
常见的操作有:
索引、切片、循环、长度、包含
字典
字典占用的内存空间将会大于列表,在系统中要保存一个hash列表(用系统内存换取时间)
字典属于key:value 结合(key值是不可变的,value值可以变)并且是无序的
集合
定义:由不同的元素组成的集合,集合中是一组无序排列的可hash值,可作为字典的key,而且集合中的值不可重复。
特性:集合的目的就是将不同的值存放在一起,不同的集合间来做关系运算,无序纠结集合中单个值
集合包括可变集合和不可变集合
hash是什么?
打个比方,比如说有一个文件(不管多大),对这个文件要进行一个hash校验,会得到一个校验值(固定长度)。
hash是一种统称,具体要进行校验的话,是需要调用它下面的算法。(校验就是通过一个算法算出这个文件的一个值)。
特点:
1.只要用的算法是一定,那么得到的值的长度永远是一定的
2.原值(被校验的值)只要改一点,那么在此校验的值将会改变
3.不可逆。不可能通过一串hash值来推导出这个文件内容
算法:MD5 SH512等等
用途:最多的用途就是进文件校验(看文件是否被篡改)。再一个就是tcp/ip协议。只能对不可变的值进行hash校验。如果集合中有可变类型那么回保错。
注意:
列表是不可hash类型;在python中,看到不可hash类型就是可变类型,反之,可hash类型就是不可变类型
数字类型
-
种类
-
数字类型的关系
-
数字类型转换
-
数字运算
-
数学函数
-
随机数函数
-
三角函数
-
数学常量
一、种类
整数型(int)
整数型定义上也可成短整型,理论上有范围的限制,取值范围为:在32位机器上int的范围是: -2**31~2**31-1,即-2147483648~2147483647
在64位机器上int的范围是: -2**63~2**63-1,即-9223372036854775808~9223372036854775807,如果超过这个范围就可以使用长整型,不过必须在结尾写上大写的“L”,小写也可以,为了避免与1混淆,建议用L
需要注意的是:
上述中的int理论范围取值是参考的C语言整数范围。在实际的环境中,int范围并没有固定,我们用上述所说64位最大值乘1000测试一下;
实例如下:
>>> print(9223372036854775807 * 1000) 9223372036854775807000
我们发现并没有出错,实际上是因为发生溢出,Python3会自动将整数数据转换为长整数!这点还是需注意的。
Python中的整数不仅可以用十进制表示,也可以用八进制和十六进制表示。
当用二进制表示整数时,数值前面要加上一个前缀【0b或0B】用来表示是二进制数据
当用八进制表示整数时,数值前面要加上一个前缀【0o或0O】用来表示是八进制数据
当用十六进制表示整数时,数字前面要加上一个前缀【0x或0X】用来表示是十六进制数据
例如:我们这里将整数15分别以八进制和十六进制和二进制的形式赋给整型变量a、b、c,然后再以十进制的形式输出它们
字符串类型(str)
-
字符串说明
-
索引和切片
-
转义字符
-
字符串运算符
-
字符串格式化
-
字符串内置的函数
一.字符串说明
字符串是 Python 中最常用的数据类型。我们可以使用引号('或")来创建字符串。
字符串是不可变的数据类型,不论执行任何操作,源字符串是不会改变的,每次操作都会返回新字符串;
创建字符串,只需要为变量赋值即可,如:Str = "hello world"
字符串在转换成int时,如果字符串中的数字有空格,则在转换时自动去除空格;
访问字符串中的值:
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
>>> print("hello world") hello world
字符串更新:
可以截取字符串的一部分并与其他字段拼接,如下实例:
>>> print("hello world" + " 你好,中国") hello world 你好,中国
二、索引和切片
1.索引
说明:通过索引取出字符串对应的值
格式:str[下标]
参数:下标 ------ > 是一个int型数据,
索引从0开始,使用[下标]可以获取到每一个字符,还可以倒着数,最后一个字符用-1表示,一次往前数是-1、-2...
返回值:返回字符串对应索引所对应的值;如果索引超出边界则报错
实例:

>>> s = "abcdefg" >>> print(s[0]) a >>> print(s[1]) b >>> print(s[2]) c >>> print(s[3]) d >>> print(s[4]) e >>> print(s[5]) f >>> print(s[6]) g
----------------索引超出边界,报错---------------------------------
>>> print(s[7])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
2.切片
说明:通过切片取出字符串的一段字符;
格式:str[起始位置:结束位置:步长]
参数:起始位置 --------> 表示从哪个下标开始
结束位置 --------> 表示到哪个下标结束
步长 --------------> 默认从左到右,步长为1,也可以取反,表示倒叙,步长取负数
特点:顾头不顾尾,从start开始截取. 截取到end位置. 但不包括end
返回值:返回一个由切片选择好的子串;
实例:
>>> s = "abcdefg" >>> print(s[:]) abcdefg >>> print(s[0:4]) abcd >>> print(s[2:6]) cdef >>> print(s[:6:2]) ace >>> print(s[1::2]) bdf >>> print(s[::-1]) gfedcba >>> print(s[-1:-3]) >>> print(s[-1:-3:-1]) gf >>> print(s[-1::-2]) geca
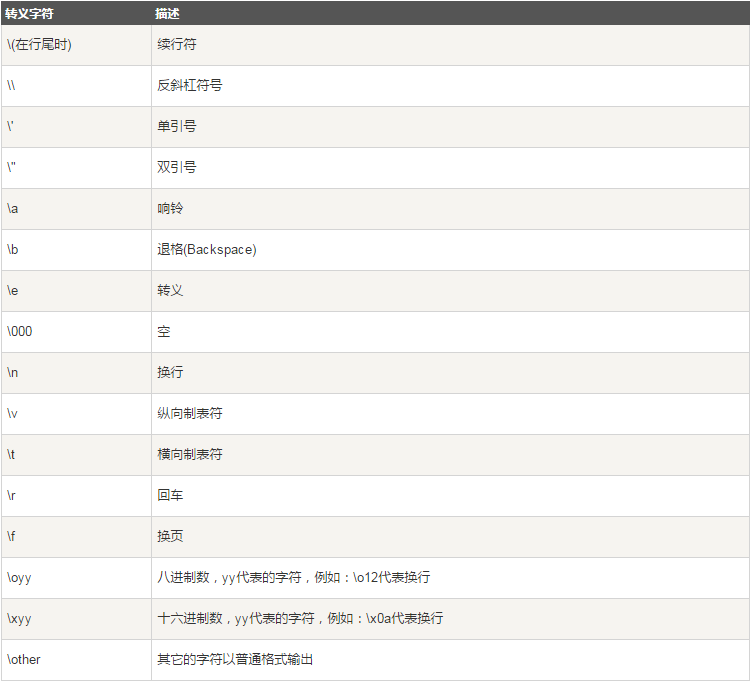
三.转义字符
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
四.字符串运算符
下表实例变量a值为字符串 "Hello",b变量值为 "Python":

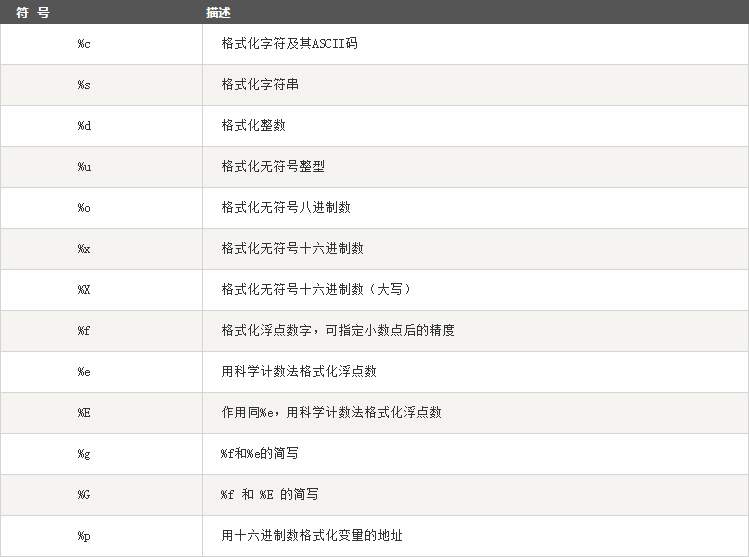
五.字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
>>> print("中国的首都是%s" % ("北京")) 中国的首都是北京
python字符串格式化符号:
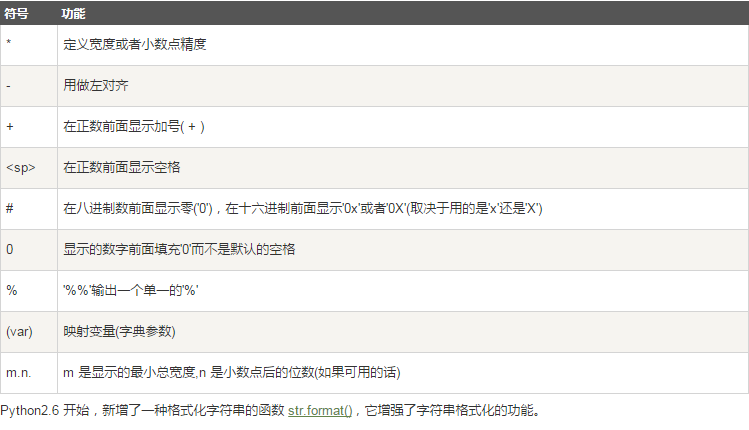
格式化操作符辅助指令:
六.字符串内置的函数

1.capitalize(self)
说明:将字符串的第一个字符转换为大写,其他字母变成小写;注意的是并不会改变原字符串内容;
语法:str.capitalize()
返回值:该方法返回一个首字母大写的字符串;
实例:
>>> S = "hello WoRld" >>> print(S.capitalize()) Hello world
2.casefold(self)
说明:将字符串中的所有大写字符转换为小写字符;并支持识别东欧的一些字母;lower不支持东欧的字母;
语法:str.casefold()
返回值:返回将字符串中所有大写字符转换为小写后生成的字符串;
实例:
>>> S = "hello WoRld" >>> print(S.casefold()) hello world
3.center(self, width, fillchar=None)
说明:返回一个指定的宽度width且居中的字符串,字符串长度为width,fillchar为填充的字符,默认为空格;
语法:str.center(width,fillchar)
返回值:返回一个指定的宽度 width 居中的字符串,如果 width 小于字符串宽度直接返回字符串,否则使用 fillchar 去填充。
实例:
>>> print("今日头条".center(40,"*")) ******************今日头条******************
4.count(self, sub, start=None, end=None)
说明:用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
语法:str.count(sub,start=None, end=None)
参数:sub -----> 要搜索的子字符串;
start -----> 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0;
end ------> 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置;
返回值:返回子字符串在字符串中出现的次数;
实例:
>>> print(ss.count("a")) 2 >>> print(ss.count("a",0,8)) 1
5.encode(self, encoding='utf-8', errors='strict')
说明:以指定的编码格式来编码字符串。errors参数可以指定不同的错误处理方案。
语法:str.encode(encoding='utf-8', errors='strict')
参数:encoding -----> 要使用的编码,如:UTF-8
errors -----> 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
返回值:返回编码后的字符串,是一个 bytes 对象
实例:
>>> abc = "灯火阑珊" >>> abc_utf8 = abc.encode("UTF-8") >>> abc_gbk = abc.encode("GBK") >>> print(abc) 灯火阑珊 >>> print(abc_utf8) b'\xe7\x81\xaf\xe7\x81\xab\xe9\x98\x91\xe7\x8f\x8a' >>> print(abc_gbk) b'\xb5\xc6\xbb\xf0\xc0\xbb\xc9\xba'
6.decode(self, decoding='utf-8', errors='strict')
说明:以指定的编码格式来解码字符串。errors参数可以指定不同的错误处理方案。
语法:bytes.decode(encoding="utf-8", errors="strict")
参数:encoding -----> 要使用的编码,如:UTF-8
errors -----> 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
返回值:返回解码后的字符串;
实例:
>>> print(abc_gbk.decode("GBK")) 灯火阑珊 >>> print(abc_utf8.decode("UTF-8")) 灯火阑珊
7.endswith(self, suffix, start=None, end=None)
说明:用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False;
语法:str.endswith(suffix,start=None, end=None)
参数:suffix -----> 该参数可以是一个字符串或者是一个元素;
start ------> 字符串中的开始位置;
end ------> 字符中结束位置
返回值:如果字符串含有指定的后缀返回True,否则返回False;
实例:
>>> end = "hello world" >>> print(end.endswith("ld")) True >>> print(end.endswith("ld",0,10)) False
8.expandtabs(self, tabsize=8)
说明:把字符串中的 tab 符号('\t')转为空格,tab 符号('\t')默认的空格数是 8;
注意:规则是这样的,如果设置空格数是8,则会从开头查询,每8个字符为一组,到有\t那组时,缺几个就补几个空格;
语法:str.expandtabs(tabsize=8)
参数:tabszie -----> 指定转换字符串中的 tab 符号('\t')转为空格的字符数;
返回值:返回字符串中的 tab 符号('\t')转为空格后生成的新字符串;
实例:
>>> ss = "this is \tstring example" >>> print(ss) this is string example
#this is 刚好8个,所以到\t这里自动在补8个空格;
>>> print(ss.expandtabs(0))
this is string example
#0自动没有
>>> print(ss.expandtabs(20))
this is string example
#this is \t是8个,设置的是20空格,所以还需在补12个空格
9.find(self, sub, start=None, end=None)
说明:检测字符串中是否包含子字符串 sub ,如果指定 start(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。
语法:str.find(sub, start=None, end=None)
参数:sub ------> 指定检索的字符串;
start -----> 指定开始索引位置,默认为0
end -----> 指定结束索引位置,默认为字符串长度,len(str)
返回值:如果包含子字符串返回开始的索引值,否则返回-1;
实例:
>>> str1 = "Life is too short for python" >>> print(str1.find("short")) 12 >>> print(str1.find("short",5,19)) 12
>>> print(str1.find("short",17,19))
-1
10.format(self, *args, **kwargs)
说明:format函数用于字符串的格式化,通过{}和:来代替%;传入的参数两种形式,一种是位置参数,一种是关键字参数;位置参数不受顺序约束,且可以为{},只要format里有相对应的参数值即可,参数索引从0开,传入位置参数列表可用*列表,关键字参数值要对得上,可用字典当关键字参数传入值,字典前加**即可,注意的是当位置参数和关键字参数混合使用时,位置参数一定要在关键字参数左边。
语法:str.format( *args, **kwargs)
参数:*args ------> 当传入的参数为列表时,可用*列表;
**kwargs -------> 可用字典当关键字参数传入值,字典前加**即可;
返回值:返回一个已经填充好的字符串。
例子:
------------------不设置指定位置,按默认顺序-------------------------- >>> str2 = "中国的城市有,{},{},{},{}" >>> print(str2.format("北京","上海","深圳","武安")) 中国的城市有,北京,上海,深圳,武安 ----------------设置指定位置------------------------------------------- >>> str2 = "中国的城市有,{3},{0},{2},{1}" >>> print(str2.format("北京","上海","深圳","武安")) 中国的城市有,武安,北京,深圳,上海 ------------------使用位置-列表形式--------------------------- >>> li = ["北京","上海","深圳","武安"] >>> print(str2.format(*li)) 中国的城市有,北京,上海,深圳,武安
-------------------使用关键字位置形式-------------------------
>>> print(str2.format(k2="北京",k3="上海",k1="深圳",k4="武安"}))
中国的城市有,深圳,北京,上海,武安
-------------------使用关键字位置字典形式------------------------- >>> print(str2.format(**{"k2":"北京","k3":"上海","k1":"深圳","k4":"武安"})) 中国的城市有,深圳,北京,上海,武安 -------------------使用混合模式-------------------------------- >>> str2 = "中国的城市有,{3},{0},{2},{1},{h}" >>> print(str2.format("北京","上海","深圳","武安",**{"h":"石家庄"})) 中国的城市有,武安,北京,深圳,上海,石家庄
也可以向.format()传入对象:
class test(): def __init__(self,asd): self.num = asd ming = test(6) print("ming的数字是:{0.num}".format(ming)) #{0.num}中的0是可选的表示指定位置 -------------------输出结果为------------------------------ ming的数字是:6
.format()的数字格式化:
>>> print("{:.2f}".format(3.1415926)) 3.14
下表展示了 str.format() 格式化数字的多种方法:

>>> print("{}对应的位置是{{0}}".format("zjk")) zjk对应的位置是{0}
11.format_map(self, mapping)
说明:类似于format,不同的是format_map只能使用关键字位置形式传入字典来进行;
语法:str.format_map(mapping)
参数:mapping -----> 必须是一个字典;
返回值:一个已经填充好的字符串;
实例:
>>> print("{name}对应的位置是{{0}}".format_map({"name":"zjk"})) zjk对应的位置是{0}
12.index(self, sub, start=None, end=None)
说明:检测字符串中是否包含子字符串 sub ,如果指定 start(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果sub不在 str中则会报一个异常,而find则是返回-1;
语法:str.index(sub,start=None, end=None)
参数:sub ------> 指定检索的子字符串;
start -----> 指定开始索引位置,默认为0;
end ------> 指定结束索引位置,默认为字符串的长度;
返回值:如果包含子字符串返回开始的索引值,否则抛出异常;
实例:
>>> str1 = "Life is too short for python" >>> print(str1.index("short")) 12 >>> print(str1.index("short",14)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: substring not found
13.isalnum(self)
说明:检测字符串是否由字母和数字组成;
语法:str.isalnum()
返回值:如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
实例:
>>> str1 = "helloworld" >>> print(str1.isalnum()) True >>> str2 = "hello world" >>> print(str2.isalnum()) False
14.isalpha(self)
说明:检测字符串是否只由字母组成;
语法:str.isalpha()
返回值:如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False;
实例:
>>> str1 = "python" >>> print(str1.isalpha()) True >>> str2 = "python3" >>> print(str2.isalpha()) False
15.isdecimal(self)
说明:检查字符串是否只包含十进制字符。这种方法只存在于unicode对象;注意:定义一个十进制字符串,只需要在字符串前添加 'u' 前缀即可。
语法:str.isdecimal()
返回值:如果字符串只包含十进制字符返回True,否则返回False
实例:
>>> str1 = u"zjk2018" >>> print(str1.isdecimal()) False >>> str2 = u"201807" >>> print(str2.isdecimal()) True
16.isdigit(self)
说明:检测字符串是否只由数字组成;
语法:str.isdigit()
返回值:如果字符串只包含数字则返回 True 否则返回 False;
实例:
>>> str1 = "zjk2018" >>> print(str1.isdigit()) False >>> str2 = "201807" >>> print(str2.isdigit()) True
17.isidentifier(self)
说明:判断是否为python中的标识符,也就是说是否符合python变量名语法;
语法:str.isidentifier()
返回值:如果字符串的内容符合python变量命名语法,则返回True,否则返回False;
实例:
>>> str1 = "zjk1" True >>> str2 = "666zjk" >>> str2.isidentifier() False >>> str3 = "变量名" >>> str3.isidentifier() True >>> str4 = "def" >>> str4.isidentifier() True
#python的关键字一样是合法的 >>> str5 = "88888" >>> str5.isidentifier() False
18.islower(self)
说明:检测字符串是否由小写字母组成;
语法:str.islower()
返回值:如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False;
实例:
>>> str1 = "Life is too short for python -zjk23" >>> print(str1.islower()) False >>> str2 = "life is too short for python -zjk23" >>> print(str2.islower()) True
19.isnumeric(self)
说明:检测字符串是否只由数字组成。这种方法是只针对unicode对象;注:定义一个字符串为Unicode,只需要在字符串前添加 'u' 前缀即可;
语法:str.isnumeric()
返回值:如果字符串中只包含数字字符,则返回 True,否则返回 False
实例:
>>> str1 = "zjk1995" >>> print(str1.isnumeric()) False >>> str2 = "1995" >>> print(str2.isnumeric()) True
20.isprintable(self)
说明:判断是否由可打印字符组成,回车符等一些特殊字符是不会打印显示在屏幕上的;
语法:str.isprintable()
返回值:如果字符串中所有内容都可打印则返回True,否则返回False;
实例:
>>> print("123\t4\t56".isprintable()) False >>> print("123\\t456".isprintable()) True
21.isspace(self)
说明:检测字符串是否只由空白字符组成;
语法:str.isspace()
返回值:如果字符串中只包含空格,则返回 True,否则返回 False;
实例:
>>> str1 = " " >>> print(str1.isspace()) True >>> str2 = " sdf sdf" >>> print(str2.isspace()) False
22.istitle(self)
说明:检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写;
语法:str.istitle()
返回值:如果字符串中所有的单词拼写首字母是否为大写,且其他字母为小写则返回 True,否则返回 False;
实例:
>>> str1 = "Life Is Too Short For Python" >>> print(str1.istitle()) True >>> str2 = "Life is Too short For PyThon" >>> print(str2.istitle()) False
23.isupper(self)
说明:检测字符串中所有的字母是否都为大写;
语法:str.isupper()
返回值:如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False;
实例:
>>> str1 = "LIFE IS TOO SHORT FOR PYTHON" >>> print(str1.isupper()) True >>> str2 = "LIFE Is TOO ShOrT FOR PYTHON" >>> print(str2.isupper()) False
24.join(self, iterable)
说明:用于将序列中的元素以指定的字符连接生成一个新的字符串;
语法:n.join(iterable)
参数:iterable ------> 要连接的元素序列;
n --------------> 指定用来连接的字符;
返回值:返回通过指定字符连接序列中元素后生成的新字符串;
实例:
>>> str1 = "zjk" >>> print("-".join(str1)) z-j-k
25.ljust(self, width, fillchar=None)
说明:返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串;
语法:str.ljust(width, fillchar=None)
参数:width ------> 指定字符串长度;
fillchar -----> 填充字符,默认为空格;
返回值:返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串;
实例:
>>> str1 = "I Love You" >>> print(str1.ljust(20,"*")) I Love You********** ------------当指定的填充长度小于原字符串长度时返回原字符串------- >>> str2 = "I Love You" >>> print(str1.ljust(10,"*")) I Love You
26.lower(self)
说明:转换字符串中所有大写字符为小写;
语法:str.lower()
返回值:返回将字符串中所有大写字符转换为小写后生成的字符串;
实例:
>>> str1 = "I Love You" >>> print(str1.lower()) i love you
27.lstrip(self, chars=None)
说明:用于截掉字符串左边的空格或指定字符,贪婪模式;
语法:str.lstrip( chars=None)
参数:chars ------> 指定截取的字符;
返回值:返回截掉字符串左边的空格或指定字符后生成的新字符串;
实例:
>>> str1 = "666666I66Love You" >>> print(str1.lstrip("6")) I66Love You
28.maketrans(self, *args, **kwargs)
说明:用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。两个字符串的长度必须相同,为一一对应的关系;
语法:str.maketrans(intab,outtab)
参数:intab -------> 需要转换的字符串;
outtab -----> 被转换的字符串;
返回值:返回的是一个字典,字典内容是字符串的ASCII码的序号,一一对应
实例:
>>> dat = str.maketrans("123","abc") >>> print(dat) {49: 97, 50: 98, 51: 99} -----------------解释-------------------------- 1 的ASCII码为 49 a 的ASCII码为 97
29.partition(self, sep)
说明:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串;
语法:str.partition(sep)
参数:sep ------> 指定分隔符
返回值:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串;
实例:
>>> str1 = "http://www.dhlanshan.cn" >>> print(str1.partition("//")) ('http:', '//', 'www.dhlanshan.cn') -----------如果指定的分隔符在字符串中有两个,则以最左侧为分隔符---------- >>> print(str1.partition(".")) ('http://www', '.', 'dhlanshan.cn')
30.replace(self, old, new, count=None)
说明:将字符串中的某子串进行替换,默认替换指定的所有子串;
语法:str.replace(old, new, count=None)
参数:old ------> 旧的子串;
new -----> 新的子串;
count ----> 替换的次数;
返回值:返回一个子串替换好之后的新的字符串;
实例:
------------------替换所有子串---------------------------- >>> str1 = "http://video.dhlanshan.cn" >>> print(str1.replace("a","A")) http://video.dhlAnshAn.cn -----------------从左到右只替换1次子串------------------ >>> print(str1.replace("a","A",1)) http://video.dhlAnshan.cn
31.rfind(self, sub, start=None, end=None)
说明:返回指定的子串在字符串中最后一次出现的位置,如果没有匹配项则返回-1;也可以说是从右边开始找这个指定的子串;
语法:str.rfind(sub, start=None, end=None)
参数:sub ------> 指定的子串;
start ------> 开始查找的位置,默认为0;
end ------> 结束查找位置,默认为字符串的长度;
返回值:返回字符串最后一次出现的位置,如果没有匹配项则返回-1
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rfind("an")) 20 >>> print(str1.rfind("an",21)) -1
32.rindex(self, sub, start=None, end=None)
说明:返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常,和rfind类似,只不过rfind找不到会返回-1;也可以说是从右边开始找这个指定的子串;
语法:str.rindex(sub, start=None, end=None)
参数:sub ------> 指定的子串;
start ------> 开始查找的位置,默认为0;
end ------> 结束查找位置,默认为字符串的长度;
返回值:返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rindex("an")) 20 ---------------找不到则报错-------------------------- >>> print(str1.rindex("an",21)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: substring not found
33.rjust(self, width, fillchar=None)
说明:返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。
语法:str.rjust(width, fillchar=None)
参数:width ------> 指定填充指定字符后中字符串的总长度;
fillchar -----> 填充的字符,默认为空格;
返回值:返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rjust(30,"-")) -----http://video.dhlanshan.cn
34.rpartition(self, sep)
说明:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串,分隔符从字符串的右边开始查找。
语法:str.rpartition(sep)
参数:sep ----->指定分隔符;
返回值:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rpartition(".")) ('http://video.dhlanshan', '.', 'cn')
35.rsplit(self, sep=None, maxsplit=-1)
说明:分隔字符串,从右侧开始分隔,返回一个将字符串以指定分隔符分隔的列表,从右边开始查找分隔符,默认空格为分隔符;注意,最后列表里是不存在指定的那个分隔符的;
语法:str.rsplit(sep=None, maxsplit=-1)
参数:sep ------> 指定分隔符;
maxsplit ------> 最多分隔的次数,-1表示全部分隔;
返回值:返回一个将字符串以指定分隔符分隔的列表;
实例:
--------------------分隔所有-------------------------------------- >>> str1 = "1 2 3 4 5" >>> print(str1.rsplit(" ",maxsplit=-1)) ['1', '2', '3', '4', '5'] -------------------分隔2次--------------------------------------- >>> print(str1.rsplit(" ",maxsplit=2)) ['1 2 3', '4', '5'] --------------------列表中会删除指定的分隔符----------------- >>> print(str1.rsplit("3",maxsplit=1)) ['1 2 ', ' 4 5']
36.rstrip(self, chars=None)
说明:删除 string 字符串最右边的指定字符(默认为空格);贪婪模式;
语法:str.rstrip(chars=None)
参数:chars ------> 指定的子符;
返回值:返回删除 string 字符串最右边的指定字符后生成的新字符串;
实例:
>>> str1 = "**********今日说法**************" >>> print(str1.rstrip("*")) **********今日说法
37.split(self, sep=None, maxsplit=-1)
说明:分隔字符串,从左侧开始分隔,返回一个将字符串以指定分隔符分隔的列表,从左边开始查找分隔符,默认空格为分隔符;注意,最后列表里是不存在指定的那个分隔符的;
语法:str.rsplit(sep=None, maxsplit=-1)
参数:sep ------> 指定分隔符;
maxsplit ------> 最多分隔的次数,-1表示全部分隔;
返回值:返回一个将字符串以指定分隔符分隔的列表;
实例:
--------------------分隔所有-------------------------------------- >>> str1 = "1 2 3 4 5" >>> print(str1.split(" ",maxsplit=-1)) ['1', '2', '3', '4', '5']
-------------------当分隔符为整个字符串时则返回一个有两个空字符串的元素的列表----------------------
>>> str1 = "1 2 3 4 5"
>>> print(str1.split("1 2 3 4 5",maxsplit=-1))
['', '']
-------------------分隔2次--------------------------------------- >>> print(str1.split(" ",maxsplit=2)) ['1','2','3 4 5'] --------------------列表中会删除指定的分隔符----------------- >>> print(str1.split("3",maxsplit=1)) ['1 2 ', ' 4 5']
38.splitlines(self, keepends=None)
说明:按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
语法:str.splitlines(keepends=None)
参数:keepends -- 在输出结果里是否去掉换行符('\r', '\r\n', \n'),默认为 False,不包含换行符,如果为 True,则保留换行符
返回值:返回一个包含各行作为元素的列表。
实例:
>>> print("abc\n\ndefg\rkl\r\n".splitlines()) ['abc', '', 'defg', 'kl'] >>> print("abc\n\ndefg\rkl\r\n".splitlines(True)) ['abc\n', '\n', 'defg\r', 'kl\r\n']
39.startswith(self, prefix, start=None, end=None)
说明:用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 start 和 end 指定值,则在指定范围内检查。
语法:str.startswith(prefix, start=None, end=None)
参数:prefix ------> 指定的子串;
start -------> 索引开始处;
end --------> 索引结尾处;
返回值:如果检测到字符串则返回True,否则返回False;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.startswith("http")) True >>> print(str1.startswith("video",7)) True >>> print(str1.startswith(":",6,9)) False
40.strip(self, chars=None)
说明:用于移除字符串头尾指定的字符(默认为空格)或字符序列。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
语法:str.strip(chars)
参数:chars -------> 移除字符串头尾指定的字符序列;
返回值:返回移除字符串头尾指定的字符序列生成的新字符串;
实例:
>>> str1 = "**********今*日*说*法**************" >>> print(str1.strip("*")) 今*日*说*法
无敌匹配法:
先看效果:
>>> str1 = "12345654321" >>> print(str1.strip("12")) 3456543 >>> str1 = "12345654312" >>> print(str1.strip("12")) 3456543 >>> str1 = "12345654321" >>> print(str1.strip("125")) 3456543 >>> str1 = "1234565431221" >>> print(str1.strip("12")) 3456543 >>> str1 = "1234565432121" >>> print(str1.strip("12")) 3456543 ----------------------------------------说明-------------------------------- #其实“12”是分为了3个匹配符,分别是"1" "2" "12",这三个匹配符会循环去匹配字符串,直到这三个匹配符一个也匹配不上为止。
41.swapcase(self)
说明:用于对字符串的大小写字母进行转换,小写变大写,大写变小写;
语法:str.swaocase()
返回值:返回大小写字母转换后生成的新字符串;
实例:
>>> str1 = "I Love You" >>> print(str1.swapcase()) i lOVE yOU
42.title(self)
说明:返回"标题化"的字符串,就是说所有单词的首个字母转化为大写,其余字母均为小写;注意,默认是按空格来分单词,也可以是其他特殊字符或数字。
语法:str.title()
返回值:返回"标题化"的字符串,就是说所有单词的首字母都转化为大写。
实例:
>>> str1 = "Life is too short for python" >>> print(str1.title()) Life Is Too Short For Python
使用特殊字符或数字来区分:
>>> str1 = "zjk zjk*zjk&zjk^zjk@,zjk.zjk9zjk8zjk/zjk" >>> print(str1.title()) Zjk Zjk*Zjk&Zjk^Zjk@,Zjk.Zjk9Zjk8Zjk/Zjk
43.translate(self, table)
说明:根据由maketrans函数生成的对照表table完成字符替换;
语法:str.tarnslate(table)
参数:table ---- 对照表,是由maketrans函数生成;
返回值:返回翻译后的字符串;
实例:
>>> table = str.maketrans("zjk","666") >>> str = "zjkqwert" >>> print(str.translate(table)) 666qwert
44.upper(self)
说明:将字符串中的小写字母转为大写字母;
语法:str.upper()
返回值:返回小写字母转为大写字母的字符串;
实例:
>>> str1 = "Life is too short for python" >>> print(str1.upper()) LIFE IS TOO SHORT FOR PYTHON
45.zfill(self, width)
说明:返回指定长度的字符串,原字符串右对齐,前面填充0,若指定长度小于原字符串长度,则返回原字符串;
语法:str.zfill(width)
参数:width -------> 指定字符串的长度。原字符串右对齐,前面填充0;
返回值:返回指定长度的字符串;
布尔类型
-
布尔说明
-
判定
一、布尔说明
python 中布尔值使用常量True 和 False来表示;注意大小写;
比较运算符< > == 等返回的类型就是bool类型;布尔类型通常在 if 和 while 语句中应用;
注意的是,python中,bool是int的子类(继承int),故 True==1 False==0 是会返回Ture的;
Python2中True/False不是关键字,因此我们可以对其进行任意的赋值;同理,Python 中 if(True) 的效率远比不上 if(1);Python2 版本中True False不是关键字,可被赋值,Python3中会报错;
由于bool是int,可进行数字计算 ,例如:print(True+True)
二、判定
以下值会被判断是True或False:
数字0 ---------- False;
None ---------- False; None是真空;
null (包括空字符串、空列表、空元祖....) --------- False;
除了以上的,其他的表达式均会被判定为 True,这个需要注意,与其他的语言有比较大的不同。
数据结构之列表类型(list)
-
列表说明
-
索引和切片
-
增加元素到列表
-
删除列表元素
-
更改列表元素
-
查看列表元素
-
列表脚本操作符
-
列表截取与拼接
-
嵌套列表
-
列表内置函数
一、列表说明
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。
列表是一个可变的数据类型
Python有6个序列的内置类型,但最常见的是列表和元组。
序列都可以进行的操作包括索引,切片,加,乘,检查成员。
Python已经内置确定序列的长度以及确定最大和最小的元素的方法
列表的数据项不需要具有相同的类型
列表由 [ ] 来表示, 每一项元素使用逗号隔开. 列表什么都能装. 能装对象的对象;
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
>>> li = ["zjk",123,"python"] >>> li2 = [1,2,3,4,5] >>> li3 = ["a","b","c"]
二、索引和切片
列表和字符串一样. 也有索引和切片. 只不过切出来的内容是列表;
索引的下标从0开始;
切片的表达形式:[起始位置:结束位置:步长]
二、增加元素到列表
向列表中添加元素有三种基本方法:
append()、insert()、extend()
1.append(obj),表示向列表的末尾追加一个元素obj,这个obj被当做一个整体添加到列表的末尾处;
例如:
>>> li = [1,2,3,4] >>> li.append("abc") >>> print(li) [1, 2, 3, 4, 'abc']
2.insert(index,obj),表示在索引index位置添加一个obj元素,obj元素是一个整体;
例如:
>>> li.insert(1,["a","b","c"]) >>> print(li) [1, ['a', 'b', 'c'], 2, 3, 4]
3.extend( iterable),表示向列表的末尾处添加一个可迭代对象,iterable被叠加到列表的末尾处;
例如:
>>> li = [1,2,3,4] >>> li.extend(["a","b","c"]) >>> print(li) [1, 2, 3, 4, 'a', 'b', 'c']
三、删除列表元素
删除列表中的元素有四种基本方法:
pop()、remove()、del 切片、clear()
1.pop(index),表示通过索引位置剪切走一个元素,
例子:
>>> li = [1,2,3,4] >>> a = li.pop(1) >>> print(li,a) [1, 3, 4] 2
2.remove(),搜索元素然后直接在列表中删除;
例子:
>>> li = [1,2,3,4] >>> li.remove(3) >>> print(li) [1, 2, 4]
3.del 切片,通过索引或切片的方式进行删除;
例子:
>>> li = [1,2,3,4] >>> del li[0] >>> print(li) [2, 3, 4] >>> del li[0:2] >>> print(li) [4]
4.clear(),清空整个列表;
例子:
>>> li = [1,2,3,4] >>> li.clear() >>> print(li) []
四、更改列表元素
1.索引修改;
例子:
>>> li = [1,2,3,4] >>> li[0] = "a" >>> print(li) ['a', 2, 3, 4]
2.切片修改:
这边需要注意的是,如果切片的步长为1,则不用关心赋值的参数问题,如果步长值不为1则是几就要添加几个参数;
例子:
----------------步长值为1,元素可以随意添加---------------------------
>>> li = [1,2,3,4] >>> li[1:3] = "abcdefg" >>> print(li) [1, 'a', 'b', 'c', 'd', 'e', 'f', 'g', 4]
--------------步长值为2,元素必须是两个元素---------------------------- >>> li = [1,2,3,4] >>> li[0::2] = "abc","kkk" >>> print(li) ['abc', 2, 'kkk', 4]
五、查看列表元素
查询列表中的元素可以使用索引方式,也可以使用for循环的方式;
索引方式或切片方式查询:
例子:
-----------------索引方式-------------------------- >>> li[0::2] = "abc","kkk" >>> print(li) ['abc', 2, 'kkk', 4] ----------------切片方式--------------------------- >>> print(li[0:3]) [1, 2, 3]
for循环方式查询:
>>> li = [1,2,3,4] >>> for n in li: ... print(n) ... 1 2 3 4
六、列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。

七、列表截取与拼接
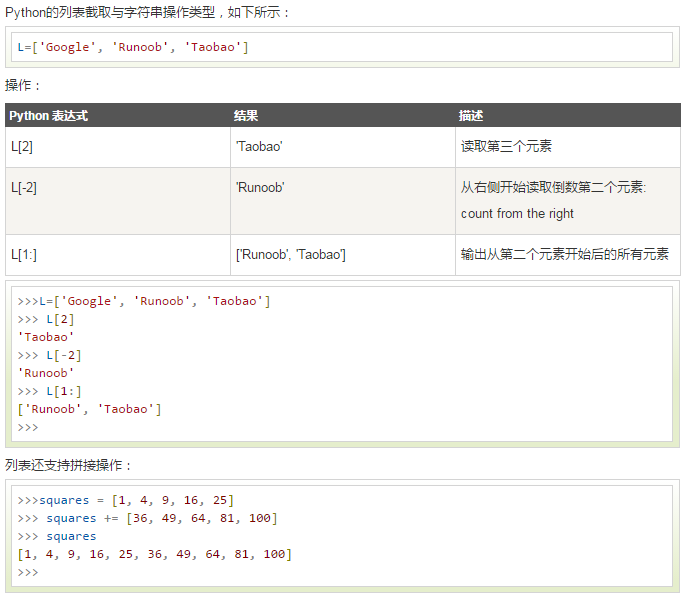
八、嵌套列表
使用嵌套列表即在列表里创建其它列表,通过降维. 一层一层看;
>>> li = ["a","b","c",[1,2,3],7,8,"d"] >>> print(li[1]) b >>> print(li[3]) [1, 2, 3] >>> print(li[3][2]) 3
九、列表内置函数
1.append(self, p_object)
说明:用于在列表末尾添加新的对象;
语法:list.append(obj)
参数:obj ----------> 添加到列表末尾的对象;
返回值:该方法无返回值,但是会修改原来的列表。
实例:
>>> li = [1,2,3] >>> li.append("abc") >>> print(li) [1, 2, 3, 'abc']
2.clear(self)
说明:用于清空列表,类似于 del a[:]
语法:list.clear()
实例:
>>> print(li) [1, 2, 3, 'abc'] >>> li.clear() >>> print(li) []
3.copy(self)
说明:用于浅复制列表,类似于 a[:];
语法:list.copy()
返回值:返回复制后的新列表;
实例:
>>> li1 = ["a","b",[1,2,3],"c"] >>> li2 = li1.copy() >>> print(li2) ['a', 'b', [1, 2, 3], 'c'] >>> print(id(li1),id(li2)) 139844385179656 139844384906184
#可以看出两个列表的内存地址是不一样的 >>> print(id(li1[2][0]),id(li2[2][0])) 139844383671616 139844383671616
#可以看出里面的内容地址是一样的
4.count(self, value)
说明:用于统计某个元素在列表中出现的次数
语法:list.count(obj)
参数:obj -------> 列表中统计的对象;
返回值:返回元素在列表中出现的次数;
实例:
>>> li = ["a","b","c","a",1,8,"a"] >>> print(li.count("a")) 3
5.extend(self, iterable)
说明:用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表);
语法:list.extend(seq)
参数:seq --------> 元素列表,必须是一个可迭代对象;
返回值:该方法没有返回值,但会在已存在的列表中添加新的列表内容。
实例:
>>> li = [1,2,3,4] >>> li2 = [5,6,7,8] >>> li.extend(li2) >>> print(li) [1, 2, 3, 4, 5, 6, 7, 8]
6.index(self, value, start=None, stop=None)
说明:用于从列表中找出某个值第一个匹配项的索引位置。
语法:list.index(value)
参数:value --------> 查找的对象;
返回值:返回查找对象的索引位置,如果没有找到对象则抛出异常;
实例:
>>> li = ["a","b","c","a"] >>> print(li.index("a")) 0
>>> print(li.index("a",1))
3
7.insert(self, index, p_object)
说明:用于将指定对象插入列表的指定位置;
语法:list.insert(index,p_object)
参数:index ------> 对象p_object需要插入的索引位置;
p_object ----> 要插入列表中的对象;
返回值:该方法没有返回值,但会在列表指定位置插入对象;
实例:
>>> li = ["a","b","c","a"] >>> li.insert(1,"尼玛的") >>> print(li) ['a', '尼玛的', 'b', 'c', 'a']
8.pop(self, index=None)
说明:用于根据索引移除列表中的一个元素(默认最后一个元素),并且返回该元素的值,相当于剪切;
语法:list.pop(index)
参数:index -------> 可选参数,要移除列表元素的索引值,不能超过列表总长度,默认为 index=-1,删除最后一个列表值;
返回值:该方法返回从列表中移除的元素对象;
实例:
>>> li = ["a","b","c","a"] >>> a = li.pop(2) >>> print(li) ['a', 'b', 'a'] >>> print(a) c
9.remove(self, value)
说明:用于根据元素值移除列表中某个值的第一个匹配项;
语法:list.remove(value)
参数:value --------> 列表中要移除的元素
返回值:该方法没有返回值但是会移除两种中的某个值的第一个匹配项。
实例:
>>> li = ["a","b","c","a"] >>> a = li.remove("a") >>> print(li) ['b', 'c', 'a']
10.reverse(self)
说明:用于反向列表中元素;
语法:list.reverse()
返回值:该方法没有返回值,但是会对列表的元素进行反向排序;
实例:
>>> li = ["a","b","c","a"] >>> li.reverse() >>> print(li) ['a', 'c', 'b', 'a']
11.sort(self, key=None, reverse=False)
说明:用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数
语法:list.sort(key=None, reverse=False)
参数:key ------> 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -----> 指定排序规则,默认为升序,reverse = True 降序, reverse = False 升序(默认);
返回值:该方法没有返回值,但是会对列表的对象进行排序;
实例:
>>> li = ["Ack","Ync","seq"] >>> li.sort(reverse = True) >>> print(li) ['seq', 'Ync', 'Ack']
元祖类型(tuple)
-
元祖定义
-
索引和切片
-
查询元组元素
-
元组的连接组合
-
删除整个元组
-
元组的运算符
-
元组内置函数
-
range()-Python内置函数简单说明
一、元组定义
Python 的元组与列表类似,不同之处在于元组的元素不能修改,不能删除,不能新增,只能读取;也被称为只读列表
元组的表达形式:使用 ( ) 表示元组;
如果元组中只有一个元素,则表现形式为:(元素,)因为元组中只包含一个元素时,如果不加逗号,会被当作运算符使用;
空元组的表达形式:tuple()
元组是一个可迭代对象,有__iter__方法;
例子:
>>> tu1 = (50) >>> print(type(tu1)) <class 'int'> >>> tu2 = (50,) >>> print(type(tu2)) <class 'tuple'> >>> tu3 = tuple() >>> print(type(tu3)) <class 'tuple'>
二、索引和切片
元组的索引和切片的使用方式和字符串以及列表的索引切片使用方式是一样的;
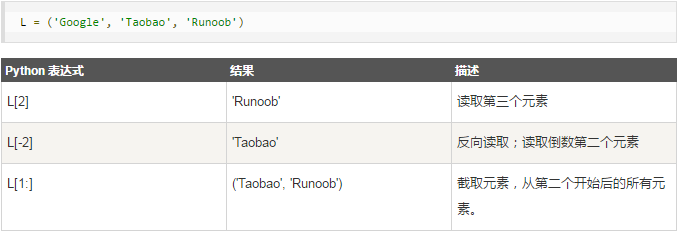
三、查询元组元素
可以通过索引或切片来访问元组中的值;
例子:
>>> tu1 = (1,2,3,4,"a","b","c") >>> print(tu1[4]) a >>> print(tu1[2:6]) (3, 4, 'a', 'b') >>> print(tu1[0:6:2]) (1, 3, 'a') >>> print(tu1[6:0:-2]) ('c', 'a', 3)
四、元组的连接组合
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例:
>>> tu1 = (1,2,3,4,5) >>> tu2 = ("a","b","c","d","e",) >>> tu3 = tu1 + tu2 >>> print(tu3) (1, 2, 3, 4, 5, 'a', 'b', 'c', 'd', 'e')
五、删除整个元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
>>> tu1 = (1,2,3,4,5) >>> print(tu1) (1, 2, 3, 4, 5) >>> del tu1 >>> print(tu1) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'tu1' is not defined
六、元组的运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。

七、元组的内置函数
1.count(self, value)
说明:记录所要搜索的value在元组中出现的次数;
语法:tuple.count(value)
参数:value -------------> 搜索的元素
返回值:返回被搜索元素出现在元组中的次数,没有则返回0;
实例:
>>> tu1 = ("a","b","d","a","d","a")>>> print(tu1.count("a")) 3 >>> print(tu1.count("p")) 0
2.index(self, value, start=None, stop=None)
说明:用于从元组中找出某个值第一个匹配项的索引位置。
语法:tuple.index(value, start=None, stop=None)
参数:value -----------> 搜素的元素;
start ------------> 起始位置;
end ------------> 结束位置;
返回值:若存在此元素,则返回次元素所在的索引位置,否则报错,提示找不到该元素;
实例:
>>> tu1 = ("a","b","d","a","d","a") >>> print(tu1.index("a")) 0 >>> print(tu1.index("b")) 1 >>> print(tu1.index("p")) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: tuple.index(x): x not in tuple
八、range()-Python内置函数简单说明
range()的使用方式相当于切片;
range(n) 从0到n-1
range(m,n) 从m到n-1
range(m,n,q) 从m到n-1 每q个取1个
使用for循环和range来获取列表或元组中的索引:
for n in range(len(tuple)):
print(tuple[n)
注意:
Python2中的range(1,10),可以被print()直接打印出列表[1,2,3,4,5,6,7,8,9]
Python3中的range(1,10),被print()打印后输出为,range(1,10)
字典类型(dict)
-
字典数据类型介绍
-
字典键值对的增加
-
字典键值对的删除
-
字典键值对的修改
-
字典键值对的查看
-
字典键的特性
-
字典的嵌套
-
字典的内置方法
-
解构(解包)和封装
一、字典数据类型介绍
字典是Python中唯一的一个映射类型,它是以 { } 扩起来的键值对组成的{key:value};在字典中key是唯一的,在保存的时候,根据key来计算出一个内存地址,然后将key-value保存在这个地址中,这种算法被称为hash算法,所以,切记,在dict中存储的key-value中的key必须是可hash的;
字典是一个可变的无序的可以存储任何类型的类型;
字典中的key都必须是可哈希的,不可变的数据类型;
字典中的值没有限制,可以是任何数据类型;
一个简单的字典实例:
>>> dic = {"name":"zjk","age":18}
二、字典键值对的增加
字典中的键值对增加有两个基本方式:dict[key] = value dict.setdefault(key,value)
1.dict[key] = value
实例:
>>> dic = {"name":"zjk","age":18}
>>> dic["like"] = [1,2,3]
>>> print(dic)
{'name': 'zjk', 'age': 18, 'like': [1, 2, 3]}
2.dict.setfefault(key,value)
说明:如果键在字典中存在不进行任何操作,否则就添加;
实例:
>>> dic = {"name":"zjk","age":18}
>>> dic.setdefault("home","wuan")
'wuan'
>>> print(dic)
{'name': 'zjk', 'age': 18, 'home': 'wuan'}
三、字典键值对的删除
删除键值对的四种方法:pop(key),del dic[key]、popitem()、clear()
1.dict.pop(key)
说明:删除键值对,有返回值,返回的是被删除的key的value;
>>> dic = {"name":"zjk","age":18}
>>> a = dic.pop("age")
>>> print(a,dic)
18 {'name': 'zjk'}
2.del dict[key]
说明:通过key删除
实例:
>>> dic = {"name":"zjk","age":18}
>>> del dic["name"]
>>> print(dic)
{'age': 18}
3.dict.popitem()
说明:随机删除,默认删除最后一个,(还在测试中)
实例:
>>> dic = {"name":"zjk","age":18}
>>> dic.popitem()
('age', 18)
>>> print(dic)
{'name': 'zjk'}
>>> dic = {"name":"zjk","age":18}
>>> a = dic.popitem()
>>> print(dic,a)
{'name': 'zjk'} ('age', 18)
4.dic.clear()
说明:清空字典;
实例:
>>> dic = {"name":"zjk","age":18}
>>> dic.clear()
>>> print(dic)
{}
四、字典键值对的修改
修改字典两种方法:dic[key] = value dic.update(字典)
1.dic[key] = value
实例:
>>> dic = {"name":"zjk","age":18}
>>> dic["name"] = "lalala"
>>> print(dic)
{'name': 'lalala', 'age': 18}
2.dic.update(字典)
说明:将一个字典导入到另一个字典中,新的数据会覆盖旧的数据;
实例:
>>> dic = {"name":"zjk","age":18}
>>> dic1 = {"home":"wuan","age":23,"high":"66666"}
>>> dic.update(dic1)
>>> print(dic)
{'name': 'zjk', 'age': 23, 'home': 'wuan', 'high': '66666'}
五、字典键值对的查看
查看字典的几种方法:for循环、dic[key]、get(key)、setfault(key)
1.for循环
实例:
>>> dic = {"a":1,"b":2,"c":3,"d":4,"e":5}
>>> for n in dic:
... print(n)
...
a
b
c
d
e
>>> for n in dic.values():
... print(n)
...
1
2
3
4
5
>>> for n in dic.items():
... print(n)
...
('a', 1)
('b', 2)
('c', 3)
('d', 4)
('e', 5)
2.dict[key]
说明:如果key在字典中存在,则返回对应key的value值,如果key不存在,则报错;
实例:
>>> dic = {"a":1,"b":2,"c":3,"d":4,"e":5}
>>> print(dic["a"])
1
>>> print(dic["b"])
2
>>> print(dic["aaa"])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'aaa'
3.dict.get(key,default=None)
说明:返回指定键的值,如果值不在字典中则返回default值;
实例:
>>> dic = {"a":1,"b":2,"c":3,"d":4,"e":5}
>>> print(dic.get("a"))
1
>>> print(dic.get("aaa"))
None
>>> print(dic.get("aaa","66666"))
66666
4.dict.setfault(key,dafault)
说明:和get类似,如果键存在的话返回键对应的值,但如果键不存在的话,将会在字典中添加键并将值设为default;
实例:
>>> dic = {"a":1,"b":2,"c":3,"d":4,"e":5}
>>> print(dic.setdefault("a","888"))
1
>>> print(dic.setdefault("aaaa","888"))
888
>>> print(dic)
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'aaaa': '888'}
六、字典键的特性
字典值可以是任何的 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行;
不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
>>> dic = {"a":1,"b":2,"c":3,"a":4}
>>> print(dic["a"])
4
七、字典键的嵌套
字典里可以无限嵌套,字典也可以嵌套字典:
dic = { 'name':'汪峰', 'age':43, 'wife':{ 'name':'国际章', 'age':39, 'salary':100000 }, 'baby':[ {'name':'熊大','age':18}, {'name':'熊二','age':15}, ] }
八、字典键的内置方法
1.clear(self)
说明:用于删除字典内所有元素,清空字典;
语法:dict.clear()
实例:
>>> dic = {"a":1,"b":2,"c":3}
>>> dic.clear()
>>> print(dic)
{}
2.copy(self)
说明:返回一个字典的浅复制,将字典进行复制;
语法:dcit.copy()
返回值:返回一个字典的浅复制;
实例:
>>> dic = {"name":"zjk","age":23}
>>> dic1 = dic.copy()
>>> print(dic1)
{'name': 'zjk', 'age': 23}
3.fromkeys(*args, **kwargs)
说明:用于创建一个新字典,以序列seq中元素做字典的键,value为字典所有键对应的初始值;
语法:dict.fromkeys(*args, **kwargs)
返回值:该方法返回字典;
实例:
>>> li = ["name","age","like"] >>> a = dict.fromkeys(li,"666") >>> print(a) {'name': '666', 'age': '666', 'like': '666'} >>> print(type(a)) <class 'dict'>
需要注意的是,由fromkeys生成的新字典中,所有的key都是共享的一个value,如果所这个被共享的value是一个可变类型,
1.----------------- 当共享的value是一个可哈希的数据类型时,该字典中的某个key的值被修改,不会影响其他key的value-------------------- >>> li = ["name","age","like"] >>> a = dict.fromkeys(li,"666") >>> a {'name': '666', 'age': '666', 'like': '666'} >>> a["age"] = "777" >>> a {'name': '666', 'age': '777', 'like': '666'} 2.----------------当共享的value是一个可变的数据类型时,该字典中的某个key的值被修改后,其他key的值都会被修改 ---------------------------- >>> li1 = ["name","age","like"] >>> a = dict.fromkeys(li,[111,222]) >>> a {'name': [111, 222], 'age': [111, 222], 'like': [111, 222]} >>> a["like"].append(333) >>> a {'name': [111, 222, 333], 'age': [111, 222, 333], 'like': [111, 222, 333]}
那么,如果其中有个key的值进行了改变,那么该字典中所有的value都会被改变;
例如:
4.get(self, k, d=None)
说明:返回指定键的值,如果值不在字典中返回默认值。默认值为None;
语法:dict.get(key,default=None)
参数:key ------> 字典中要查找的键;
default ------> 如果指定的值不存在,返回该默认值;
返回值:返回指定键的值,如果值不在字典中返回默认值 None;
实例:
>>> dic = {"name":"zjk","age":23}
>>> print(dic.get("name"))
zjk
>>> print(dic.get("name11"))
None
>>> print(dic.get("name11","888"))
888
5.items(self)
说明:以列表形式返回可遍历的(键, 值) 元组数组;
语法:dict.items()
返回值:返回可遍历的(键, 值) 元组数组;
实例:
>>> dic = {"name":"zjk","age":23}
>>> print(dic.items())
dict_items([('name', 'zjk'), ('age', 23)])
6.in操作符
说明: in 操作符用于判断键是否存在于字典中,如果键在字典dict里返回true,否则返回false。
语法:key in dict
参数:key -------> 要在字典中查找的键;
返回值:如果键在字典里返回true,否则返回false;
实例:
>>> dic = {"name":"zjk","age":23}
>>> if "name" in dic:
... print(666)
... else :
... print(111)
...
666
>>> if "hahaha" in dic:
... print(666)
... else :
... print(111)
...
111
7.keys(self)
说明:以列表返回一个字典所有的键;
语法:dict.keys()
返回值:返回一个字典所有的键。
实例:
>>> dic = {"name":"zjk","age":23}
>>> print(dic.keys())
dict_keys(['name', 'age'])
8.pop(self, k, d=None)
说明:删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
语法:dict.pop(k, d=None)
参数:key ----------> 要删除的键值;
default -------> 如果没有key,返回default值
返回值:返回被删除的value值
实例:
>>> dic = {"name":"zjk","age":23}
>>> a = dic.pop("age")
>>> print(dic,a)
{'name': 'zjk'} 23
>>>
>>> dic = {"name":"zjk","age":23}
>>> print(dic.pop("aaaaa","666"))
666
9.popitem(self)
说明:随机返回并删除字典中的一对键和值(一般删除末尾对);如果字典已经为空,却调用了此方法,就报出KeyError异常;
语法:dcit.popitem()
返回值:返回一个键值对(key,value)形式。是一个元组类型;
实例:
>>> dic = {"name":"zjk","age":23}
>>> b = dic.popitem()
>>> print(dic,b)
{'name': 'zjk'} ('age', 23)
>>> dic = {} >>> b = dic.popitem() Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'popitem(): dictionary is empty'
10.setdefault(self, k, d=None)
说明:setdefault() 方法和get()方法类似, 如果键不已经存在于字典中,将会在字典中添加键并将值设为默认值。
语法:dict.setdefault(key, default=None)
参数:key -----------> 查找的键值;
default -------> 键不存在时,设置的默认键值;
返回值:如果 key 在 字典中,返回对应的值。如果不在字典中,则插入 key 及设置的默认值 default,并返回 default ,default 默认值为 None。
实例:
>>> dic = {"name":"zjk","age":23}
>>> print(dic.setdefault("name"))
zjk
>>> print(dic.setdefault("aaaaa"))
None
>>> print(dic.setdefault("bbbbb","6666"))
6666
>>> print(dic)
{'name': 'zjk', 'age': 23, 'aaaaa': None, 'bbbbb': '6666'}
11.update(self, E=None, **F)
说明:把字典参数 dict2 的 key/value(键/值) 对更新到字典 dict 里,如果有相同的键值进行替换;
语法:dict.update(dict2)
参数:dict2 -----> 添加到指定字典dict里的字典。
实例:
>>> dic = {"name":"zjk","age":23}
>>> dic1 = {"a":1,"b":2,"age":18}
>>> dic.update(dic1)
>>> print(dic)
{'name': 'zjk', 'age': 18, 'a': 1, 'b': 2}
12.values(self)
说明:以列表返回字典中的所有值;
语法:dict.values()
返回值:返回字典中的所有值;
实例:
>>> print(dic) {'name': 'zjk', 'age': 18, 'a': 1, 'b': 2} >>> print(dic.values()) dict_values(['zjk', 18, 1, 2])
九、解构(解包)和封装
元素在左边是解构,元素在右边是封装;
封装的定义:将多个值使用逗号分隔,组合在一起;本质上返回一个元组,只是省略了小括号;Python特有语法,被很多语言学习和借鉴;
解构的定义:按照元素顺序,把线性解构的元素,赋值给变量;
Python3中的解构变化:
通过使用星号 * 加上变量,可以接受所有元素;
不能单一的使用星号作为变量接收,如果可以,相当于lst[0:0]
同一个解构中,只能使用一个星号;
当左边变量超过右边元素个数的时候,是不允许的;
两大用法:
对称性赋值:
对称性赋值在很多情况下被称为解构,其实只是解构的一小部分;
把线性结果(包括字典和list等)的元素解开,并按顺序赋值给其他变量;
左边接收的变量数要和右边解开的元素个数一致;
通常用在x,y = y,x 相当于将y,x先封装为一个元组(y,x),等价于x,y = (y,x),然后依据位置参数进行依次赋值。
简化添加类型:
极大的简化了“添加”的类型,比如结合字典,并且以明确的方式进行:
例如:

实例:
>>> a,b = 1,2 >>> print(a,b) 1 2 >>> a,b = (1,2) >>> print(a,b) 1 2 >>> a,b = [1,2] >>> print(a,b) 1 2 >>> a,b = {1,2} >>> print(a,b) 1 2 >>> a,b = {"a":1,"b":2} >>> print(a,b) a b >>> >>> >>> >>> a,*b = {1,2,3} >>> print(a,b) 1 [2, 3] >>> a,*b,c = {1,2,3,4,5,6,7,8} >>> print(a,b,c) 1 [2, 3, 4, 5, 6, 7] 8
集合类型(set)
-
集合定义
-
集合-增加元素
-
集合-删除元素
-
集合-查看元素
-
交集
-
并集
-
差集
-
反交集
-
子集与超集
-
set内置函数
-
frozenset不可变集合,让集合变成不可变类型;
一、集合定义
集合(set)是一个无序的、元素不重复的序列;
集合的元素都是不可变类型的
使用大括号 { } 或者set()函数创建,注意:创建一个空集合必须使用set()而不是 { },因为 { } 是用来创建一个空字典;
创建集合:
se = {"a","b","c",(1,2,3)}
se1 = set("123")
se2 = set((1,2,3,4,5,))
print(se)
print(se1)
print(se2)
---------------------输出结果----------------------------------
{'c', 'b', 'a', (1, 2, 3)}
{'3', '1', '2'}
{1, 2, 3, 4, 5}
二、集合-增加元素
1.s.add(x)
说明:将元素x添加到集合s中,如果元素已存在,则不进行任何操作;
实例:
se = set(("zjk","china","beijing")) se.add("hello world") print(se) --------------------输出结果--------------------- {'beijing', 'china', 'zjk', 'hello world'}
2.s.update(x)
说明:添加元素,参数可以是列表,元组、字典等;
实例:
se = {"a","b","c","d","e"}
se.update([1,2,3,4,5])
print(se)
-------------输出结果-------------------
{'a', 1, 2, 3, 'e', 'b', 4, 5, 'c', 'd'}
三、集合-删除元素
1.s.remove(x)
说明:将元素x从集合s中删除,如果该元素不存在,则报错;
实例:
se = {"a","b","c","d","e"}
se.remove("d")
print(se)
----------------输出结果---------------------
{'e', 'b', 'a', 'c'}
se = {"a","b","c","d","e"}
se.remove("dddd")
print(se)
-----------------输出结果------------------
Traceback (most recent call last):
File "C:/Users/Administrator/Desktop/123.py", line 2, in <module>
se.remove("dddd")
KeyError: 'dddd'
2.s.discard(x)
说明:将元素x从集合中删除,如果该元素不存在,不会发生错误并返回当前集合
实例:
se = {"a","b","c","d","e"}
se.discard("e")
print(se)
------------------输出结果-----------------------
{'d', 'a', 'b', 'c'}
se = {"a","b","c","d","e"}
se.discard("eeee")
print(se)
-----------------------输出结果-------------------
{'b', 'c', 'd', 'a', 'e'}
3.pop()
说明:随机删除集合的一个元素,并返回这个被删除的元素;
实例:
se = {"a","b","c","d","e"}
a = se.pop()
print(se,a)
-----------------输出结果-------------------
{'c', 'b', 'e', 'a'} d
4.s.clear()
说明:清空集合s
实例:
se = {"a","b","c","d","e"}
se.clear()
print(se)
------------输出结果---------------
set()
四、集合-查看元素
通过for循环遍历集合的元素;
实例:
>>> se = {"a","b","c",(1,2,3,4)}
>>> for n in se:
... print(n)
...
a
(1, 2, 3, 4)
c
b
五、交集(& 或者 intersection)
>>> se1 = {1,2,3,4,5}
>>> se2 = {4,5,6,7,8}
>>> print(se1 & se2)
{4, 5}
>>> print(se1.intersection(se2))
{4, 5}
六、并集(| 或者 union)
>>> se1 = {1,2,3,4,5}
>>> se2 = {4,5,6,7,8}
>>> print(se1 | se2)
{1, 2, 3, 4, 5, 6, 7, 8}
>>> print(se2.union(se1)
... )
{1, 2, 3, 4, 5, 6, 7, 8}
七、差集(- 或者 difference)
>>> se1 = {1,2,3,4,5}
>>> se2 = {4,5,6,7,8}
>>> print(se1 - se2)
{1, 2, 3}
>>> print(se1.difference(se2))
{1, 2, 3}
八、反交集(^ 或者 symmetric_difference)
>>> se1 = {1,2,3,4,5}
>>> se2 = {4,5,6,7,8}
>>> print(se1 ^ se2)
{1, 2, 3, 6, 7, 8}
>>> print(se1.symmetric_difference(se2))
{1, 2, 3, 6, 7, 8}
九、子集与超集
>>> se1 = {1,2,3}
>>> se2 = {1,2,3,4,5,6}
>>> print(se1 < se2)
True
>>> print(se1.issubset(se2))
True
#这两个用法相同,都是说明se1是se2的子集
>>> print(se2 > se1)
True
>>> print(se2.issuperset(se1))
True
#这两个都相同,都是说明se2是se1超集。
十、set内置函数
1.add(self, *args, **kwargs)
说明:向集合中添加元素;
语法:set.add(*args, **kwargs)
实例:
>>> se1.add(4) >>> se1 = {1,2,3} >>> se1.add(4) >>> print(se1) {1, 2, 3, 4}
2.clear(self, *args, **kwargs)
说明:清空集合;
语法:set.clear()
实例:
>>> se1 = {1,2,3}
>>> se1.clear()
>>> print(se1)
set()
3.copy(self, *args, **kwargs)
说明:返回集合的浅拷贝;
语法:set.copy()
实例:
>>> se1 = {1,2,3,(4,5,6)}
>>> se2 = se1.copy()
>>> print(se2)
{1, 2, 3, (4, 5, 6)}
4.difference(self, *args, **kwargs)
说明:将两个或多个集合的差集作为一个新集合返回;
语法:se1.difference(se2)
实例:
>>> se1 = {1,2,3,4,5}
>>> se2 = {4,5,6,7,8}
>>> print(se1 - se2)
{1, 2, 3}
>>> print(se1.difference(se2))
{1, 2, 3}
5.difference_update(self, *args, **kwargs)
说明:从这个集合中删除另一个集合的所有元素
语法:set.difference_update(set1)
实例:
>>> s = {1,2,3}
>>> s1 = {1,2,3,4}
>>> s2 = {2,3}
>>> s.difference_update(s2)
>>> s
{1}
>>> s1.difference_update(s2)
>>> s1
{1, 4}
6.discard(self, *args, **kwargs)
说明:删除集合中的一个元素,如果该元素不存在,则不执行任何操作;
语法:set.discard(x)
实例:
>>> s1 = {1,2,3,4}
>>> s1.discard(3)
>>> s1
{1, 2, 4}
>>> s1.discard("a")
>>> s1
{1, 2, 4}
7.intersection(self, *args, **kwargs)
说明:将两个集合的交集作为一个新集合返回
语法:set.intersection(set1)
实例:
>>> s1 = {1,2,3,4}
>>> s2 = {3,4,5,6}
>>> s3 = s1.intersection(s2)
>>> s3
{3, 4}
8.intersection_update(self, *args, **kwargs)
说明:用自己和另一个的交集来更新这个集合;
语法:s.intersection_upfate(s2)
实例:
>>> s = {"a","b","c","d","e"}
>>> s1 = {"c","d","e","e","f","g"}
>>> s.intersection_update(s1)
>>> s
{'d', 'c', 'e'}
9.isdisjoint(self, *args, **kwargs)
说明:如果两个集合有一个空交集,返回True
语法:set.isdisjoint(set1)
实例:
>>> s = {1,2}
>>> s1 = {3,4}
>>> s2 = {2,3}
>>> s.isdisjoint(s1)
True
>>> s.isdisjoint(s2)
False
10.issubset(self, *args, **kwargs)
说明:如果另一个集合包含这个集合,返回True
语法:s.issubset(set1)
实例:
>>> s = {1,2,3}
>>> s1 = {1,2,3,4}
>>> s2 = {2,3}
>>> s.issubset(s1)
True
>>> s.issubset(s2)
False
>>> s2.issubset(s)
True
11.issuperset(self, *args, **kwargs)
说明:如果这个集合包含另一个集合,返回True;
语法:s.issuperset(s1)
实例:
>>> s = {1,2,3}
>>> s1 = {1,2,3,4}
>>> s2 = {2,3}
>>> s1.issuperset(s)
True
>>> s.issuperset(s2)
True
>>> s2.issuperset(s1)
False
12.pop(self, *args, **kwargs)
说明:删除并返回任意的集合元素(如果集合为空,会引发KeyError)
语法:s.pop()
实例:
>>> s = {1,2,3,4,5,6}
>>> s.pop()
1
>>> s
{2, 3, 4, 5, 6}
13.remove(self, *args, **kwargs)
说明:删除集合中的一个元素(如果元素不存在,会引发KeyError)
语法:set.remove(x)
实例:
>>> s = {1,2,3,4,5,6}
>>> s.remove(4)
>>> s
{1, 2, 3, 5, 6}
>>> s.remove(99)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 99
>>> s
{1, 2, 3, 5, 6}
14.symmetric_difference(self, *args, **kwargs)
说明:将两个集合的对称差作为一个新集合返回(两个集合合并删除相同部分,其余保留)
语法:s.symmetric_difference(s1)
实例:
>>> s1 = {1,2,3,4,5,6,7,8}
>>> s2 = {3,4,5,6,7,8,9,10}
>>> s1.symmetric_difference(s2)
{1, 2, 9, 10}
>>> s2.symmetric_difference(s1)
{1, 2, 9, 10}
15.symmetric_difference_update(self, *args, **kwargs)
说明:用自己和另一个的对称差来更新这个集合
语法:s.symmetric_difference_update(s1)
实例:
>>> s = {1,2,3}
>>> s1 = {1,2,3,4}
>>> s2 = {2,3}
>>> s1.symmetric_difference_update(s)
>>> s1
{4}
>>> s1.symmetric_difference_update(s2)
>>> s1
{2, 3, 4}
>>> s.symmetric_difference_update(s2)
>>> s
{1}
15.union(self, *args, **kwargs)
说明:将集合的并集作为一个新集合返回;
语法:s.union(s1)
实例:
>>> s = {1,2,3,4,5,6}
>>> s1 = {3,4,5,6,7,8}
>>> print(s.union(s1))
{1, 2, 3, 4, 5, 6, 7, 8}
>>> print(s|s1)
{1, 2, 3, 4, 5, 6, 7, 8}
16.update(self, *args, **kwargs)
说明:用自己和另一个的并集来更新这个集合;
语法:s.update(*args, **kwargs)
实例:
>>> s = {"p","y"}
>>> s.update("t","h","o","n")
>>> s
{'p', 'h', 't', 'n', 'y', 'o'}
>>> s.update(["q","e"],{"l","l","o"})
>>> s
{'q', 'p', 'h', 't', 'n', 'y', 'o', 'e', 'l'}
字符串类型(str)
-
字符串说明
-
索引和切片
-
转义字符
-
字符串运算符
-
字符串格式化
-
字符串内置的函数
一.字符串说明
字符串是 Python 中最常用的数据类型。我们可以使用引号('或")来创建字符串。
字符串是不可变的数据类型,不论执行任何操作,源字符串是不会改变的,每次操作都会返回新字符串;
创建字符串,只需要为变量赋值即可,如:Str = "hello world"
字符串在转换成int时,如果字符串中的数字有空格,则在转换时自动去除空格;
访问字符串中的值:
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
>>> print("hello world") hello world
字符串更新:
可以截取字符串的一部分并与其他字段拼接,如下实例:
>>> print("hello world" + " 你好,中国") hello world 你好,中国
二、索引和切片
1.索引
说明:通过索引取出字符串对应的值
格式:str[下标]
参数:下标 ------ > 是一个int型数据,
索引从0开始,使用[下标]可以获取到每一个字符,还可以倒着数,最后一个字符用-1表示,一次往前数是-1、-2...
返回值:返回字符串对应索引所对应的值;如果索引超出边界则报错
实例:
>>> s = "abcdefg" >>> print(s[0]) a >>> print(s[1]) b >>> print(s[2]) c >>> print(s[3]) d >>> print(s[4]) e >>> print(s[5]) f >>> print(s[6]) g
----------------索引超出边界,报错---------------------------------
>>> print(s[7])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
2.切片
说明:通过切片取出字符串的一段字符;
格式:str[起始位置:结束位置:步长]
参数:起始位置 --------> 表示从哪个下标开始
结束位置 --------> 表示到哪个下标结束
步长 --------------> 默认从左到右,步长为1,也可以取反,表示倒叙,步长取负数
特点:顾头不顾尾,从start开始截取. 截取到end位置. 但不包括end
返回值:返回一个由切片选择好的子串;
实例:
>>> s = "abcdefg" >>> print(s[:]) abcdefg >>> print(s[0:4]) abcd >>> print(s[2:6]) cdef >>> print(s[:6:2]) ace >>> print(s[1::2]) bdf >>> print(s[::-1]) gfedcba >>> print(s[-1:-3]) >>> print(s[-1:-3:-1]) gf >>> print(s[-1::-2]) geca
三.转义字符
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
四.字符串运算符
下表实例变量a值为字符串 "Hello",b变量值为 "Python":
五.字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
>>> print("中国的首都是%s" % ("北京")) 中国的首都是北京
python字符串格式化符号:
格式化操作符辅助指令:
六.字符串内置的函数
1.capitalize(self)
说明:将字符串的第一个字符转换为大写,其他字母变成小写;注意的是并不会改变原字符串内容;
语法:str.capitalize()
返回值:该方法返回一个首字母大写的字符串;
实例:
>>> S = "hello WoRld" >>> print(S.capitalize()) Hello world
2.casefold(self)
说明:将字符串中的所有大写字符转换为小写字符;并支持识别东欧的一些字母;lower不支持东欧的字母;
语法:str.casefold()
返回值:返回将字符串中所有大写字符转换为小写后生成的字符串;
实例:
>>> S = "hello WoRld" >>> print(S.casefold()) hello world
3.center(self, width, fillchar=None)
说明:返回一个指定的宽度width且居中的字符串,字符串长度为width,fillchar为填充的字符,默认为空格;
语法:str.center(width,fillchar)
返回值:返回一个指定的宽度 width 居中的字符串,如果 width 小于字符串宽度直接返回字符串,否则使用 fillchar 去填充。
实例:
>>> print("今日头条".center(40,"*")) ******************今日头条******************
4.count(self, sub, start=None, end=None)
说明:用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
语法:str.count(sub,start=None, end=None)
参数:sub -----> 要搜索的子字符串;
start -----> 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0;
end ------> 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置;
返回值:返回子字符串在字符串中出现的次数;
实例:
>>> print(ss.count("a")) 2 >>> print(ss.count("a",0,8)) 1
5.encode(self, encoding='utf-8', errors='strict')
说明:以指定的编码格式来编码字符串。errors参数可以指定不同的错误处理方案。
语法:str.encode(encoding='utf-8', errors='strict')
参数:encoding -----> 要使用的编码,如:UTF-8
errors -----> 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
返回值:返回编码后的字符串,是一个 bytes 对象
实例:
>>> abc = "灯火阑珊" >>> abc_utf8 = abc.encode("UTF-8") >>> abc_gbk = abc.encode("GBK") >>> print(abc) 灯火阑珊 >>> print(abc_utf8) b'\xe7\x81\xaf\xe7\x81\xab\xe9\x98\x91\xe7\x8f\x8a' >>> print(abc_gbk) b'\xb5\xc6\xbb\xf0\xc0\xbb\xc9\xba'
6.decode(self, decoding='utf-8', errors='strict')
说明:以指定的编码格式来解码字符串。errors参数可以指定不同的错误处理方案。
语法:bytes.decode(encoding="utf-8", errors="strict")
参数:encoding -----> 要使用的编码,如:UTF-8
errors -----> 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
返回值:返回解码后的字符串;
实例:
>>> print(abc_gbk.decode("GBK")) 灯火阑珊 >>> print(abc_utf8.decode("UTF-8")) 灯火阑珊
7.endswith(self, suffix, start=None, end=None)
说明:用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False;
语法:str.endswith(suffix,start=None, end=None)
参数:suffix -----> 该参数可以是一个字符串或者是一个元素;
start ------> 字符串中的开始位置;
end ------> 字符中结束位置
返回值:如果字符串含有指定的后缀返回True,否则返回False;
实例:
>>> end = "hello world" >>> print(end.endswith("ld")) True >>> print(end.endswith("ld",0,10)) False
8.expandtabs(self, tabsize=8)
说明:把字符串中的 tab 符号('\t')转为空格,tab 符号('\t')默认的空格数是 8;
注意:规则是这样的,如果设置空格数是8,则会从开头查询,每8个字符为一组,到有\t那组时,缺几个就补几个空格;
语法:str.expandtabs(tabsize=8)
参数:tabszie -----> 指定转换字符串中的 tab 符号('\t')转为空格的字符数;
返回值:返回字符串中的 tab 符号('\t')转为空格后生成的新字符串;
实例:
>>> ss = "this is \tstring example" >>> print(ss) this is string example
#this is 刚好8个,所以到\t这里自动在补8个空格;
>>> print(ss.expandtabs(0))
this is string example
#0自动没有
>>> print(ss.expandtabs(20))
this is string example
#this is \t是8个,设置的是20空格,所以还需在补12个空格
9.find(self, sub, start=None, end=None)
说明:检测字符串中是否包含子字符串 sub ,如果指定 start(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。
语法:str.find(sub, start=None, end=None)
参数:sub ------> 指定检索的字符串;
start -----> 指定开始索引位置,默认为0
end -----> 指定结束索引位置,默认为字符串长度,len(str)
返回值:如果包含子字符串返回开始的索引值,否则返回-1;
实例:
>>> str1 = "Life is too short for python" >>> print(str1.find("short")) 12 >>> print(str1.find("short",5,19)) 12
>>> print(str1.find("short",17,19))
-1
10.format(self, *args, **kwargs)
说明:format函数用于字符串的格式化,通过{}和:来代替%;传入的参数两种形式,一种是位置参数,一种是关键字参数;位置参数不受顺序约束,且可以为{},只要format里有相对应的参数值即可,参数索引从0开,传入位置参数列表可用*列表,关键字参数值要对得上,可用字典当关键字参数传入值,字典前加**即可,注意的是当位置参数和关键字参数混合使用时,位置参数一定要在关键字参数左边。
语法:str.format( *args, **kwargs)
参数:*args ------> 当传入的参数为列表时,可用*列表;
**kwargs -------> 可用字典当关键字参数传入值,字典前加**即可;
返回值:返回一个已经填充好的字符串。
例子:
------------------不设置指定位置,按默认顺序-------------------------- >>> str2 = "中国的城市有,{},{},{},{}" >>> print(str2.format("北京","上海","深圳","武安")) 中国的城市有,北京,上海,深圳,武安 ----------------设置指定位置------------------------------------------- >>> str2 = "中国的城市有,{3},{0},{2},{1}" >>> print(str2.format("北京","上海","深圳","武安")) 中国的城市有,武安,北京,深圳,上海 ------------------使用位置-列表形式--------------------------- >>> li = ["北京","上海","深圳","武安"] >>> print(str2.format(*li)) 中国的城市有,北京,上海,深圳,武安
-------------------使用关键字位置形式-------------------------
>>> print(str2.format(k2="北京",k3="上海",k1="深圳",k4="武安"}))
中国的城市有,深圳,北京,上海,武安
-------------------使用关键字位置字典形式------------------------- >>> print(str2.format(**{"k2":"北京","k3":"上海","k1":"深圳","k4":"武安"})) 中国的城市有,深圳,北京,上海,武安 -------------------使用混合模式-------------------------------- >>> str2 = "中国的城市有,{3},{0},{2},{1},{h}" >>> print(str2.format("北京","上海","深圳","武安",**{"h":"石家庄"})) 中国的城市有,武安,北京,深圳,上海,石家庄
也可以向.format()传入对象:
class test(): def __init__(self,asd): self.num = asd ming = test(6) print("ming的数字是:{0.num}".format(ming)) #{0.num}中的0是可选的表示指定位置 -------------------输出结果为------------------------------ ming的数字是:6
.format()的数字格式化:
>>> print("{:.2f}".format(3.1415926)) 3.14
下表展示了 str.format() 格式化数字的多种方法:
>>> print("{}对应的位置是{{0}}".format("zjk")) zjk对应的位置是{0}
11.format_map(self, mapping)
说明:类似于format,不同的是format_map只能使用关键字位置形式传入字典来进行;
语法:str.format_map(mapping)
参数:mapping -----> 必须是一个字典;
返回值:一个已经填充好的字符串;
实例:
>>> print("{name}对应的位置是{{0}}".format_map({"name":"zjk"})) zjk对应的位置是{0}
12.index(self, sub, start=None, end=None)
说明:检测字符串中是否包含子字符串 sub ,如果指定 start(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果sub不在 str中则会报一个异常,而find则是返回-1;
语法:str.index(sub,start=None, end=None)
参数:sub ------> 指定检索的子字符串;
start -----> 指定开始索引位置,默认为0;
end ------> 指定结束索引位置,默认为字符串的长度;
返回值:如果包含子字符串返回开始的索引值,否则抛出异常;
实例:
>>> str1 = "Life is too short for python" >>> print(str1.index("short")) 12 >>> print(str1.index("short",14)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: substring not found
13.isalnum(self)
说明:检测字符串是否由字母和数字组成;
语法:str.isalnum()
返回值:如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
实例:
>>> str1 = "helloworld" >>> print(str1.isalnum()) True >>> str2 = "hello world" >>> print(str2.isalnum()) False
14.isalpha(self)
说明:检测字符串是否只由字母组成;
语法:str.isalpha()
返回值:如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False;
实例:
>>> str1 = "python" >>> print(str1.isalpha()) True >>> str2 = "python3" >>> print(str2.isalpha()) False
15.isdecimal(self)
说明:检查字符串是否只包含十进制字符。这种方法只存在于unicode对象;注意:定义一个十进制字符串,只需要在字符串前添加 'u' 前缀即可。
语法:str.isdecimal()
返回值:如果字符串只包含十进制字符返回True,否则返回False
实例:
>>> str1 = u"zjk2018" >>> print(str1.isdecimal()) False >>> str2 = u"201807" >>> print(str2.isdecimal()) True
16.isdigit(self)
说明:检测字符串是否只由数字组成;
语法:str.isdigit()
返回值:如果字符串只包含数字则返回 True 否则返回 False;
实例:
>>> str1 = "zjk2018" >>> print(str1.isdigit()) False >>> str2 = "201807" >>> print(str2.isdigit()) True
17.isidentifier(self)
说明:判断是否为python中的标识符,也就是说是否符合python变量名语法;
语法:str.isidentifier()
返回值:如果字符串的内容符合python变量命名语法,则返回True,否则返回False;
实例:
>>> str1 = "zjk1" True >>> str2 = "666zjk" >>> str2.isidentifier() False >>> str3 = "变量名" >>> str3.isidentifier() True >>> str4 = "def" >>> str4.isidentifier() True
#python的关键字一样是合法的 >>> str5 = "88888" >>> str5.isidentifier() False
18.islower(self)
说明:检测字符串是否由小写字母组成;
语法:str.islower()
返回值:如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False;
实例:
>>> str1 = "Life is too short for python -zjk23" >>> print(str1.islower()) False >>> str2 = "life is too short for python -zjk23" >>> print(str2.islower()) True
19.isnumeric(self)
说明:检测字符串是否只由数字组成。这种方法是只针对unicode对象;注:定义一个字符串为Unicode,只需要在字符串前添加 'u' 前缀即可;
语法:str.isnumeric()
返回值:如果字符串中只包含数字字符,则返回 True,否则返回 False
实例:
>>> str1 = "zjk1995" >>> print(str1.isnumeric()) False >>> str2 = "1995" >>> print(str2.isnumeric()) True
20.isprintable(self)
说明:判断是否由可打印字符组成,回车符等一些特殊字符是不会打印显示在屏幕上的;
语法:str.isprintable()
返回值:如果字符串中所有内容都可打印则返回True,否则返回False;
实例:
>>> print("123\t4\t56".isprintable()) False >>> print("123\\t456".isprintable()) True
21.isspace(self)
说明:检测字符串是否只由空白字符组成;
语法:str.isspace()
返回值:如果字符串中只包含空格,则返回 True,否则返回 False;
实例:
>>> str1 = " " >>> print(str1.isspace()) True >>> str2 = " sdf sdf" >>> print(str2.isspace()) False
22.istitle(self)
说明:检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写;
语法:str.istitle()
返回值:如果字符串中所有的单词拼写首字母是否为大写,且其他字母为小写则返回 True,否则返回 False;
实例:
>>> str1 = "Life Is Too Short For Python" >>> print(str1.istitle()) True >>> str2 = "Life is Too short For PyThon" >>> print(str2.istitle()) False
23.isupper(self)
说明:检测字符串中所有的字母是否都为大写;
语法:str.isupper()
返回值:如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False;
实例:
>>> str1 = "LIFE IS TOO SHORT FOR PYTHON" >>> print(str1.isupper()) True >>> str2 = "LIFE Is TOO ShOrT FOR PYTHON" >>> print(str2.isupper()) False
24.join(self, iterable)
说明:用于将序列中的元素以指定的字符连接生成一个新的字符串;
语法:n.join(iterable)
参数:iterable ------> 要连接的元素序列;
n --------------> 指定用来连接的字符;
返回值:返回通过指定字符连接序列中元素后生成的新字符串;
实例:
>>> str1 = "zjk" >>> print("-".join(str1)) z-j-k
25.ljust(self, width, fillchar=None)
说明:返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串;
语法:str.ljust(width, fillchar=None)
参数:width ------> 指定字符串长度;
fillchar -----> 填充字符,默认为空格;
返回值:返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串;
实例:
>>> str1 = "I Love You" >>> print(str1.ljust(20,"*")) I Love You********** ------------当指定的填充长度小于原字符串长度时返回原字符串------- >>> str2 = "I Love You" >>> print(str1.ljust(10,"*")) I Love You
26.lower(self)
说明:转换字符串中所有大写字符为小写;
语法:str.lower()
返回值:返回将字符串中所有大写字符转换为小写后生成的字符串;
实例:
>>> str1 = "I Love You" >>> print(str1.lower()) i love you
27.lstrip(self, chars=None)
说明:用于截掉字符串左边的空格或指定字符,贪婪模式;
语法:str.lstrip( chars=None)
参数:chars ------> 指定截取的字符;
返回值:返回截掉字符串左边的空格或指定字符后生成的新字符串;
实例:
>>> str1 = "666666I66Love You" >>> print(str1.lstrip("6")) I66Love You
28.maketrans(self, *args, **kwargs)
说明:用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。两个字符串的长度必须相同,为一一对应的关系;
语法:str.maketrans(intab,outtab)
参数:intab -------> 需要转换的字符串;
outtab -----> 被转换的字符串;
返回值:返回的是一个字典,字典内容是字符串的ASCII码的序号,一一对应
实例:
>>> dat = str.maketrans("123","abc") >>> print(dat) {49: 97, 50: 98, 51: 99} -----------------解释-------------------------- 1 的ASCII码为 49 a 的ASCII码为 97
29.partition(self, sep)
说明:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串;
语法:str.partition(sep)
参数:sep ------> 指定分隔符
返回值:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串;
实例:
>>> str1 = "http://www.dhlanshan.cn" >>> print(str1.partition("//")) ('http:', '//', 'www.dhlanshan.cn') -----------如果指定的分隔符在字符串中有两个,则以最左侧为分隔符---------- >>> print(str1.partition(".")) ('http://www', '.', 'dhlanshan.cn')
30.replace(self, old, new, count=None)
说明:将字符串中的某子串进行替换,默认替换指定的所有子串;
语法:str.replace(old, new, count=None)
参数:old ------> 旧的子串;
new -----> 新的子串;
count ----> 替换的次数;
返回值:返回一个子串替换好之后的新的字符串;
实例:
------------------替换所有子串---------------------------- >>> str1 = "http://video.dhlanshan.cn" >>> print(str1.replace("a","A")) http://video.dhlAnshAn.cn -----------------从左到右只替换1次子串------------------ >>> print(str1.replace("a","A",1)) http://video.dhlAnshan.cn
31.rfind(self, sub, start=None, end=None)
说明:返回指定的子串在字符串中最后一次出现的位置,如果没有匹配项则返回-1;也可以说是从右边开始找这个指定的子串;
语法:str.rfind(sub, start=None, end=None)
参数:sub ------> 指定的子串;
start ------> 开始查找的位置,默认为0;
end ------> 结束查找位置,默认为字符串的长度;
返回值:返回字符串最后一次出现的位置,如果没有匹配项则返回-1
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rfind("an")) 20 >>> print(str1.rfind("an",21)) -1
32.rindex(self, sub, start=None, end=None)
说明:返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常,和rfind类似,只不过rfind找不到会返回-1;也可以说是从右边开始找这个指定的子串;
语法:str.rindex(sub, start=None, end=None)
参数:sub ------> 指定的子串;
start ------> 开始查找的位置,默认为0;
end ------> 结束查找位置,默认为字符串的长度;
返回值:返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rindex("an")) 20 ---------------找不到则报错-------------------------- >>> print(str1.rindex("an",21)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: substring not found
33.rjust(self, width, fillchar=None)
说明:返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。
语法:str.rjust(width, fillchar=None)
参数:width ------> 指定填充指定字符后中字符串的总长度;
fillchar -----> 填充的字符,默认为空格;
返回值:返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rjust(30,"-")) -----http://video.dhlanshan.cn
34.rpartition(self, sep)
说明:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串,分隔符从字符串的右边开始查找。
语法:str.rpartition(sep)
参数:sep ----->指定分隔符;
返回值:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rpartition(".")) ('http://video.dhlanshan', '.', 'cn')
35.rsplit(self, sep=None, maxsplit=-1)
说明:分隔字符串,从右侧开始分隔,返回一个将字符串以指定分隔符分隔的列表,从右边开始查找分隔符,默认空格为分隔符;注意,最后列表里是不存在指定的那个分隔符的;
语法:str.rsplit(sep=None, maxsplit=-1)
参数:sep ------> 指定分隔符;
maxsplit ------> 最多分隔的次数,-1表示全部分隔;
返回值:返回一个将字符串以指定分隔符分隔的列表;
实例:
--------------------分隔所有-------------------------------------- >>> str1 = "1 2 3 4 5" >>> print(str1.rsplit(" ",maxsplit=-1)) ['1', '2', '3', '4', '5'] -------------------分隔2次--------------------------------------- >>> print(str1.rsplit(" ",maxsplit=2)) ['1 2 3', '4', '5'] --------------------列表中会删除指定的分隔符----------------- >>> print(str1.rsplit("3",maxsplit=1)) ['1 2 ', ' 4 5']
36.rstrip(self, chars=None)
说明:删除 string 字符串最右边的指定字符(默认为空格);贪婪模式;
语法:str.rstrip(chars=None)
参数:chars ------> 指定的子符;
返回值:返回删除 string 字符串最右边的指定字符后生成的新字符串;
实例:
>>> str1 = "**********今日说法**************" >>> print(str1.rstrip("*")) **********今日说法
37.split(self, sep=None, maxsplit=-1)
说明:分隔字符串,从左侧开始分隔,返回一个将字符串以指定分隔符分隔的列表,从左边开始查找分隔符,默认空格为分隔符;注意,最后列表里是不存在指定的那个分隔符的;
语法:str.rsplit(sep=None, maxsplit=-1)
参数:sep ------> 指定分隔符;
maxsplit ------> 最多分隔的次数,-1表示全部分隔;
返回值:返回一个将字符串以指定分隔符分隔的列表;
实例:
--------------------分隔所有-------------------------------------- >>> str1 = "1 2 3 4 5" >>> print(str1.split(" ",maxsplit=-1)) ['1', '2', '3', '4', '5']
-------------------当分隔符为整个字符串时则返回一个有两个空字符串的元素的列表----------------------
>>> str1 = "1 2 3 4 5"
>>> print(str1.split("1 2 3 4 5",maxsplit=-1))
['', '']
-------------------分隔2次--------------------------------------- >>> print(str1.split(" ",maxsplit=2)) ['1','2','3 4 5'] --------------------列表中会删除指定的分隔符----------------- >>> print(str1.split("3",maxsplit=1)) ['1 2 ', ' 4 5']
38.splitlines(self, keepends=None)
说明:按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
语法:str.splitlines(keepends=None)
参数:keepends -- 在输出结果里是否去掉换行符('\r', '\r\n', \n'),默认为 False,不包含换行符,如果为 True,则保留换行符
返回值:返回一个包含各行作为元素的列表。
实例:
>>> print("abc\n\ndefg\rkl\r\n".splitlines()) ['abc', '', 'defg', 'kl'] >>> print("abc\n\ndefg\rkl\r\n".splitlines(True)) ['abc\n', '\n', 'defg\r', 'kl\r\n']
39.startswith(self, prefix, start=None, end=None)
说明:用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 start 和 end 指定值,则在指定范围内检查。
语法:str.startswith(prefix, start=None, end=None)
参数:prefix ------> 指定的子串;
start -------> 索引开始处;
end --------> 索引结尾处;
返回值:如果检测到字符串则返回True,否则返回False;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.startswith("http")) True >>> print(str1.startswith("video",7)) True >>> print(str1.startswith(":",6,9)) False
40.strip(self, chars=None)
说明:用于移除字符串头尾指定的字符(默认为空格)或字符序列。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
语法:str.strip(chars)
参数:chars -------> 移除字符串头尾指定的字符序列;
返回值:返回移除字符串头尾指定的字符序列生成的新字符串;
实例:
>>> str1 = "**********今*日*说*法**************" >>> print(str1.strip("*")) 今*日*说*法
无敌匹配法:
先看效果:
>>> str1 = "12345654321" >>> print(str1.strip("12")) 3456543 >>> str1 = "12345654312" >>> print(str1.strip("12")) 3456543 >>> str1 = "12345654321" >>> print(str1.strip("125")) 3456543 >>> str1 = "1234565431221" >>> print(str1.strip("12")) 3456543 >>> str1 = "1234565432121" >>> print(str1.strip("12")) 3456543 ----------------------------------------说明-------------------------------- #其实“12”是分为了3个匹配符,分别是"1" "2" "12",这三个匹配符会循环去匹配字符串,直到这三个匹配符一个也匹配不上为止。
41.swapcase(self)
说明:用于对字符串的大小写字母进行转换,小写变大写,大写变小写;
语法:str.swaocase()
返回值:返回大小写字母转换后生成的新字符串;
实例:
>>> str1 = "I Love You" >>> print(str1.swapcase()) i lOVE yOU
42.title(self)
说明:返回"标题化"的字符串,就是说所有单词的首个字母转化为大写,其余字母均为小写;注意,默认是按空格来分单词,也可以是其他特殊字符或数字。
语法:str.title()
返回值:返回"标题化"的字符串,就是说所有单词的首字母都转化为大写。
实例:
>>> str1 = "Life is too short for python" >>> print(str1.title()) Life Is Too Short For Python
使用特殊字符或数字来区分:
>>> str1 = "zjk zjk*zjk&zjk^zjk@,zjk.zjk9zjk8zjk/zjk" >>> print(str1.title()) Zjk Zjk*Zjk&Zjk^Zjk@,Zjk.Zjk9Zjk8Zjk/Zjk
43.translate(self, table)
说明:根据由maketrans函数生成的对照表table完成字符替换;
语法:str.tarnslate(table)
参数:table ---- 对照表,是由maketrans函数生成;
返回值:返回翻译后的字符串;
实例:
>>> table = str.maketrans("zjk","666") >>> str = "zjkqwert" >>> print(str.translate(table)) 666qwert
44.upper(self)
说明:将字符串中的小写字母转为大写字母;
语法:str.upper()
返回值:返回小写字母转为大写字母的字符串;
实例:
>>> str1 = "Life is too short for python" >>> print(str1.upper()) LIFE IS TOO SHORT FOR PYTHON
45.zfill(self, width)
说明:返回指定长度的字符串,原字符串右对齐,前面填充0,若指定长度小于原字符串长度,则返回原字符串;
语法:str.zfill(width)
参数:width -------> 指定字符串的长度。原字符串右对齐,前面填充0;
返回值:返回指定长度的字符串;
实例:
>>> str = "zjkqwert" >>> print(str.zfill(10)) 00zjkqwert >>> print(str.zfill(6)) zjkqwert

