Nginx 工作原理
Nginx 工作原理
Nginx由内核和模块组成。
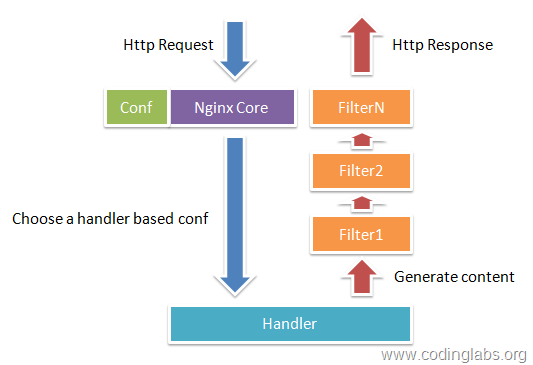
Nginx本身做的工作实际很少,当它接到一个HTTP请求时,它仅仅是通过查找配置文件将此次请求映射到一个location block,而此location中所配置的各个指令则会启动不同的模块去完成工作,因此模块可以看做Nginx真正的劳动工作者。通常一个location中的指令会涉及一个handler模块和多个filter模块(当然,多个location可以复用同一个模块)。handler模块负责处理请求,完成响应内容的生成,而filter模块对响应内容进行处理。
用户根据自己的需要开发的模块都属于第三方模块。正是有了这么多模块的支撑,Nginx的功能才会如此强大。
Nginx的模块从结构上分为核心模块、基础模块和第三方模块:
- 核心模块:HTTP模块、EVENT模块和MAIL模块
- 基础模块:HTTP Access模块、HTTP FastCGI模块、HTTP Proxy模块和HTTP Rewrite模块,
- 第三方模块:HTTP Upstream Request Hash模块、Notice模块和HTTP Access Key模块。
Nginx的模块从功能上分为如下三类:
- Handlers(处理器模块)。此类模块直接处理请求,并进行输出内容和修改headers信息等操作。Handlers处理器模块一般只能有一个。
- Filters (过滤器模块)。此类模块主要对其他处理器模块输出的内容进行修改操作,最后由Nginx输出。
- Proxies (代理类模块)。此类模块是Nginx的HTTP Upstream之类的模块,这些模块主要与后端一些服务比如FastCGI等进行交互,实现服务代理和负载均衡等功能。
Nginx进程模型
Nginx默认采用多进程工作方式,Nginx启动后,会运行一个master进程和多个worker进程。其中master充当整个进程组与用户的交互接口,同时对进程进行监护,管理worker进程来实现重启服务、平滑升级、更换日志文件、配置文件实时生效等功能。worker用来处理基本的网络事件,worker之间是平等的,他们共同竞争来处理来自客户端的请求。
nginx的进程模型如图所示:
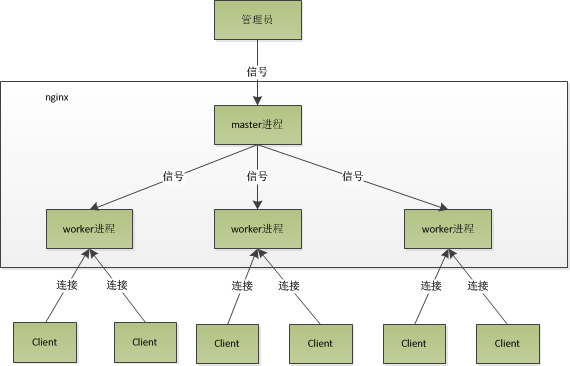
在创建master进程时,先建立需要监听的socket(listenfd),然后从master进程中fork()出多个worker进程,如此一来每个worker进程多可以监听用户请求的socket。一般来说,当一个连接进来后,所有在Worker都会收到通知,但是只有一个进程可以接受这个连接请求,其它的都失败,这是所谓的惊群现象。nginx提供了一个accept_mutex(互斥锁),有了这把锁之后,同一时刻,就只会有一个进程在accpet连接,这样就不会有惊群问题了。
先打开accept_mutex选项,只有获得了accept_mutex的进程才会去添加accept事件。nginx使用一个叫ngx_accept_disabled的变量来控制是否去竞争accept_mutex锁。ngx_accept_disabled = nginx单进程的所有连接总数 / 8 -空闲连接数量,当ngx_accept_disabled大于0时,不会去尝试获取accept_mutex锁,ngx_accept_disable越大,于是让出的机会就越多,这样其它进程获取锁的机会也就越大。不去accept,每个worker进程的连接数就控制下来了,其它进程的连接池就会得到利用,这样,nginx就控制了多进程间连接的平衡。
每个worker进程都有一个独立的连接池,连接池的大小是worker_connections。这里的连接池里面保存的其实不是真实的连接,它只是一个worker_connections大小的一个ngx_connection_t结构的数组。并且,nginx会通过一个链表free_connections来保存所有的空闲ngx_connection_t,每次获取一个连接时,就从空闲连接链表中获取一个,用完后,再放回空闲连接链表里面。一个nginx能建立的最大连接数,应该是worker_connections * worker_processes。当然,这里说的是最大连接数,对于HTTP请求本地资源来说,能够支持的最大并发数量是worker_connections * worker_processes,而如果是HTTP作为反向代理来说,最大并发数量应该是worker_connections * worker_processes/2。因为作为反向代理服务器,每个并发会建立与客户端的连接和与后端服务的连接,会占用两个连接。
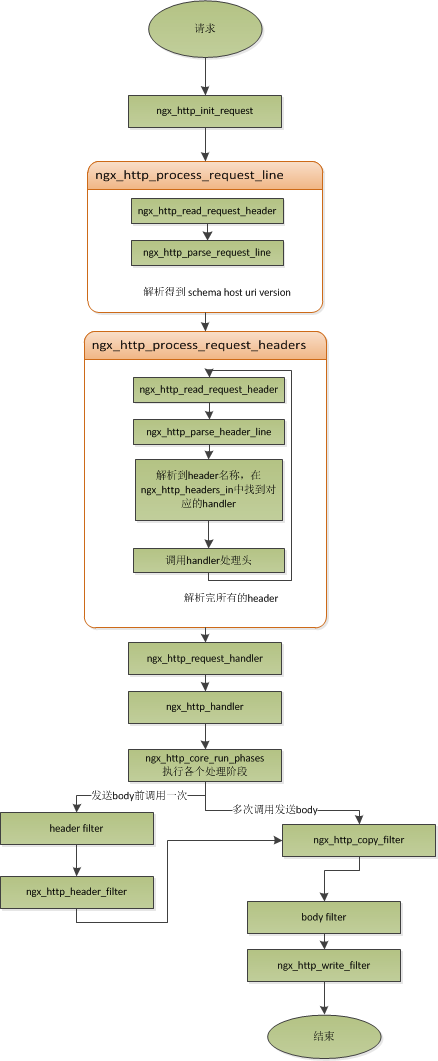
Nginx处理HTTP请求流程
http请求是典型的请求-响应类型的的网络协议。http是文件协议,所以我们在分析请求行与请求头,以及输出响应行与响应头,往往是一行一行的进行处理。通常在一个连接建立好后,读取一行数据,分析出请求行中包含的method、uri、http_version信息。然后再一行一行处理请求头,并根据请求method与请求头的信息来决定是否有请求体以及请求体的长度,然后再去读取请求体。得到请求后,我们处理请求产生需要输出的数据,然后再生成响应行,响应头以及响应体。在将响应发送给客户端之后,一个完整的请求就处理完了。
处理流程图:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通