

对于ESP、EBP寄存器的理解
https://blog.csdn.net/u014421422/article/details/79471396
esp是栈指针,是cpu机制决定的,push、pop指令会自动调整esp的值;
ebp只是存取某时刻的esp,这个时刻就是进入一个函数内后,cpu会将esp的值赋给ebp,此时就可以通过ebp对栈进行操作,比如获取函数参数,局部变量等,实际上使用esp也可以;
既然使用esp也可以,那么为什么要设定ebp呢?
答案是为了方便程序员。
因为esp在函数运行时会不断的变化,所以保存一个一进入某个函数的esp到ebp中会方便程序员访问参数和局部变量,而且还方便调试器分析函数调用过程中的堆栈情况。前面说了,这个ebp不是必须要有的,你非要使用esp来访问函数参数和局部变量也是可行的,只不过这样会麻烦一些。
这里函数调用约定使用的是_stdcall
通过一段程序理解esp和ebp:

main() { //执行test前 print(int p1,int p2); //执行test后 }
分析下上面程序的调用原理,假设执行print前esp=Q:
push p2; //函数参数p2入栈,esp=Q-4H push p1; //函数参数p1入栈,esp=Q-8H call print; //函数返回地址入栈,esp=Q-0CH //现在进入print内,做些准备工作: push ebp; //保护先前ebp指针,ebp入栈,esp=Q-10H mov ebp,esp; //设置ebp等于当前的esp // 此时,ebp+0CH=Q-4H,即p2的位置 // 同样,ebp+08H=Q-8H,即p1的位置 // 下面是print内的一些操作: sub esp,20H; //设置长度为10H大小的局部变量空间,esp=Q-20H // ... ... // 一系列操作 // ... ... add esp,20H; //释放局部变量空间,esp=Q-10H pop ebp; //出栈,恢复原先的ebp的值,esp=Q-0CH ret 8; //ret返回,弹出先前入栈的返回地址,esp=Q-08H,后面加操作数8H为平衡堆栈 // 之后,弹出函数参数,esp=Q,恢复执行print函数前的堆栈;
图示,注意栈在内存中的生长方向是逆向:

执行push p2;前,esp=Q;
执行push p2;过程中,esp-=4H,p2入栈;
执行push p2;后,esp=Q-4H;
因为参数传递和汇编语言有很大联系,之后会出现较多x86汇编代码。
该文会先讲一下x86的堆栈参数传递过程,然后再分析C/C++子函数是怎样通过堆栈传递参数的。
注:汇编语言的过程和C/C++的子函数是一回事。
寄存器参数,存储器参数和堆栈参数都可以用于x86汇编乃至其他汇编语言传递参数的方式。但C/C++在编译时,编译器会对子函数使用堆栈参数传递方式。
三种参数传递方式对比:
1、寄存器参数
mov eal,4 call Proc_using_eal ...
2、存储器参数
.data temp DB ? .code ... mov temp,4 call Proc_using_temp
3、堆栈参数
push 4 call Proc_using_stack
1、x86堆栈参数传递过程
考虑一个过程add_num,该过程有两个输入参数,一个输出参数。其功能是将两个输入参数求和并将其结果输出。下面这个例子中使用堆栈将3, 4两个参数输入到add_num中。
push 3 push 4 call add_num
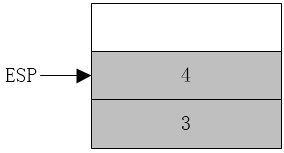
执行call指令前,堆栈如下:
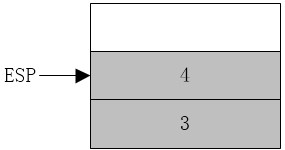
其中ESP为x86CPU使用的堆栈指针,每进行一次入栈操作,ESP要减4(32位CPU)(图上堆栈向上地址减小,向下地址增加)
明显的是,add_num只需要把堆栈中相应的变量取出来使用就可以了。堆栈参数传递的确也是这么做,但是却要稍稍费事一点。
首先给出add_num过程的程序
add_num proc push ebp mov ebp,esp mov eax,[ebp+8] add eax,[ebp+12] pop ebp ret add_num endp
之前笔者给出的堆栈是CPU执行call指令前的结果,接下来从开始执行call指令一步一步分析堆栈的变化情况。
(1)call add_num
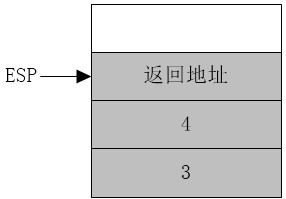
执行call add_num时,ESP减4后将add_num过程的返回地址压入堆栈,即当前指令指针EIP的值(该值为主程序中call指令的下一条指令(不是push ebp)的地址)
(2)
push ebp mov ebp,esp mov eax,[ebp+8] add eax,[ebp+12]
此时已经进入add_num过程内部
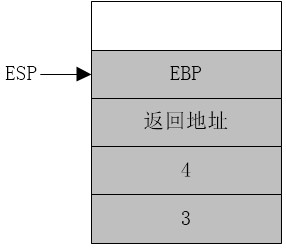
这一步是为了将esp的值赋予ebp。而将ebp压入堆栈是为了保护ebp,在add_num过程结束后还要恢复ebp的值。
此时esp指向堆栈中的ebp,而将esp赋予ebp后,ebp便指向了堆栈中自己被保护的值。此时ebp的主要作用是为参数读取提供绝对地址。比如参数4比ebp所在地址高8Byte(堆栈一个单元是4Byte),则过程中要使用参数4时,使用基址-偏移量寻址即可,即[ebp+8]。
当然这里也可以使用esp达到相同的效果,但是这个例子没有局部变量。若子过程中有局部变量(局部变量也存放在堆栈里),采用ebp要方便很多。
(3)pop ebp
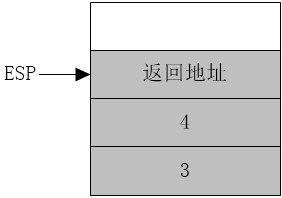
此时ebp弹出,ebp恢复调用前的值
(4)ret
最后弹出返回地址,程序返回到主程序中,并执行下一条指令
以上为整个堆栈参数传递过程。
这里有几个需要注意的点:
(1)、堆栈帧到底是什么
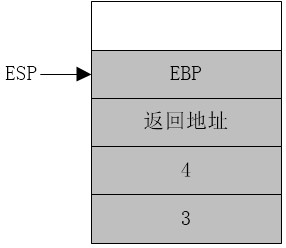
堆栈帧(stack frame)(或活动记录(activation record))是一块堆栈保留区域,用于存放被传递的实际参数、子程序的返回值、局部变量以及被保存的寄存器。
实际上堆栈帧就相当于子函数的缓存,当子函数使用的堆栈个数最大时,其所拥有的所有部分构成了这个函数的堆栈帧。
以add_num过程为例,其堆栈帧如下图灰色部分所示。
(2)、堆栈帧为什么叫做堆栈帧
“堆栈”很好理解,而“帧”的概念在上面那个例子中的确很难搞通。不久后笔者会分析递归函数中的堆栈帧增消的现象,那个时候“帧”这个概念体现得淋漓尽致。
(3)、输入参数3和4留在堆栈里没有释放是可以的吗
上面的例子并没有释放参数4和3,只是为了演示,实际上一定会有相应的代码去释放它。子函数的堆栈帧是包含其输入堆栈变量的,当退出子函数时,其所有的堆栈帧必须被完全释放,否则堆栈就会变得混乱。
释放参数涉及两种子函数调用标准,一种是STDCALL标准,一种是C标准。两种在参数的堆栈传递细节几乎完全相同,不同的是释放参数的方式。
根据两个标准重新改写add_num过程:
STDCALL调用规范 add_num proc push ebp mov ebp,esp mov eax,[ebp+8] add eax,[ebp+12] pop ebp ret 8 add_num endp
11. C调用规范
... push 3 push 4 call add_num add esp,8
两种方式的核心思想就是修改esp,使esp指向堆栈参数3和4所在位置的前一个堆栈。但是STDCALL调用规范是在过程内部修改esp(ret 8为将堆栈中返回地址弹出到EIP后,再将ESP加8);C调用规范是在子过程外部,在主调过程修改esp。
另引用这两种方式的优缺点:
STDCALL不仅减少了子程序调用产生的代码量(减少了一条指令),还保证了调用程序永远不会忘记清除堆栈。另一方面,C调用规范允许子程序声明不同数量的参数,主调程序可以决定传递多少个参数。C语言的printf函数就是一个例子


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决