

(十三)子查询
子查询的语法很简单,就是select语句的嵌套使用
SQL> select * from emp where sal>(select sal from emp where ename='SCOTT'); EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO ---------- ---------- --------- ---------- -------------- ---------- ---------- ---------- 7839 KING PRESIDENT 17-11月-81 5000 10 已用时间: 00: 00: 00.02 SQL>
子查询的语法格式:
select select_list from table where exper operator (select select_list from table);
注意:
1.主查询和子查询可以是不同的表,只要子查询的结果,主查询可以使用就可以
2.主查询的select, where, having, from 后都可以放置子查询
3.不可以在group by 后放置子查询语句
4.强调:在from 后放置的子查询(***) ,from后放置的是一个集合(表,查询的结果)
5一般先执行子查询(内查询),再执行主查询(外查询),但相关子查询除外.
6.单行操作符对应单行子查询,多行操作符对应多行子查询
1.主,子查询在不同的表之间进行
查询部门名称是‘SALES’的员工信息
SQL> select * from emp e where e.deptno = (select d.deptno from dept d where d.dname='SALES'); EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO ---------- ---------- --------- ---------- -------------- ---------- ---------- ---------- 7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30 7521 WARD SALESMAN 7698 22-2月 -81 1250 500 30 7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400 30 7698 BLAKE MANAGER 7839 01-5月 -81 2850 30 7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30 7900 JAMES CLERK 7698 03-12月-81 950 30 已选择6行。 已用时间: 00: 00: 00.05 SQL>
使用多表查询
SQL> select e.* from emp e,dept d where e.deptno=d.deptno and d.dname='SALES'; EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO ---------- ---------- --------- ---------- -------------- ---------- ---------- ---------- 7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30 7521 WARD SALESMAN 7698 22-2月 -81 1250 500 30 7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400 30 7698 BLAKE MANAGER 7839 01-5月 -81 2850 30 7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30 7900 JAMES CLERK 7698 03-12月-81 950 30 已选择6行。 已用时间: 00: 00: 00.06 SQL>
理论上,即可以使用子查询右可以使用多表查询,尽量使用多表查询,子查询有两次from
不同的数据库处理数据的方式不尽相同,如orcale,子查询的地位比较重要,,做了深入的优化,有可能实际看到的结果是子查询快于多表查询
2.主查询的select, where, having, from 后都可以放置子查询
子查询可以放置select 语句之后,但,要求该子查询必须是单行子查询(该子查询本身只返回一条记录,2+叫多行子查询)
SQL> select empno,ename,deptno,(select dname from dept where deptno=10) from emp; EMPNO ENAME DEPTNO (SELECTDNAMEFR ---------- ---------- ---------- -------------- 7369 SMITH 20 ACCOUNTING 7499 ALLEN 30 ACCOUNTING 7521 WARD 30 ACCOUNTING 7566 JONES 20 ACCOUNTING 7654 MARTIN 30 ACCOUNTING 7698 BLAKE 30 ACCOUNTING 7782 CLARK 10 ACCOUNTING 7788 SCOTT 20 ACCOUNTING 7839 KING 10 ACCOUNTING 7844 TURNER 30 ACCOUNTING 7876 ADAMS 20 ACCOUNTING 7900 JAMES 30 ACCOUNTING 7902 FORD 20 ACCOUNTING 7934 MILLER 10 ACCOUNTING 已选择14行。 已用时间: 00: 00: 00.06 SQL> select * from dept; DEPTNO DNAME LOC ---------- -------------- ------------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON 已用时间: 00: 00: 00.02 SQL>
3.from后面放置的子查询(**)
表代表一个数据的集合,查询结果(SQL)语句本身也代表一个集合
用子查询来查询员工的姓名,薪水,年薪
SQL> select * from (select ename,sal,sal*12 from emp); ENAME SAL SAL*12 ---------- ---------- ---------- SMITH 800 9600 ALLEN 1600 19200 WARD 1250 15000 JONES 2975 35700 MARTIN 1250 15000 BLAKE 2850 34200 CLARK 2450 29400 SCOTT 3000 36000 KING 5000 60000 TURNER 1500 18000 ADAMS 1100 13200 JAMES 950 11400 FORD 3000 36000 MILLER 1300 15600 已选择14行。 已用时间: 00: 00: 00.08
将select语句放在from后面,表示将select语句的结果当做表来查看,,这种查询方式在orcale中使用比较频繁
4.一般先执行子查询(内查询),再执行主查询(外查询),但相关子查询除外.
相关子查询的概念:将主查询的某个值,作为参数传递给子查询
SQL> ed 已写入 file afiedt.buf 1 select e.empno,e.ename,e.sal,(select avg(sal) from emp where e.deptno=deptno) avg_sal from emp e 2* where e.sal>(select avg(sal) from emp where e.deptno=deptno) SQL> / EMPNO ENAME SAL AVG_SAL ---------- ---------- ---------- ---------- 7499 ALLEN 1600 1566.66667 7566 JONES 2975 2175 7698 BLAKE 2850 1566.66667 7788 SCOTT 3000 2175 7839 KING 5000 2916.66667 7902 FORD 3000 2175 已选择6行。 已用时间: 00: 00: 00.06 SQL>
5.一般不在子查询中使用order by
但,在Top-N分析问题时,必须使用order by
找到员工表中工资最高的前三名, 要求按如下格式输出:
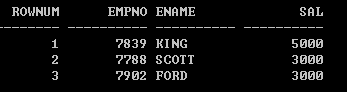
补充知识:rownum 行号(伪列)
SQL> select rownum,empno,ename,sal from emp; ROWNUM EMPNO ENAME SAL ---------- ---------- ---------- ---------- 1 7369 SMITH 800 2 7499 ALLEN 1600 3 7521 WARD 1250 4 7566 JONES 2975 5 7654 MARTIN 1250 6 7698 BLAKE 2850 7 7782 CLARK 2450 8 7788 SCOTT 3000 9 7839 KING 5000 10 7844 TURNER 1500 11 7876 ADAMS 1100 12 7900 JAMES 950 13 7902 FORD 3000 14 7934 MILLER 1300 已选择14行。 已用时间: 00: 00: 00.08
借助行号将薪水降序排列。前三条即是我们想要的内容。 SQL> select * from emp order by sal desc 但问题是如何取出前三行。 SQL> select * from emp where rownum <= 3 order by sal 发现取出的结果不正确。
SQL> select rownum,empno,ename,sal from emp where rownum <= 3 order by sal desc; ROWNUM EMPNO ENAME SAL ---------- ---------- ---------- ---------- 2 7499 ALLEN 1600 3 7521 WARD 1250 1 7369 SMITH 800 已用时间: 00: 00: 00.03
行号rownum需要注意的问题: 1. rownum永远按照默认的顺序生成。 SQL> select rownum, empno, ename, sal from emp order by sal desc ——发现行号是跟着行走的。查询结果顺序变了,行号依然固定在原来的行上。 行号始终使用默认顺序:select * from emp所得到的顺序,没有排序,没有分组等。 只要能使行号随着重新排序,发生改变,那么取前三条记录,就是我们想要的结果。 2. rownum只能使用<, <=符号,不能使用>,>=符号。 想将现有的表进行分页。1-4第一页,5-8第二页…… SQL> select rownum, empno, ename, sal from emp where rownum >=1 and rownum<=4 SQL> select rownum, empno, ename, sal from emp where rownum >=5 and rownum<=8 执行,发现结果:未选定行。原因是rownum不能使用>=符号。Where永远为假。 与行号生成的机制有关:Oracle中的行号永远从1开始——取了1才能取2,取了2才能取3,…… <=8可以是因为1234567挨着取到,而>=5不行,因为没有1234,不能直接取5。
SQL> select rownum,empno,ename,sal from (select empno,ename,sal from emp order by sal desc) where rownum<=3; ROWNUM EMPNO ENAME SAL ---------- ---------- ---------- ---------- 1 7839 KING 5000 2 7788 SCOTT 3000 3 7902 FORD 3000 已用时间: 00: 00: 00.03 SQL>
1 select * from 2 (select rownum r,empno,ename,sal from emp where rownum<=8) 3* where r >=5 SQL> / R EMPNO ENAME SAL ---------- ---------- ---------- ---------- 5 7654 MARTIN 1250 6 7698 BLAKE 2850 7 7782 CLARK 2450 8 7788 SCOTT 3000 已用时间: 00: 00: 00.05 SQL>
6.单行操作符对应单行子查询,多行操作符对应多行子查询
多行操作符
IN 等于列表中的任意一个
NOT IN
ALL 和子查询返回的任意一个值比较
ANY 和子查询返回的每一个值比较
查询薪水比30号部门任意一个员工高的员工信息
SQL> ed 已写入 file afiedt.buf 1 select * from emp 2 where sal>ANY( 3* select sal from emp where deptno=30) SQL> / EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO ---------- ---------- --------- ---------- -------------- ---------- ---------- ---------- 7839 KING PRESIDENT 17-11月-81 5000 10 7902 FORD ANALYST 7566 03-12月-81 3000 20 7788 SCOTT ANALYST 7566 19-4月 -87 3000 20 7566 JONES MANAGER 7839 02-4月 -81 2975 20 7698 BLAKE MANAGER 7839 01-5月 -81 2850 30 7782 CLARK MANAGER 7839 09-6月 -81 2450 10 7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30 7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30 7934 MILLER CLERK 7782 23-1月 -82 1300 10 7521 WARD SALESMAN 7698 22-2月 -81 1250 500 30 7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400 30 7876 ADAMS CLERK 7788 23-5月 -87 1100 20 已选择12行。 SQL> ed 已写入 file afiedt.buf 1 select * from emp 2 where sal>ALL( 3* select sal from emp where deptno=30) SQL> / EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO ---------- ---------- --------- ---------- -------------- ---------- ---------- ---------- 7566 JONES MANAGER 7839 02-4月 -81 2975 20 7788 SCOTT ANALYST 7566 19-4月 -87 3000 20 7902 FORD ANALYST 7566 03-12月-81 3000 20 7839 KING PRESIDENT 17-11月-81 5000 10 SQL>
找到emp表中薪水大于本部门平均薪水的员工
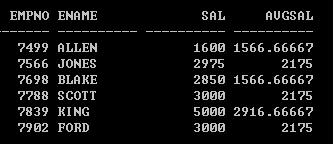
SQL> ed 已写入 file afiedt.buf 1 select e.empno,e.ename,e.sal,d.avg_sal from emp e, 2 (select deptno,avg(sal) avg_sal from emp group by deptno) d // 别名,相当于多表查询 3* where e.deptno=d.deptno and e.sal>d.avg_sal SQL> / EMPNO ENAME SAL AVG_SAL ---------- ---------- ---------- ---------- 7698 BLAKE 2850 1566.66667 7499 ALLEN 1600 1566.66667 7902 FORD 3000 2175 7788 SCOTT 3000 2175 7566 JONES 2975 2175 7839 KING 5000 2916.66667 已选择6行。 已用时间: 00: 00: 00.07 SQL>
统计每年入职的 员工数
SQL> ed 已写入 file afiedt.buf 1 select count(*) Total, 2 sum(decode(to_char(hiredate,'yyyy'),'1981',1,0)) "1981" , 3 sum(decode(to_char(hiredate,'yyyy'),'1980',1,0)) "1980" , 4 sum(decode(to_char(hiredate,'yyyy'),'1982',1,0)) "1982" , 5 sum(decode(to_char(hiredate,'yyyy'),'1987',1,0)) "1987" 6* from emp SQL> / TOTAL 1981 1980 1982 1987 ---------- ---------- ---------- ---------- ---------- 14 10 1 1 2
注意:字符串是数字,必须加“”


